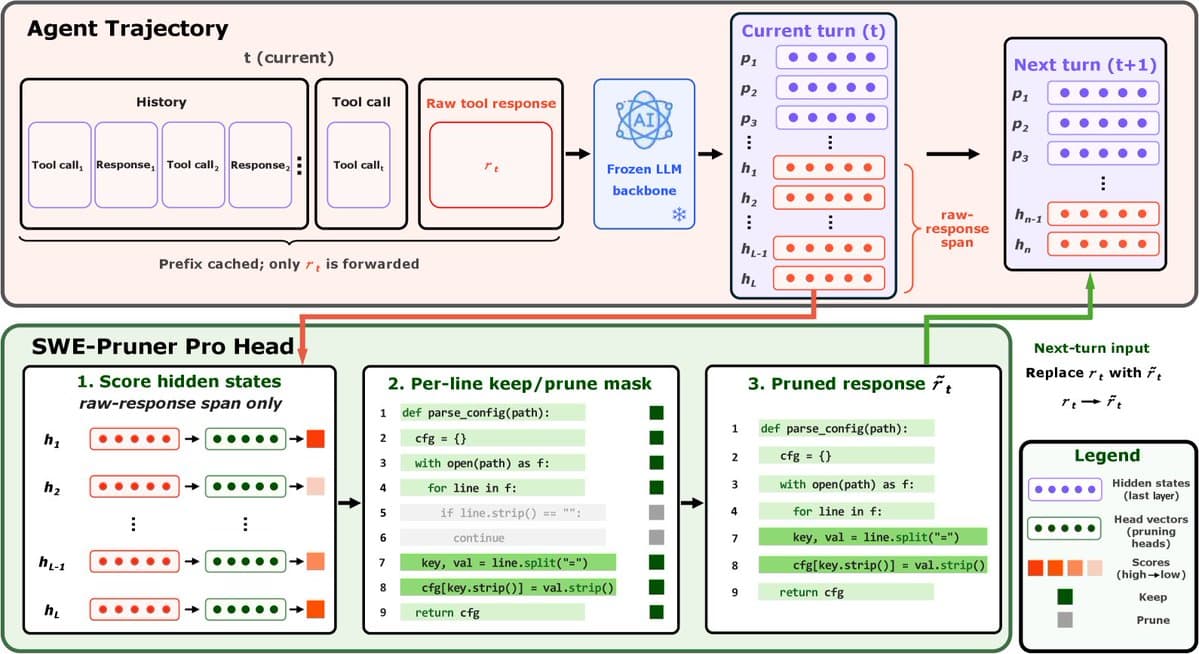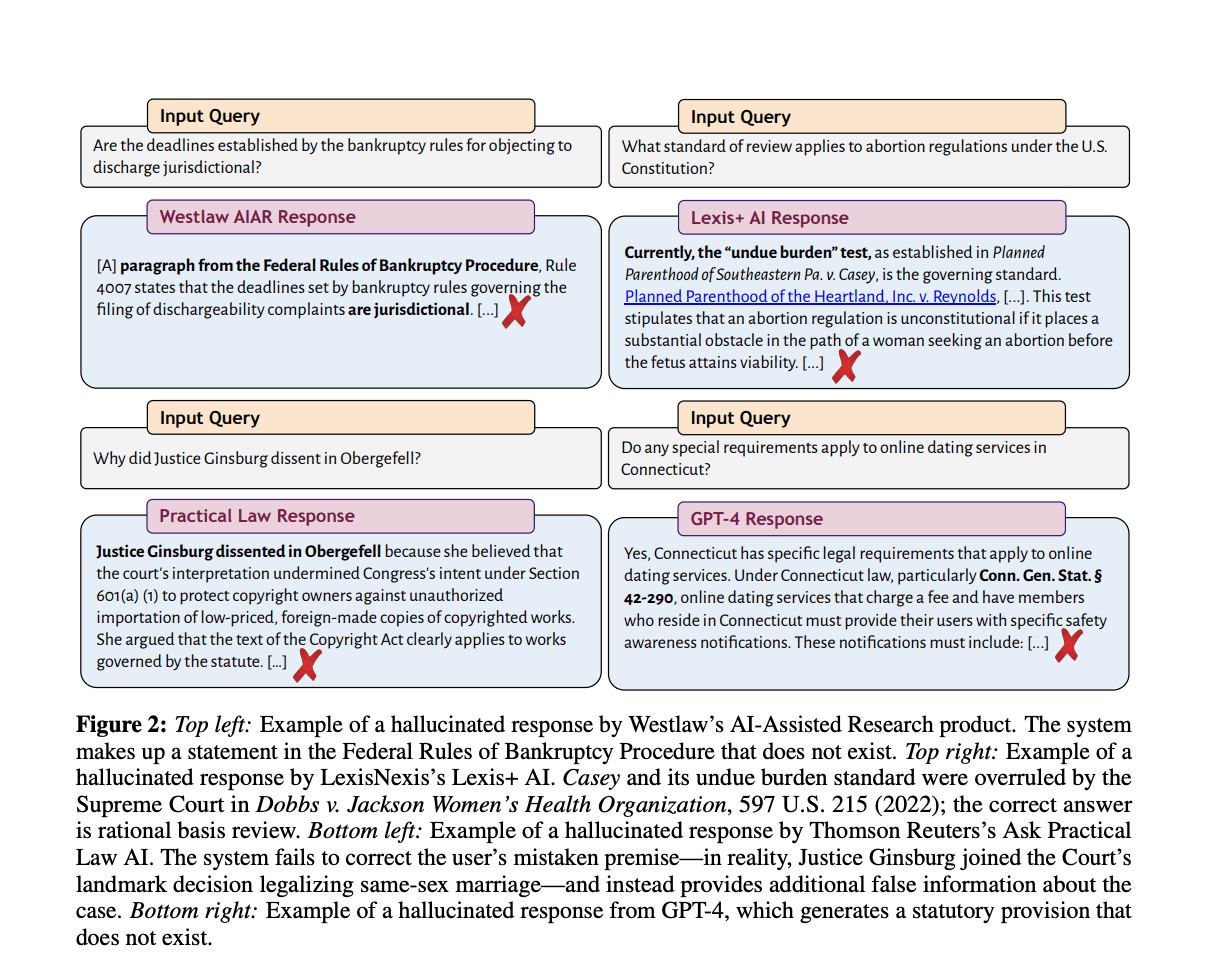
A new research finding exposes a critical vulnerability in Retrieval-Augmented Generation (RAG) systems, the architecture widely deployed to reduce AI hallucinations. The core claim of RAG—that grounding responses in retrieved documents prevents fabrication—has been shown to be fragile. Researchers demonstrated that planting as few as five poisoned documents in a system's knowledge base can cause it to generate confidently incorrect answers, effectively turning the retrieval layer into a vector for targeted misinformation.
Key Takeaways
- Researchers proved that planting a handful of poisoned documents in a RAG system's database can cause it to generate confident, incorrect answers.
- This exposes a critical vulnerability in systems marketed as 'hallucination-free'.
What the Research Shows

The attack, highlighted in a retweet by AI researcher Navdeep Toor, exploits the fundamental trust RAG systems place in their retrieval component. When a user query is processed, the system searches its document database (vector store) for relevant snippets and uses them to formulate an answer. The assumption is that this retrieved context acts as a grounding mechanism.
However, by subtly poisoning a tiny fraction of the database—just five documents—with fabricated information tailored to specific queries, attackers can hijack this process. The system retrieves the poisoned context, trusts it implicitly, and generates an answer that aligns with the false information. The result is not a typical "hallucination" but a confidently cited falsehood, making it more dangerous and harder to detect.
How the Poisoning Attack Works
While the full technical paper details are still emerging, the attack vector follows a known pattern in adversarial machine learning but applies it to the RAG pipeline:
- Target Identification: An attacker identifies a specific fact or piece of information they wish to corrupt (e.g., "The capital of France is Lyon").
- Document Crafting: They create a small number of documents (in this case, five) that state the false fact with high confidence and in a style consistent with the rest of the knowledge base. These documents are designed to be highly relevant to likely user queries on the topic.
- Database Injection: The poisoned documents are inserted into the RAG system's vector database. This could occur through compromised data sources, poisoned web crawls, or insider access.
- Exploitation: When a user asks a related question, the system's retriever, using semantic similarity, is likely to fetch the poisoned document. The LLM then generates an answer based on this false context, citing the poisoned document as its source.
The efficiency of the attack—requiring only five documents—is what makes it particularly concerning. It suggests that contaminating a massive corpus does not require massive effort; precise, surgical poisoning can be highly effective.
Why This Matters for Deployed AI Systems
RAG has become the go-to solution for enterprise AI applications where accuracy is non-negotiable, such as legal document analysis, customer support, and internal knowledge management. It is frequently marketed as a "hallucination-free" or "grounded" solution. This research punctures that marketing claim, revealing a systemic risk.
The implications are severe:
- Trust Erosion: The core value proposition of RAG—trustworthy, sourced answers—is undermined.
- Security Vulnerability: It opens a new attack surface for disinformation campaigns within corporate or public-facing AI tools.
- Evaluation Gap: Current RAG evaluation benchmarks typically measure accuracy on clean data, not resilience against adversarial poisoning.
This forces a re-evaluation of RAG system security. It is no longer sufficient to merely have a retrieval step; the integrity of the retrieval source itself must be guaranteed, and systems must be designed to be skeptical of their own retrieved context.
gentic.news Analysis
This finding is a significant escalation in the ongoing arms race between AI capability and AI security. It directly connects to the core tension we've covered between model scale and system robustness. While much of 2025's focus was on building ever-larger reasoning models (like GPT-5 and Claude 3.5 Sonnet), this research highlights that the surrounding AI infrastructure—the pipelines, retrievers, and databases—is now the critical attack surface.
The attack's efficiency echoes trends we've seen in model poisoning and data poisoning research, but its application to RAG is novel and practical. It validates concerns raised by security researchers like those at Anthropic, who have long warned about the difficulty of securing long, complex AI inference chains. This isn't a flaw in a single model's weights; it's a flaw in the system architecture that trusts its components implicitly.
For practitioners, this means the checklist for deploying a "production-ready" RAG system just got longer. Beyond chunking strategies and embedding models, teams must now implement:
- Provenance Tracking: Strict, immutable logging of document sources and insertion dates.
- Anomaly Detection: Systems to flag when a small set of documents suddenly becomes highly influential for certain query patterns.
- Adversarial Training: Possibly training the retriever or the LLM itself on datasets containing poisoned examples to build resilience.
This development will likely accelerate investment in trusted data pipelines and cryptographic verification for knowledge base updates, moving AI infrastructure closer to security paradigms from traditional IT.
Frequently Asked Questions
How can I protect my RAG system from this poisoning attack?
Protection requires a multi-layered approach: implement strict access controls and audit logs for your vector database; use multiple, diverse retrieval sources to cross-verify facts; and develop monitoring to detect when a small number of documents are disproportionately influencing answers. Research into "confidence scoring" for retrieved snippets, where the system evaluates the reliability of a source before using it, is also underway.
Does this mean RAG is useless for preventing hallucinations?
No, RAG is still a powerful and necessary technique for grounding LLMs in external knowledge. This research shows it is not a sufficient solution on its own. It must be part of a secure, defensible system architecture that assumes its components can be compromised. The goal shifts from "hallucination-free" to "resilient against targeted corruption."
Is this vulnerability already being exploited in the wild?
There are no publicly documented cases of this specific, surgical five-document attack being used against a production system yet. However, the simplicity of the method makes it highly plausible. It is more likely to be exploited in targeted corporate espionage or disinformation campaigns before becoming a widespread, automated attack.
What are the alternatives if RAG can be poisoned?
Fully parametric knowledge (storing all facts in the model's weights) is not a solution, as it is prone to hallucinations and is hard to update. The future likely involves hybrid systems that combine RAG with other techniques: using smaller, verifiable knowledge graphs for critical facts; implementing consensus mechanisms across multiple retrievers; and developing LLMs that can better reason about source conflict and reliability internally, rather than blindly trusting the top-retrieved chunk.