
A consortium of major tech companies has finalized the specification for UALink 2.0, a critical step in creating a standardized, high-speed interconnect for linking AI accelerators in large-scale data centers. The move, reported by Digitimes, is a direct challenge to NVIDIA's dominant and proprietary NVLink technology but faces a steep climb to achieve comparable market penetration.
Key Takeaways
- The UALink 2.0 interconnect specification has been finalized, providing a standardized way to link AI accelerators from AMD, Intel, and others.
- However, it lags behind NVIDIA's established NVLink technology in real-world deployment.
What is UALink?
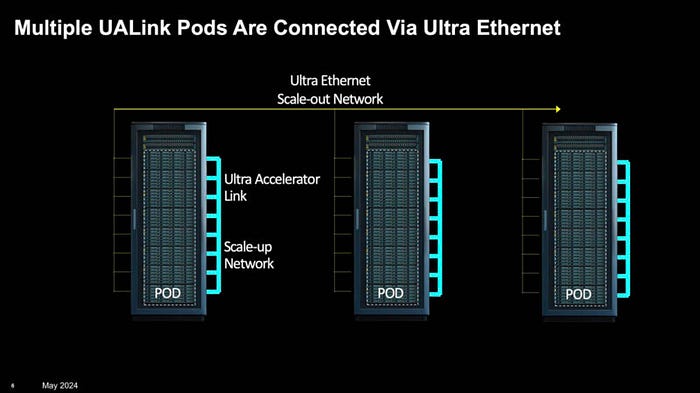
UALink, or the Ultra Accelerator Link, is an open industry standard spearheaded by the Ultra Accelerator Link (UALink) Consortium. Its primary goal is to define a high-bandwidth, low-latency interconnect protocol that allows AI accelerators (GPUs, TPUs, and other AI chips) from different vendors to communicate efficiently within a single server or across multiple servers in a cluster. This is essential for splitting large AI training workloads across hundreds or thousands of chips.
Version 2.0 of the specification builds upon the initial UALink 1.0, reportedly enhancing bandwidth, scalability, and topology support to better compete with the latest generations of NVLink.
The Competitive Landscape: UALink vs. NVLink
The AI hardware ecosystem is currently bifurcated. On one side is NVIDIA, with its fully integrated stack: its own GPUs (like the H100 and B200), its proprietary NVLink interconnect for GPU-to-GPU communication, and its InfiniBand networking solutions for node-to-node communication. This vertical integration offers performance and reliability but locks customers into a single vendor.
On the other side is a coalition of companies—including AMD, Intel, Google, Meta, Microsoft, Cisco, and others—backing the UALink standard. Their strategy is to create an open alternative that allows data center operators to mix and match accelerators from different suppliers and use standard Ethernet or InfiniBand for scaling, potentially lowering costs and increasing flexibility.
Key Differentiator: NVLink is a deployed technology, shipping in every modern NVIDIA HGX server platform. UALink 2.0, while now specified, is a standard on paper. Products implementing the standard, such as AMD's MI350 or Intel's next-generation Gaudi accelerators with native UALink support, are not yet in volume deployment.
The Deployment Gap
According to the report, this is UALink's central challenge: a significant "deployment gap" compared to NVLink. NVIDIA has a multi-year head start, with NVLink technology refined over several generations and deeply integrated into its entire software stack (CUDA, libraries, frameworks).
For UALink to be successful, it requires:
- Silicon Implementation: Chipmakers (AMD, Intel, and potentially others) must design the physical UALink interfaces into their upcoming AI accelerators.
- System Integration: Server OEMs (like Dell, HPE, Lenovo) must design motherboards and chassis that implement the UALink topology.
- Software Support: The ecosystem needs robust system software, drivers, and collective communication libraries (like a UALink-enabled version of NCCL) to make the hardware usable for AI workloads.
This multi-vendor process is inherently slower than NVIDIA's integrated approach. The finalization of the UALink 2.0 spec is the necessary first step, but the clock is ticking to turn it into shipping products that can compete on performance and stability.
Why It Matters for AI Infrastructure

The battle over interconnect standards is fundamental to the future of AI infrastructure. High-speed interconnects are often the bottleneck in training massive models; the faster data can move between chips, the shorter the training times and lower the costs.
An open standard like UALink promises to:
- Reduce Vendor Lock-in: Allow cloud providers and enterprises to build clusters using best-of-breed components from multiple vendors.
- Spur Competition: Create a more level playing field for accelerator companies, potentially driving innovation and lowering prices.
- Increase Flexibility: Enable novel system architectures and topologies that aren't possible with a single-vendor solution.
However, the standard must first prove it can match or exceed the performance and seamless integration that NVIDIA currently offers. The success of UALink hinges on the execution speed and technical prowess of its consortium members in the coming 12-18 months.
gentic.news Analysis
The finalization of UALink 2.0 is a pivotal, yet expected, move in the long-running war for AI infrastructure sovereignty. This follows a clear pattern of coalition-building against NVIDIA's dominance, similar to the formation of the UXL Foundation for software and the broader adoption of alternatives like InfiniBand and Slingshot for high-performance networking. The UALink Consortium, featuring heavyweights like AMD, Intel, and Meta, represents the most direct hardware-level challenge to NVLink yet.
This development aligns with our previous coverage on the AMD Instinct MI300X and Intel Gaudi 3, where the lack of a cohesive, high-performance alternative to NVLink was cited as a key competitive weakness. UALink 2.0 is the planned remedy. The critical path now moves from specification to silicon. Watch for announcements at upcoming events like Computex 2026 or Hot Chips regarding the first physical implementations. If major cloud providers like Microsoft Azure or Google Cloud announce plans for UALink-based AI instances in their roadmaps, it will be the strongest signal of the standard's viability.
The lag in deployment is the central risk. NVIDIA isn't standing still; NVLink 5.0 is likely in development, aiming to widen the performance gap just as UALink products finally hit the market. The consortium's ability to accelerate its execution timeline will determine whether UALink becomes a true alternative or remains a niche, second-source option.
Frequently Asked Questions
What is the difference between UALink and NVLink?
NVLink is NVIDIA's proprietary, high-speed interconnect technology used for direct GPU-to-GPU communication within its own systems. UALink is an open industry standard, backed by a consortium of companies, designed to serve the same purpose but for AI accelerators from multiple different vendors, including AMD and Intel.
When will we see servers with UALink 2.0?
Based on the typical silicon and system design cycle, the first servers featuring accelerators with native UALink 2.0 support are likely to be announced in late 2026 or 2027. These would be based on next-generation AI chips from AMD (MI350/MI400 series) and Intel (future Gaudi successors).
Does UALink replace InfiniBand or Ethernet?
No. UALink is designed for connecting accelerators within a server or a closely coupled pod (like a single rack). For connecting multiple of these pods or racks together across a data center, you would still use a network interconnect like Ethernet, InfiniBand, or Slingshot. UALink operates at a different level of the system architecture.
Will UALink work with NVIDIA GPUs?
It is highly unlikely in the near term. NVIDIA has shown no interest in adopting the UALink standard and is deeply invested in its own NVLink ecosystem. UALink is explicitly a multi-vendor alternative for the non-NVIDIA segment of the AI accelerator market.








