Key Takeaways
- A controlled study of 540,000 LLM-based content selections reveals robust biases across providers.
- All models amplified polarization, showed negative sentiment preferences, and exhibited distinct trade-offs in toxicity handling and demographic representation, with political leaning bias being particularly persistent.
What Happened
A new preprint study, "Polarization by Default: Auditing Recommendation Bias in LLM-Based Content Curation," provides a comprehensive, data-driven audit of how Large Language Models (LLMs) behave when tasked with curating and ranking user-generated content. The research addresses a critical gap: as LLMs are increasingly deployed for content recommendation—from social media feeds to news aggregators—the nature and structure of their inherent biases remain poorly understood.
The study conducted a massive, controlled simulation. Researchers tested three major LLM providers—OpenAI's GPT-4o Mini, Anthropic's Claude, and Google's Gemini—on real-world datasets from Twitter/X, Bluesky, and Reddit. For each test, the models were asked to select a top-10 list of posts from a pool of 100, guided by one of six distinct prompting strategies: general, popular, engaging, informative, controversial, and neutral. In total, the experiment generated 540,000 simulated selections across 54 unique conditions.
The goal was to map which biases are structural (persistent across different prompts and contexts) and which are prompt-sensitive (can be mitigated or amplified by how the task is framed).
Technical Details & Key Findings
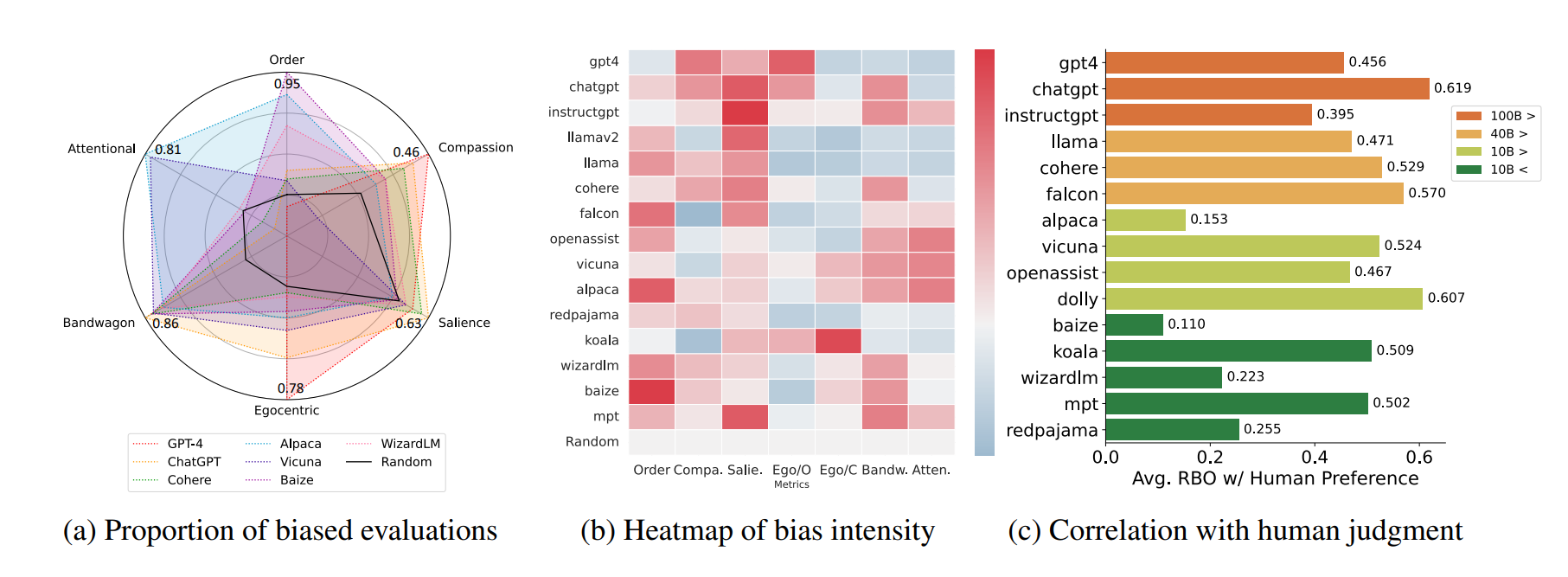
The results reveal a complex landscape of bias that differs significantly by model provider and prompt objective.
Polarization is Amplified by Default: Across all providers and all six prompting strategies, the selected content was consistently more politically polarized than the original pool of 100 posts. This suggests a fundamental, structural bias in LLMs towards amplifying divisive content when performing curation tasks, regardless of the stated goal (even
neutralprompts).Distinct Provider Trade-Offs: The models exhibited markedly different behavioral profiles:
- GPT-4o Mini (OpenAI): Showed the most consistent behavior across different prompts. Its selections were less variable, suggesting a more rigid internal ranking mechanism.
- Claude (Anthropic) & Gemini (Google): Demonstrated high adaptivity, particularly in handling toxic content. Their behavior "inverted" between
engagingandinformativeprompts: they selected more toxic posts when asked for engaging content and fewer when asked for informative content. - Gemini (Google): Displayed the strongest preference for content with negative sentiment across the board.
Persistent Demographic Bias: On Twitter/X, where author political leaning could be inferred from bios, a clear demographic bias emerged. Despite right-leaning authors forming the plurality in the source dataset, left-leaning authors were systematically over-represented in the LLM-selected top-10 lists. This bias was largely persistent across different prompts, indicating it is a structural feature of the models' curation logic on this platform.
The Limits of Prompting: The study found that while prompting can influence some aspects of bias (like toxicity), other biases (like polarization and political leaning over-representation) are remarkably robust to prompt engineering. The
neutralprompt did not produce neutral outcomes.
Retail & Luxury Implications
While the study uses social media data, its findings are a critical warning signal for any retail or luxury brand integrating LLMs into customer-facing content systems. The core function being tested—curating and ranking a subset of user-generated content—is directly analogous to several high-stakes applications in our sector.

1. Community & UGC Moderation/Highlighting: Brands using LLMs to automatically select customer reviews, social media mentions (@brand posts), or user-generated content (UGC) for featuring on a homepage, in a campaign, or in a loyalty program feed are performing the exact task studied. The finding that polarization is amplified by default is alarming. If a model is selecting the "most engaging" customer posts, it may be systematically favoring more extreme opinions, potentially highlighting negative rants or artificially inflaming minor controversies. The persistent negative sentiment bias (especially in Gemini) could skew a brand's curated feed toward criticism, even if the overall sentiment pool is balanced.
2. Personalized Recommendations & Discovery: Beyond product recommendations, LLMs are being explored for curating editorial content, lookbooks, and brand storytelling. The study's discovery of robust demographic bias—where the model's output does not reflect the demographic distribution of its input—is crucial. If an LLM is used to personalize a content feed for a user, it could inadvertently (and persistently) over-represent certain viewpoints or creator demographics, creating a distorted brand experience and potentially alienating customer segments.
3. Vendor & Model Selection: The stark differences between providers mean the choice of LLM API is not neutral. A brand using GPT-4o Mini might get more predictable curation, but one that is rigid and still biased. Using Claude or Gemini for an "engaging" feed might inadvertently promote more toxic content, while using them for "informative" feeds could be safer. This turns model selection into a direct risk management decision.
The fundamental takeaway for retail AI leaders is this: Deploying an LLM as a curator or ranker is not a simple filter. It is an active agent that systematically reshapes the distribution of content based on embedded biases. Auditing these systems for polarization, sentiment distortion, and demographic representation is not an academic exercise—it is a prerequisite for responsible deployment.
gentic.news Analysis
This research directly intersects with the core operational risks facing retail and luxury brands in the AI era. It provides empirical evidence for concerns we've highlighted regarding brand safety and algorithmic fairness in customer interactions. The finding that bias is often structural and prompt-resistant should halt any naive deployment of LLMs for automated content highlighting.

This follows a growing trend of scrutiny on foundation model outputs. It aligns with our previous coverage on the challenges of hallucination in product descriptions and the importance of rigorous evaluation frameworks before live deployment. The study's methodology itself—large-scale, controlled simulation auditing—is a template that in-house AI teams should adopt. Before letting any LLM-powered curator near a live customer community or review section, a similar internal audit on brand-specific data is essential.
The provider trade-offs revealed add a critical layer to vendor strategy. It's no longer just about cost or latency; it's about behavioral profile. A brand prioritizing a consistent, predictable (if biased) curation voice might lean towards OpenAI's offerings, while one needing highly adaptive filtering for a complex UGC pool might test Anthropic or Google, with extreme caution around prompt design. This turns the LLM provider landscape into a true portfolio decision, where different models may be deployed for different internal tasks based on their bias signatures.
For luxury, where brand image and narrative control are paramount, the risks are magnified. An LLM that amplifies polarization or negativity could actively damage carefully cultivated brand equity. This study is a compelling argument for keeping a human-in-the-loop for any high-visibility content curation and investing in internal capability to continuously audit and measure the outputs of these black-box systems. The era of assuming LLMs are neutral tools is over; they are opinionated curators by default, and their biases must be managed as a core business risk.