OpenAI is preparing a general-purpose LLM for imminent release, according to a message from an OpenAI staffer cited by @kimmonismus on X. The model shows dramatic gains from increased test-time compute, even on math problems, without task-specific training.
Key facts
- OpenAI staffer cited by @kimmonismus on X
- Model not pushed to limit on open problems
- Focus on quick release for broad access
- General-purpose LLM improves with test-time compute
- No math-specific training required for gains
OpenAI is aiming for a release of their upcoming general-purpose LLM, per an internal message cited by @kimmonismus on X. The staffer wrote: "We have not pushed this model to the limit on open problems. Our focus is to get it out quickly so that everyone can use it for themselves."
The key technical claim — that a general-purpose LLM, not specifically trained for math or this problem, appears to get dramatically better simply by using more test-time compute — points to a scaling strategy distinct from the compute-heavy fine-tuning or specialized models like OpenAI's o1 (formerly Q*).
Key Takeaways
- OpenAI is releasing a general-purpose LLM that improves with test-time compute, per an internal message.
- The model shows math gains without specialized training.
What test-time compute scaling means
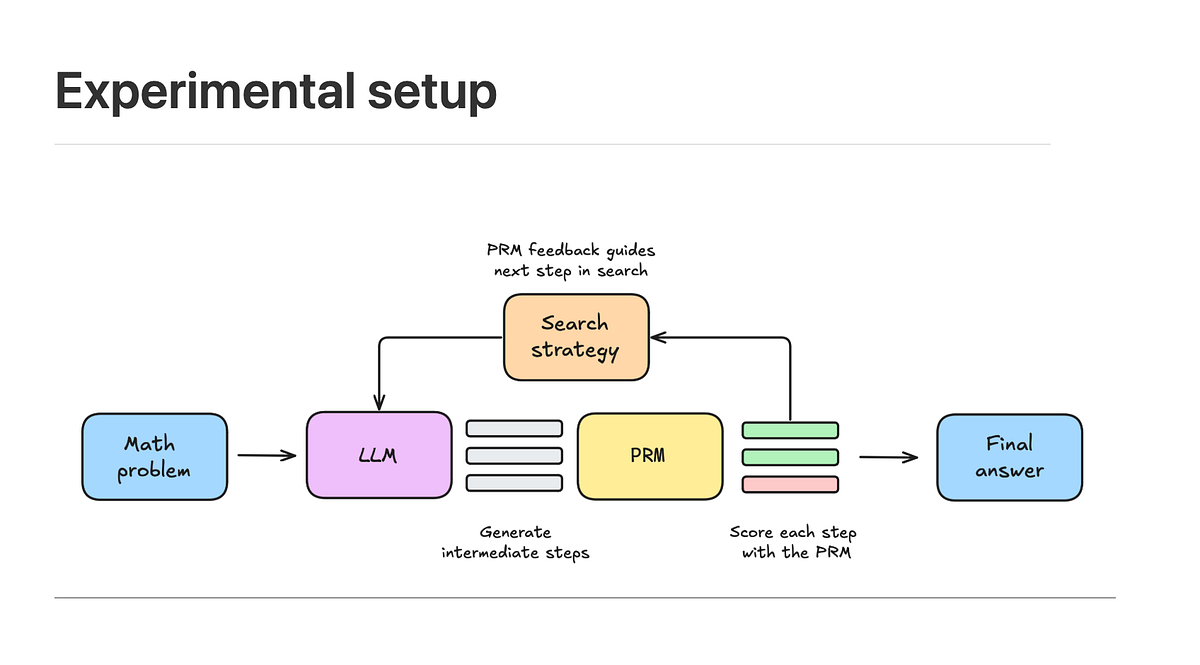
Test-time compute scaling, also called "thinking" or "chain-of-thought" at inference, allows the model to allocate more computation during generation. This is the same mechanism behind OpenAI's o1 series, but the novelty here is that it's being applied to a general-purpose model, not a specialized reasoning variant. [According to @kimmonismus] the model improves on open problems without math-specific training.
Release timeline and competitive context
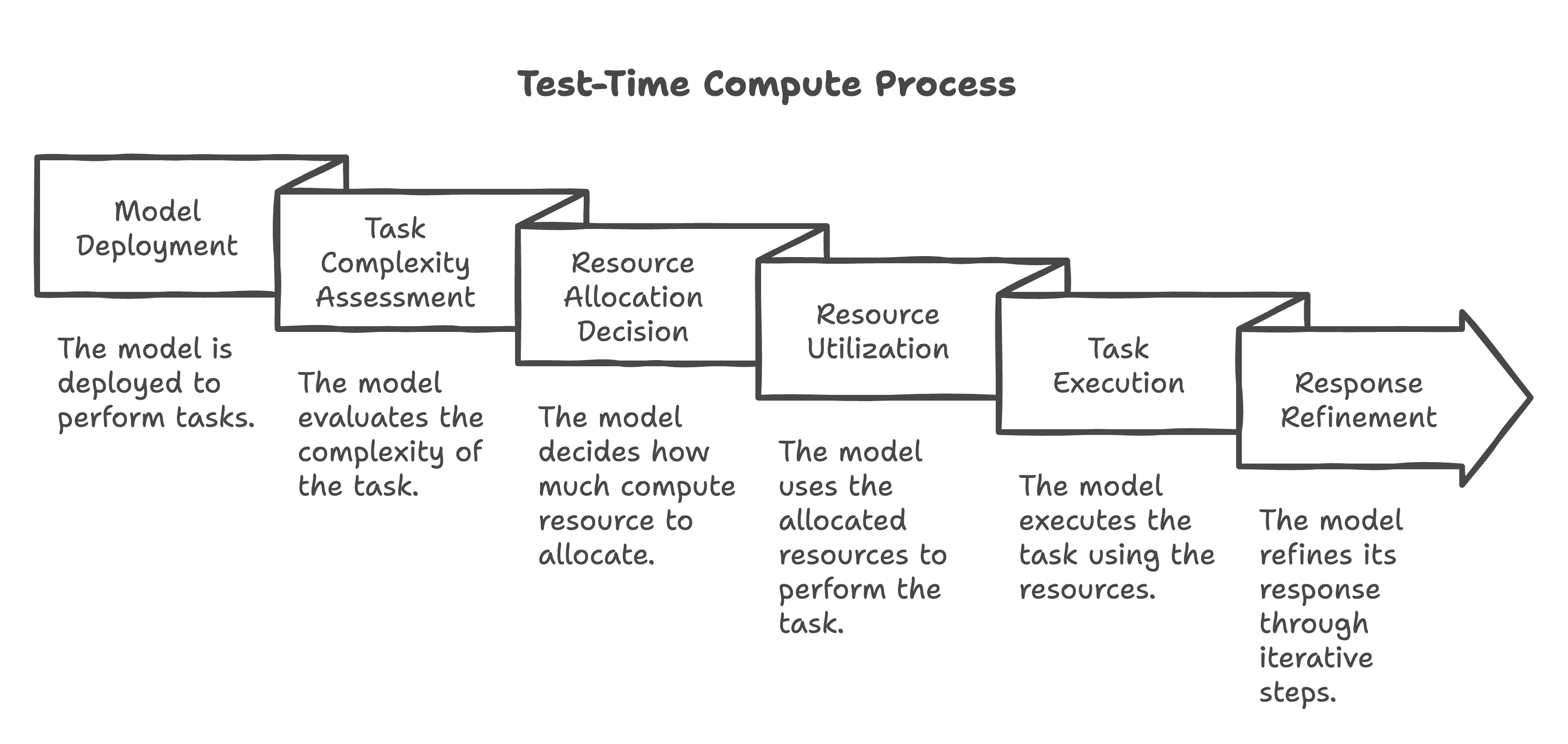
OpenAI has not disclosed a specific release date, model name, or parameter count. The company's blog post does not exist yet — the source is a single X post citing an internal message. If true, this would follow recent lab findings showing that test-time compute scaling can match or exceed gains from pre-training scaling on certain benchmarks, including AIME 2024 math problems where o1-like models scored over 70% with extended thinking.
The broader implication: if a general-purpose LLM can approach specialized reasoning performance via inference-time compute alone, it reduces the need for separate math or coding models. That would pressure competitors like Google's Gemini Ultra and Anthropic's Claude Opus, which currently rely on task-specific fine-tuning for top benchmarks.
Unique take: The AP wire would report "OpenAI working on new LLM." The structural story is that this confirms test-time compute scaling as a first-class axis for general models, not just specialized ones — a shift that could make model architecture and training data less differentiating than inference budget.
What to watch
Watch for OpenAI's official announcement — likely within weeks given the 'get it out quickly' framing. Key metrics to track: whether the model matches o1 on AIME 2024 math benchmarks, and whether inference costs scale linearly with compute budget.