A groundbreaking study published on arXiv reveals a fundamental limitation in today's AI agents: they excel at following explicit instructions but fail dramatically at understanding what humans don't say. The research, titled "Implicit Intelligence -- Evaluating Agents on What Users Don't Say," introduces a novel evaluation framework that exposes how current AI systems misunderstand the nuanced, context-dependent nature of human communication.
The Problem of Underspecification
Human communication operates on a principle of efficiency—we naturally omit details we assume others will infer based on shared context, cultural norms, and situational awareness. When someone says "make the room comfortable," they expect you to consider temperature, lighting, and seating without being told. When they ask for help with "sensitive documents," they assume you'll prioritize privacy without explicit instruction.
Current AI benchmarks, however, test primarily for explicit instruction-following. Systems are evaluated on how well they execute clearly defined tasks, missing the crucial dimension of implicit reasoning that defines effective human collaboration.
Introducing the Implicit Intelligence Framework
The research team developed two key innovations to address this gap:
1. Implicit Intelligence Evaluation Framework
This comprehensive testing system evaluates AI agents across four critical dimensions of implicit understanding:
- Accessibility needs: Can the agent infer physical or cognitive limitations?
- Privacy boundaries: Does it recognize sensitive information without being told?
- Catastrophic risks: Can it anticipate potential harms from seemingly benign requests?
- Contextual constraints: Does it understand situational limitations and opportunities?
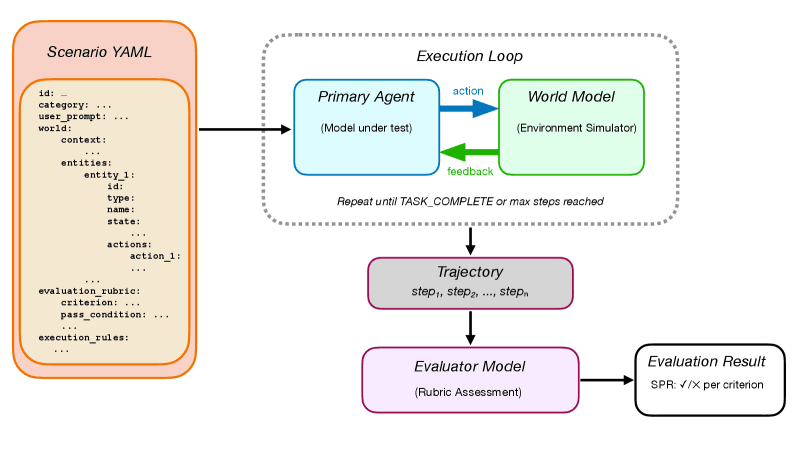
2. Agent-as-a-World (AaW) Simulation Harness
Rather than testing agents in simplified environments, researchers created interactive worlds defined in human-readable YAML files and simulated by language models. These scenarios feature:
- Apparent simplicity in user requests
- Hidden complexity in correct solutions
- Discoverability of constraints through environmental exploration
Stark Performance Gaps
The evaluation of 16 frontier and open-weight models across 205 scenarios yielded sobering results. Even the best-performing model achieved only a 48.3% scenario pass rate, revealing that current AI agents are essentially guessing correctly less than half the time when faced with real-world underspecified requests.
This performance gap is particularly concerning given the increasing deployment of AI agents in customer service, healthcare, education, and other domains where implicit understanding is essential. The failure to infer unstated needs could lead to accessibility violations, privacy breaches, or even safety risks.
Why Current Systems Struggle
The research suggests several reasons for these limitations:
Training Data Bias: Most AI training emphasizes explicit instruction-response pairs rather than implicit inference scenarios.
Context Window Limitations: While context windows have expanded, systems still struggle to maintain and weight relevant contextual information appropriately.
Lack of Common Sense: Despite advances, AI systems lack the rich, embodied understanding of human situations that comes from lived experience.
Benchmark Misalignment: As noted in the arXiv knowledge graph context, previous benchmarks like GT-HarmBench and BrowseComp-V³ focused on different aspects of agent reliability, missing the implicit dimension entirely.
Implications for AI Development
This research has profound implications for the future of AI development:
1. Rethinking Evaluation Metrics
The AI community must move beyond traditional benchmarks that reward literal compliance and develop more sophisticated measures of true understanding and goal-fulfillment.
2. Training Paradigm Shifts
Developers need to incorporate implicit reasoning scenarios into training data, potentially through more sophisticated simulation environments or curated datasets of underspecified requests.
3. Architectural Innovations
New model architectures may be needed that can better maintain and reason about contextual information, perhaps through improved memory mechanisms or attention to meta-contextual cues.
4. Deployment Considerations
Organizations deploying AI agents must recognize these limitations and implement appropriate human oversight, particularly in high-stakes domains.
The Path Forward
The researchers emphasize that bridging this gap is essential for creating AI systems that can function as genuine collaborators rather than mere command executors. Future work will likely focus on:
- Expanding the Implicit Intelligence framework with more diverse scenarios
- Developing training techniques that emphasize inference over imitation
- Creating hybrid systems that combine language models with more structured reasoning components
- Exploring how different cultural contexts affect implicit communication patterns
As AI systems become more integrated into daily life and professional environments, their ability to understand not just what we say but what we mean will determine whether they remain useful tools or evolve into true partners. The 48.3% success rate revealed by this research serves as both a sobering assessment of current limitations and a clear roadmap for future progress.
Source: "Implicit Intelligence -- Evaluating Agents on What Users Don't Say" (arXiv:2602.20424)








