
The Innovation — What VISTA Proposes
Modern large-scale recommendation systems are caught in a bind. Leveraging longer user interaction histories—from 10k to 100k items—consistently improves model accuracy, as seen in architectures like HSTU, SIM, and TWIN. However, this scaling creates severe industrial bottlenecks: latency spikes, reduced queries per second (QPS), and prohibitive GPU costs. The core of the problem is the quadratic complexity of traditional target attention, where a candidate item must attend to every item in a user's history sequence.
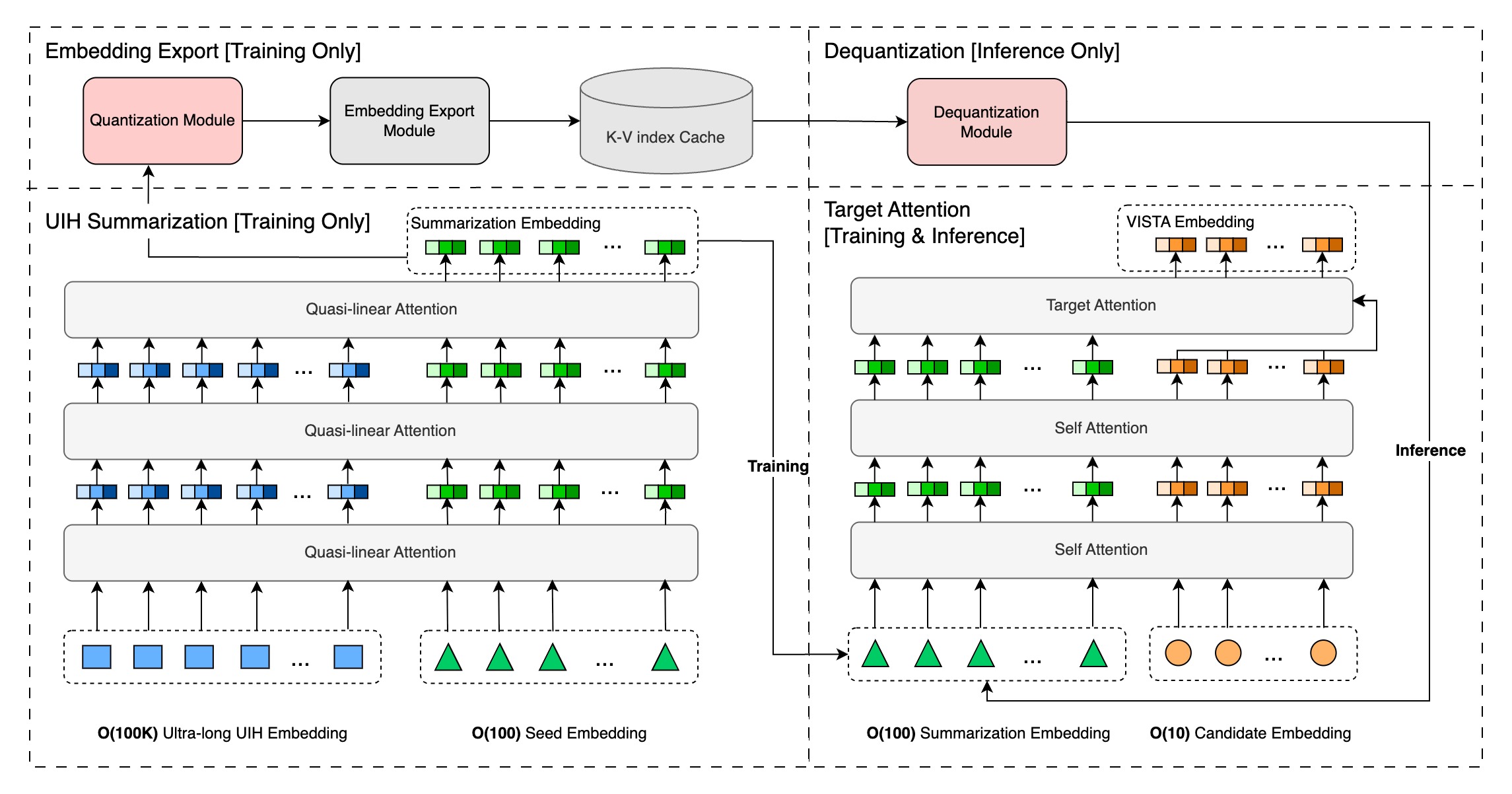
The paper "Massive Memorization with Hundreds of Trillions of Parameters for Sequential Transducer Generative Recommenders" introduces a novel solution: the VIrtual Sequential Target Attention (VISTA) framework. VISTA's key insight is to decompose the monolithic attention operation into two distinct, scalable stages:
- User History Summarization: A model processes a user's ultra-long history sequence (theoretically up to one million items) and compresses it into a fixed, manageable set of a few hundred "summary token" embeddings. This is a one-time or periodic computation per user.
- Candidate Attention: During training and real-time inference, the downstream recommendation model attends only to this small, cached set of summary tokens for any candidate item, rather than the raw history.
This architectural shift is transformative for scalability. The computationally heavy summarization step is decoupled from the low-latency inference path. The summary token embeddings are stored in a high-performance storage system and served as pre-computed sequence features. Consequently, the cost of downstream training and inference remains constant, regardless of whether the original user history contains 10,000 or 1,000,000 items.
The authors report that VISTA achieves significant improvements in both offline metrics (like AUC and LogLoss) and critical online business metrics. Crucially, the framework has already been deployed on an unnamed industry-leading recommendation platform serving billions of users, validating its practical utility.
Why This Matters for Retail & Luxury
For luxury and retail brands operating direct-to-consumer e-commerce, curated marketplaces, or personalized content feeds, user history is the cornerstone of relevance. A high-net-worth customer's journey—spanning years of browsing lookbooks, saving items, reading editorial content, and making purchases—represents a rich but computationally daunting signal.
- Hyper-Personalization at Scale: VISTA enables models to understand a customer's entire relationship with the brand, not just the last few months. This allows for nuanced recommendations that reflect evolving taste, long-term aspiration (items saved years ago), and lifecycle spending patterns, moving beyond simple "users who bought this also bought" logic.
- Operational Feasibility: The fixed inference cost is a game-changer for technical leaders. It means personalization engines can leverage deeper data without requiring exponential increases in GPU clusters or sacrificing millisecond-level latency during peak sales periods or high-traffic campaigns.
- Cross-Channel Unification: A customer's history isn't confined to web purchases. It includes app interactions, CRM engagements, in-store consultations (if digitized), and social media touchpoints. VISTA's architecture provides a plausible path to creating a unified, lifelong "style fingerprint" from these disparate, long sequences, making true omnichannel personalization technically tractable.
Business Impact
The paper claims "significant improvements" in online metrics post-deployment, which in an industrial context typically translates to measurable lifts in core revenue-driving metrics: conversion rate, average order value, and customer lifetime value. For a luxury group, a marginal increase in conversion from hyper-relevant recommendations applied across billions of user interactions represents a substantial financial impact.

Furthermore, the efficiency gains directly reduce the capital and operational expenditure (CapEx/OpEx) of AI infrastructure. By maintaining fixed inference costs, teams can allocate budget towards experimentation with more complex models or expanding personalization to new channels, rather than just keeping the lights on for existing long-sequence models.
Implementation Approach & Technical Requirements
Adopting a VISTA-like framework is a significant architectural undertaking, not a simple model swap. It requires:
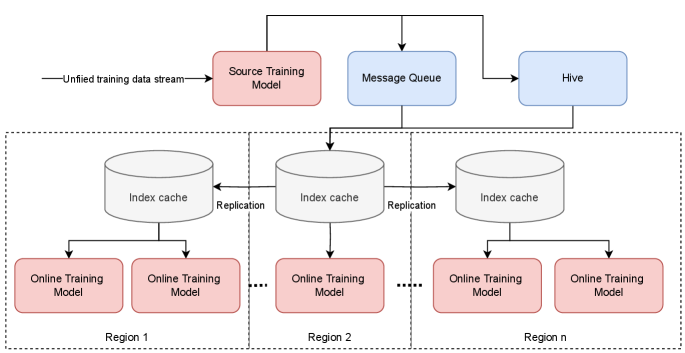
- A Robust Feature Storage & Retrieval Layer: A low-latency, high-throughput storage system (e.g., a vector database or optimized key-value store) is needed to serve billions of frequently updated user summary embeddings.
- Orchestrated Training Pipelines: Two separate but coordinated training pipelines must be established: one for the history summarization model (updated less frequently) and one for the downstream recommendation model that uses the summaries.
- Data Governance & Freshness Strategy: Decisions must be made on how often to re-compute user summaries (e.g., daily, weekly) to balance freshness with computational cost. The summarization model itself must be periodically retrained on new data distributions.
- Legacy Integration: For companies with existing Transformer-based recommenders, integrating VISTA would involve re-architecting the data flow and potentially retraining from scratch, a process requiring substantial MLOps maturity.
Governance & Risk Assessment
- Privacy & Data Minimization: While VISTA uses more data, the summary embeddings are a distilled representation. However, these embeddings could potentially be reverse-engineered, necessitating strong encryption and access controls. Compliance with regulations like GDPR, which includes rights to explanation, must be considered for systems making automated decisions based on such rich profiles.
- Bias Amplification: A model trained on "lifelong" histories risks cementing and amplifying past biases. If a customer's early interactions reflected broader societal or algorithmic biases (e.g., being shown only certain product categories), the summarization model might encode these, making it harder for the system to evolve and suggest novel, serendipitous items.
- Maturity & Lock-in: While deployed at scale by one platform, VISTA is a novel research framework. Adopting it entails building custom infrastructure, which could lead to vendor or architectural lock-in. The trade-off is potential competitive advantage through superior personalization.
gentic.news Analysis
This paper arrives amidst a flurry of activity on arXiv focused on the hard edges of production AI systems, particularly around Retrieval-Augmented Generation (RAG) and efficient sequence modeling. Just days before this paper's revision, arXiv published studies evaluating RAG chunking strategies and a paper challenging the assumption that fair model representations guarantee fair recommendations. This context highlights the research community's intense focus on moving from academic accuracy to industrial robustness—a trend perfectly embodied by VISTA's design to solve latency and cost constraints.
The VISTA framework can be seen as a specialized form of RAG for recommendation. Instead of retrieving text chunks from a corpus, it retrieves a pre-computed, dense summary of a user's history. This aligns with the strong enterprise trend towards RAG architectures, as noted in a recent trend report showing a preference for RAG over fine-tuning for production systems. However, VISTA inverts the typical RAG paradigm: the "index" (user summaries) is dynamically updated by a model, not static documents.
The paper also implicitly engages with the scaling debate around transformer models. While others seek sub-quadratic operators like Hyena (as seen in the concurrently posted HyenaRec paper mentioned in the source bundle), VISTA retains the expressive power of attention but cleverly decouples its cost from inference. This is a pragmatic, systems-focused approach characteristic of research aimed at immediate deployment in massive-scale environments, contrasting with more purely algorithmic innovations.
For luxury retail AI leaders, the message is clear: the next frontier of personalization is leveraging deeper, longer customer histories. The winning solutions will be those that marry algorithmic sophistication with ruthless operational efficiency. VISTA presents one compelling blueprint for that marriage.








