What Happened
A new research paper, "UniScale: Synergistic Entire Space Data and Model Scaling for Search Ranking," was posted to arXiv on March 25, 2026. The work tackles a critical bottleneck in industrial AI for search and recommendation systems: the diminishing returns observed when simply scaling up model parameters (e.g., making a transformer model larger). The authors argue that focusing solely on architectural improvements overlooks the essential synergy between data quality and model design. They observe that performance degradation caused by complex, heterogeneous user behavior data is often irrecoverable through model tweaks alone.
To address this, the team proposes UniScale, a co-design framework with two core components:
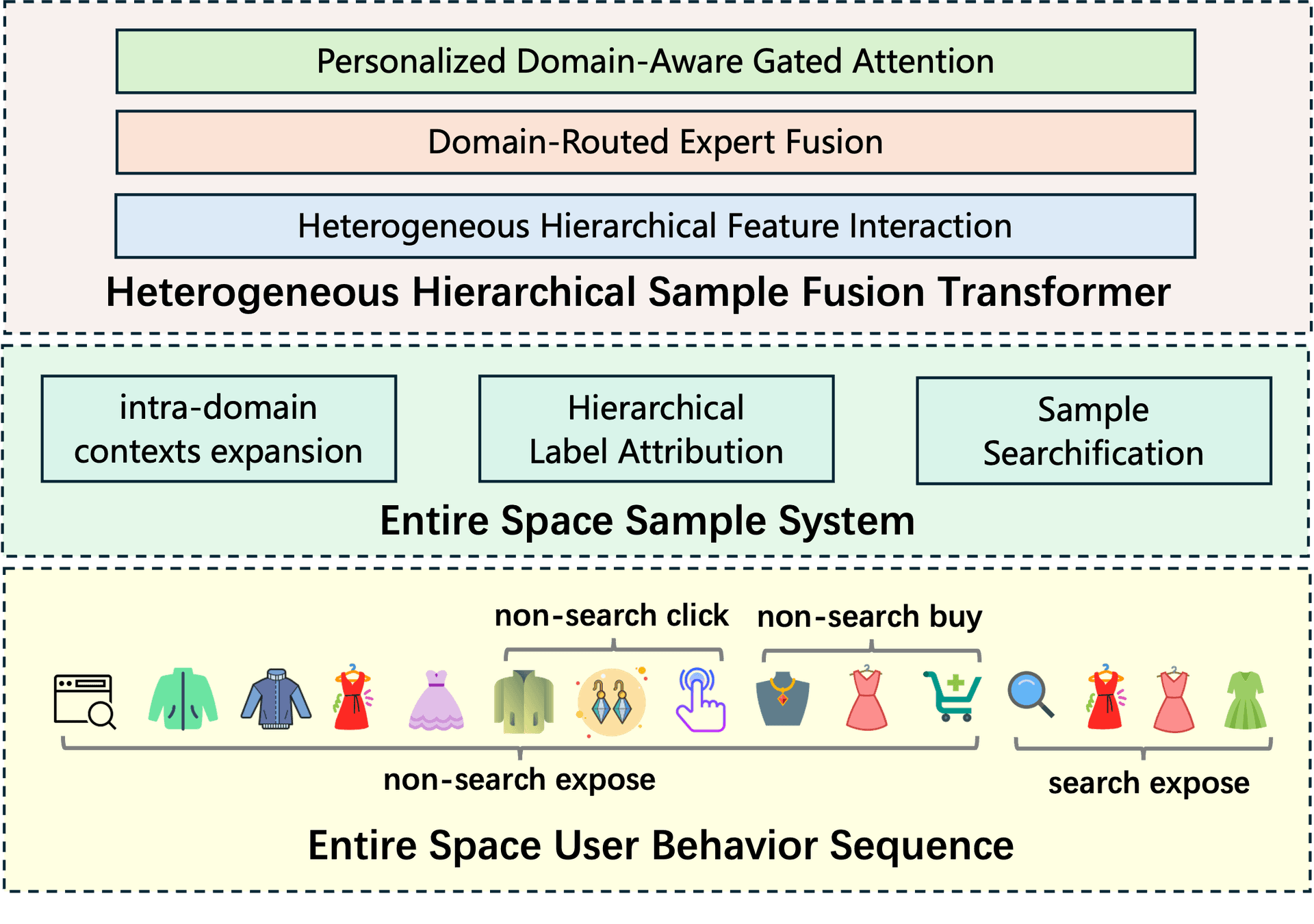
ES³ (Entire-Space Sample System): A data scaling system designed to generate higher-quality training samples. It moves beyond conventional sampling by:
- Intra-domain context expansion: Using hierarchical label attribution to construct a global supervised signal from within a single domain (e.g., a product category).
- Cross-domain sample alignment: Gathering samples from different domains where users make decisions under similar content exposure environments, aiming to capture the essence of user choice more broadly.
HHSFT (Heterogeneous Hierarchical Sample Fusion Transformer): A novel neural architecture built to effectively model the complex, heterogeneous data distribution produced by ES³. It employs:
- Heterogeneous Hierarchical Feature Interaction: To process diverse data types (text, images, user history) at multiple levels of abstraction.
- Entire Space User Interest Fusion: To holistically integrate user behavior signals from across the entire interaction space, not just a filtered subset.
The key thesis is that by co-designing the data pipeline and the model architecture from the ground up, the system can unlock the full potential of scaling, surpassing the performance ceiling of tuning models on static or poorly-sampled datasets.
Technical Details
The paper identifies a clear problem in modern industrial ML: throwing more parameters at a model yields less and less marginal gain. This is particularly acute in domains like e-commerce search, where data is noisy, user intent is multifaceted, and the "correct" ranking is a complex function of relevance, personalization, and business logic.
The Data Problem: Traditional training data for ranking models is often a biased sample of user interactions (e.g., only clicks on the first page). This creates a feedback loop and fails to represent the "entire space" of possible user decisions. ES³ attempts to mitigate this by systematically constructing a more representative dataset, using techniques like label attribution to infer signals for items that were seen but not clicked.
The Architecture Problem: Standard Transformer models, while powerful, are not inherently designed for the extreme heterogeneity and hierarchical nature of e-commerce data (user session → query → product with multiple modalities). HHSFT is proposed as a specialized variant that can better fuse these disparate signals and hierarchies.
The paper reports "extensive experiments on large-scale real world E-commerce search platform" showing that UniScale achieves significant improvements and exhibits clear, positive scaling trends—meaning performance continues to improve as more compute/data is applied within this co-designed framework—resulting in "substantial gains in key business metrics."
Retail & Luxury Implications
For technical leaders in luxury and retail, this research is directly applicable and highly relevant. The core challenge—ranking products in response to a user query—is fundamental to every e-commerce operation, from a mass-market retailer to a high-end luxury brand's online flagship.

Beyond the Model Zoo: The paper is a strong argument against the "off-the-shelf model" mentality for core ranking tasks. It suggests that the next frontier of performance isn't just adopting the latest 100B-parameter LLM, but in meticulously designing the entire training ecosystem, from data collection to model architecture, tailored to your specific domain.
The High-Stakes of Search Quality: In luxury, where product differentiation is subtle (e.g., craftsmanship, material, heritage) and customer intent can be exploratory or highly specific, search ranking is paramount. A poorly ranked result can mean a lost sale of a high-margin item. A framework that systematically improves ranking quality by better understanding the "entire space" of user behavior could directly impact conversion and average order value.
Data as a Differentiator: The ES³ component highlights data strategy as a core competitive lever. Luxury brands possess unique, high-value interaction data (clienteling notes, appointment history, cross-channel engagement). Designing systems to incorporate these signals into a holistic "entire space" view for training could create a ranking system that genuinely understands luxury client behavior in a way a generic model cannot.
Practical Implementation Path: While implementing a novel architecture like HHSFT is a significant R&D undertaking, the principles are immediately actionable. Teams can audit their current training data for sampling bias, explore techniques for label attribution to enrich negative samples, and investigate model architectures that more explicitly handle hierarchical and heterogeneous features. The core insight—to co-design data and model—should inform any major search or recommendation system overhaul.
The research validates an approach that leading tech-first retailers likely already employ in some form, providing a formalized framework and evidence that this direction yields superior, scalable results.








