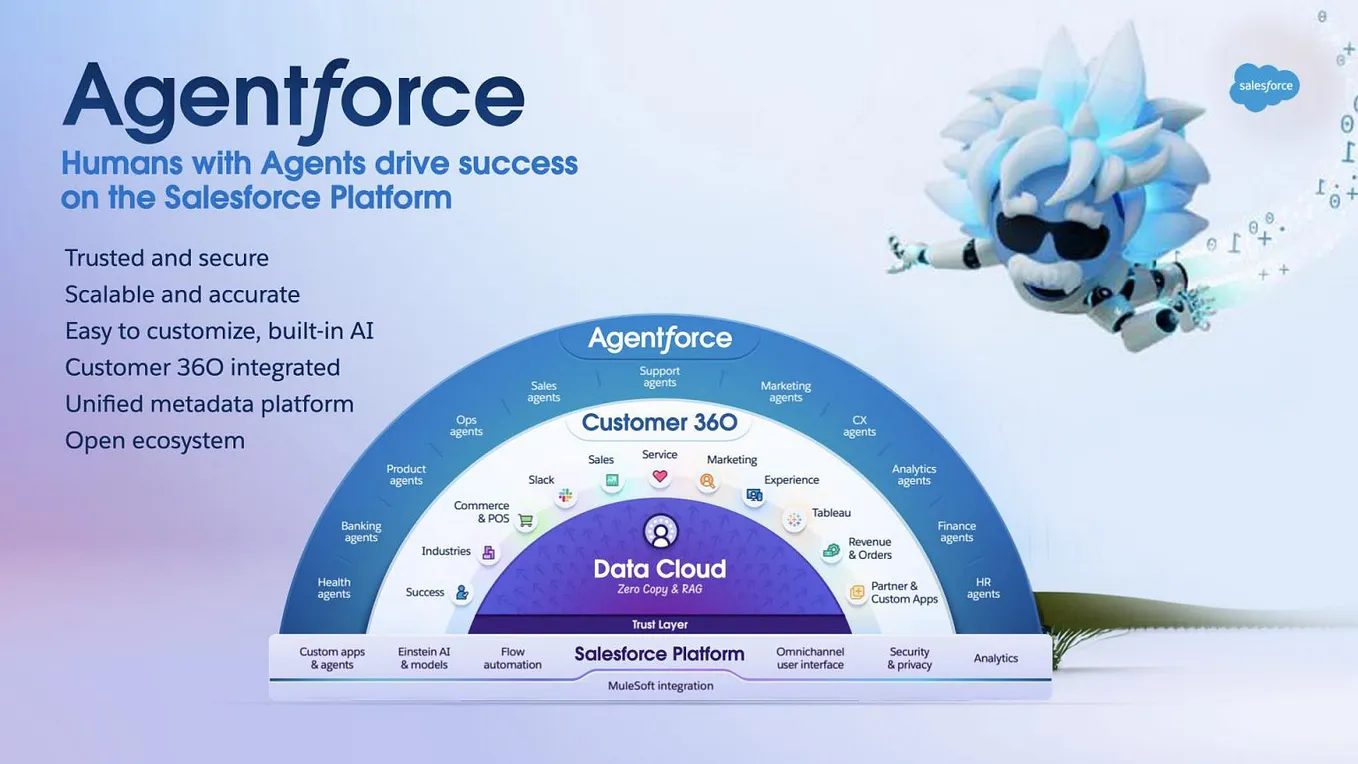
Nvidia published validated blueprints for AI data centers across three tiers, from 4-node RTX PRO clusters to 128-node NVL72 racks. The Enterprise Reference Architectures target agentic AI, physical AI, and trillion-parameter model training with specific design points.
Key facts
- Three tiers: RTX PRO (16-32 nodes), HGX (32-128 nodes), NVL72 (4-8 racks).
- NVL72 targets trillion-parameter models with exascale per rack.
- HGX claims up to 15x higher token throughput via Spectrum-X networking.
- RTX PRO optimized for PCIe environments in power-constrained data centers.
- Nvidia did not disclose pricing or specific power consumption figures.
Nvidia's Enterprise Reference Architectures (Enterprise RAs) provide validated, repeatable infrastructure designs for deploying AI factories in enterprise data centers. The documentation covers three distinct configurations, each targeting specific workload scales and hardware tiers.
Three Tiers, Three Use Cases
The RTX PRO AI Factory targets space- and power-constrained data centers using PCIe-based NVIDIA RTX PRO Servers. It offers 16- and 32-node design points optimized for generative AI, agentic AI, data analytics, visual computing, and engineering simulation. This is the entry point for enterprises not ready for full-scale HGX deployments.
The HGX AI Factory scales to 32-, 64-, and 128-node configurations using NVIDIA HGX systems with Spectrum-X networking. The rail-optimized design claims up to 15x higher token throughput versus prior generations, targeting multi-node training and inference at scale.
The NVL72 AI Factory is the flagship: designed for trillion-parameter models, delivering exascale computing within a single rack. Deployment centers on four- and eight-rack configurations, built on a flexible, rail-optimized network architecture.
The Unique Take: Nvidia Is Codifying the Data Center Playbook
Nvidia's move to publish these reference architectures is a structural shift. Previously, enterprises relied on systems integrators or cloud providers to design AI clusters. By releasing validated, repeatable blueprints — including networking, observability, and software stacks — Nvidia is commoditizing the design phase and making AI factory deployment a turnkey operation. This mirrors how VMware standardized virtualized infrastructure two decades ago. The goal: remove the integration friction that slows enterprise AI adoption, locking customers into Nvidia's hardware ecosystem before AMD or custom ASIC alternatives mature.

Networking and Observability as Moat
The reference architectures include high-speed east-west and north-south networking specs and observability tools — not just compute. Nvidia's Spectrum-X networking is mandatory for the HGX and NVL72 designs, creating a full-stack dependency. Enterprises that follow these blueprints will find it costly to swap in non-Nvidia networking or storage components later.

Context: Recent Nvidia Infrastructure Moves
This release follows Nvidia's May 2026 partnership with Invenergy and Emerald AI to build flexible AI factories [per the company's blog post], and the open-sourcing of MRC — the RDMA protocol powering OpenAI's Blackwell clusters — on May 6, 2026. The reference architectures complement these efforts by providing the deployment playbook for the hardware those protocols run on.

Limitations
Nvidia did not disclose pricing for any of the configurations, nor specific power consumption figures beyond the general claim of efficiency. The 15x token throughput improvement for HGX lacks a baseline comparison — whether against prior HGX generations or competitor systems. The reference architectures are design documents, not turnkey products; enterprises still need to source hardware from certified partners.
What to watch
Watch for partner certifications from Dell, HPE, and Supermicro — the first validated RTX PRO and HGX systems should ship within 90 days. Also track whether AMD or Intel announce competing reference architectures for their GPU lines, which would validate Nvidia's playbook strategy.
[Updated 08 May via gn_gpu_cluster]
ServeTheHome reports that Nvidia's Spectrum-X MRC is a custom RDMA transport protocol already powering frontier gigascale AI deployments [per ServeTheHome]. This detail was not in the original article, which only mentioned MRC being open-sourced. MRC is the underlying protocol that enables the claimed 15x token throughput improvement in HGX configurations, making the reference architectures' networking claims more concrete.