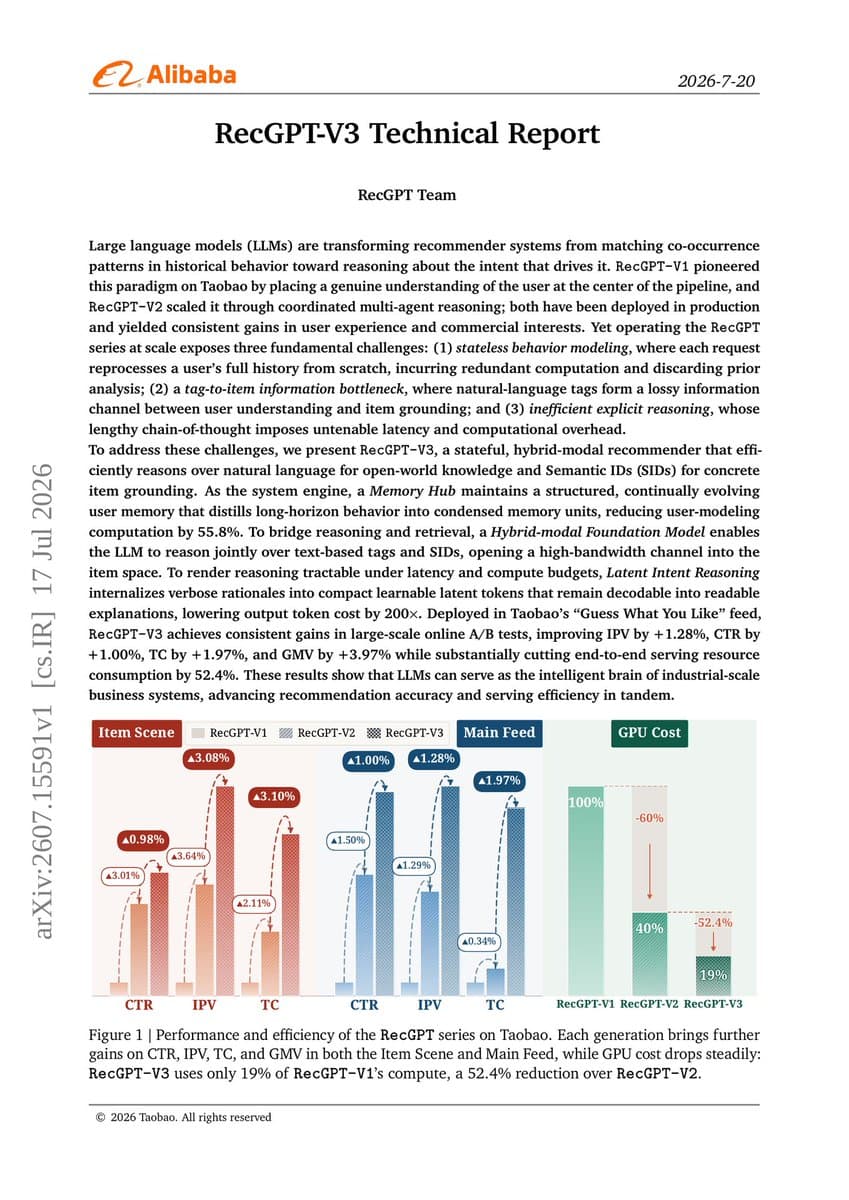
Key Takeaways
- Nvidia demonstrated training a billion-parameter language model using zero gradients or backpropagation, eliminating FP32 weights entirely.
- This could dramatically reduce memory and compute costs for LLM training.
What Happened

Nvidia has trained a billion-parameter large language model without using gradient descent, backpropagation, or full-precision (FP32) weights. The announcement, made via a social media post from the AI researcher community, points to a fundamentally different approach to neural network training that could sidestep many of the memory and compute bottlenecks that dominate current LLM development.
The post does not specify the exact method used, but the absence of backpropagation and gradients suggests a forward-forward or similar local learning algorithm, possibly combined with novel weight update rules. The elimination of FP32 weights implies the model was trained entirely in lower precision (e.g., FP8, FP4, or even binary formats), which would drastically reduce memory footprint.
Why It Matters
Current LLM training relies on backpropagation — computing gradients through the entire computational graph, which requires storing intermediate activations and performing backward passes. This is memory-intensive and scales poorly to large models. A method that bypasses backpropagation could:
- Reduce memory requirements by eliminating the need to store activations for gradient computation
- Enable training on consumer GPUs by lowering memory barriers
- Simplify distributed training by removing the need for synchronized gradient updates
- Potentially reduce energy consumption by avoiding the backward pass altogether
The billion-parameter scale is significant: prior work on gradient-free training (e.g., forward-forward algorithm, synthetic gradients) has been limited to small models (under 100M parameters). Scaling to 1B parameters suggests the method is practical for production-scale models.
Context
The approach aligns with a growing body of research exploring alternatives to backpropagation, including:
- Forward-Forward Algorithm (Hinton, 2022): Replaces forward-backward passes with two forward passes — one for positive data, one for negative data.
- Synthetic Gradients (DeepMind, 2016): Uses a learned model to predict gradients without backprop.
- Zero-Shot Learning Without Gradients: Some recent work has shown that random weight perturbations can achieve competitive results for certain tasks.
Nvidia's result is notable because it achieves this at a scale where gradient-based methods are currently the only proven approach. If the method is validated and released, it could open new avenues for training large models on limited hardware.
What We Don't Know Yet

The source is a brief social media post without a paper, benchmarks, or code. Key missing details include:
- Exact method: Forward-forward? Synthetic gradients? Something entirely new?
- Performance metrics: How does the trained model compare to a backprop-trained model of the same size on standard benchmarks (MMLU, HumanEval, etc.)?
- Training cost: How many GPU-hours were required compared to standard training?
- Convergence quality: Does the model match the performance of gradient-trained models, or is there a quality gap?
- Reproducibility: Is the method open-sourced, or is this a proprietary demonstration?
What This Means in Practice
If Nvidia's method is reproducible and scales further, it could dramatically lower the barrier to entry for LLM training. Researchers and organizations currently priced out of GPU clusters could train billion-parameter models on a single high-end GPU. However, the quality trade-off (if any) needs to be quantified before practitioners can adopt it.
gentic.news Analysis
This development comes amid a broader industry push to reduce the cost of LLM training. We've previously covered Meta's work on 1-bit large language models and Microsoft's research on FP8 training, both of which aim to lower the memory and compute requirements of large models. Nvidia's gradient-free approach represents a more radical departure — not just reducing precision but eliminating the core training algorithm itself.
The timing is notable: Nvidia has been investing heavily in alternative training paradigms, including their work on neural architecture search and pruning. This announcement suggests they may have found a viable path to training at scale without backpropagation, which could give them a competitive advantage in the hardware-software stack for AI training.
However, the lack of a published paper or benchmarks makes it difficult to assess the true significance. The AI community will likely demand rigorous evaluation before accepting this as a practical alternative to backpropagation. If the method is validated, it could reshape how we think about training large models — potentially making LLM training accessible to a much wider audience.
Frequently Asked Questions
Can this method train models as accurate as backpropagation?
Not yet proven. The source does not provide benchmark comparisons. Prior gradient-free methods (e.g., forward-forward) have shown quality gaps compared to backpropagation, especially on complex tasks. Nvidia's billion-parameter result is promising but requires independent verification.
What hardware is needed for this training method?
The elimination of FP32 weights and backpropagation suggests much lower memory requirements. A billion-parameter model might fit on a single high-end GPU (e.g., H100 with 80GB VRAM) using FP8 or lower precision, compared to requiring multiple GPUs with standard backpropagation.
Is this related to Nvidia's hardware products?
Possibly. Nvidia's Hopper and Blackwell architectures support FP8 and lower-precision computation. A training method that operates entirely in low precision could be optimized for these GPUs, potentially giving Nvidia a hardware-software advantage.
When will more details be available?
Nvidia has not announced a paper or release date. The community is watching for a technical report or open-source code. Given the significance, a publication at a major conference (NeurIPS, ICML, etc.) is likely within the next 6-12 months.