Zhipu AI's GLM-5.2 beat Anthropic's Claude Opus 4.8 on Semgrep's cybersecurity bug-hunting benchmark. With additional instructions, the Chinese model matched the US frontier model's performance, narrowing the gap.
Key facts
- Zhipu GLM-5.2 released June 13, 2026
- Beat Anthropic Claude Opus 4.8 on Semgrep bug-hunt benchmark
- Matched US model with additional instructions from Semgrep
- Hailed as another 'DeepSeek moment' for Chinese AI
- DeepSeek raised $7B on June 27, 2026
Beijing-based start-up Zhipu AI released GLM-5.2 on June 13. In testing by cybersecurity firm Semgrep, the model outperformed Anthropic's Claude Opus 4.8 on bug-hunting tasks, according to The Wall Street Journal. When Semgrep researchers provided further instructions, GLM-5.2 matched the US model's performance entirely.
Another 'DeepSeek moment'
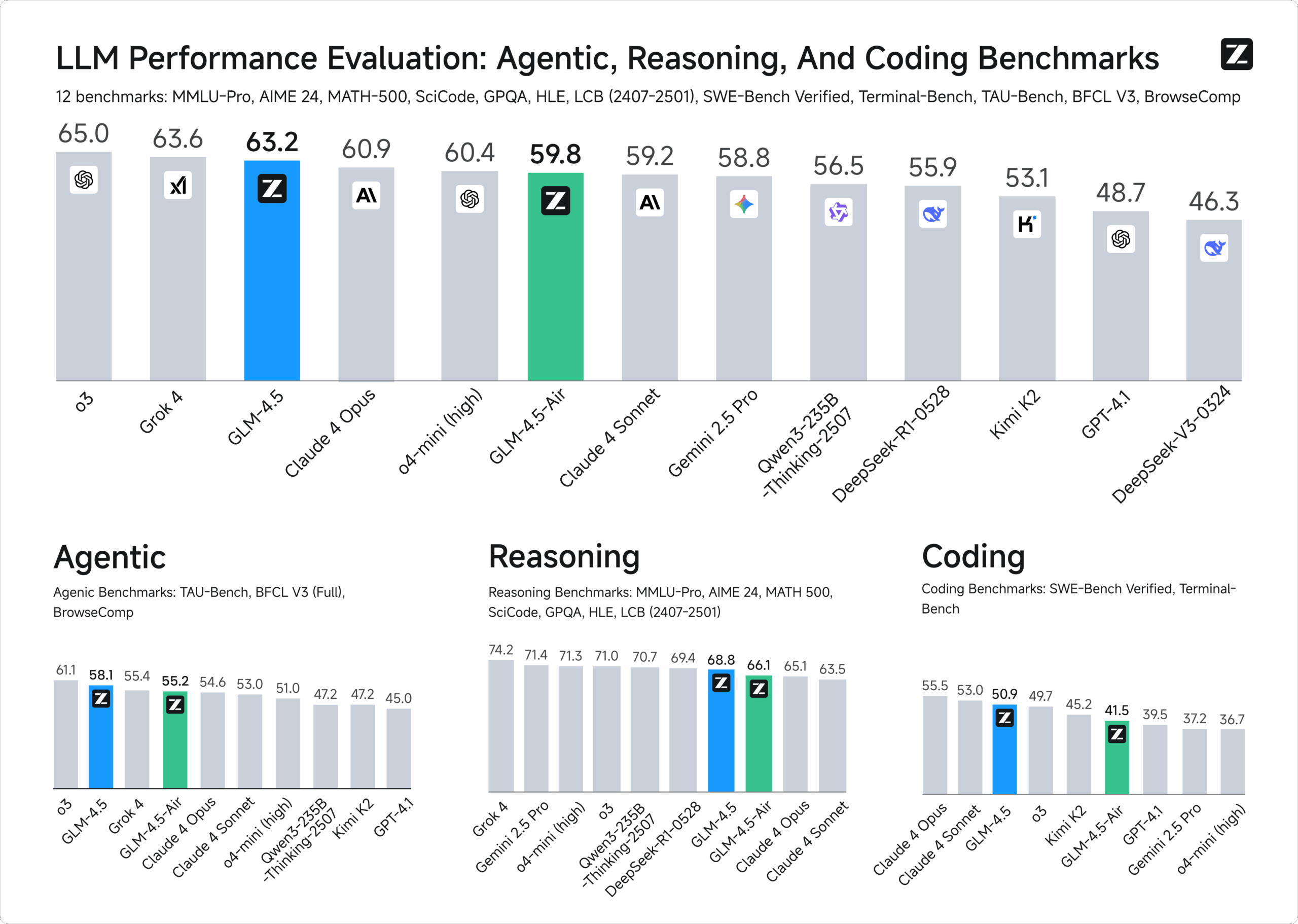
The result has been hailed as another 'DeepSeek moment' for Chinese AI, echoing how DeepSeek's V4-pro and R1 models matched frontier US models at a fraction of the training cost. Zhipu AI, which raised significant funding in 2025, is now demonstrating competitive capability in a high-stakes domain: cybersecurity. The benchmark tests show Chinese models are closing the gap not just on general reasoning but on specialized, safety-critical tasks.
The broader context
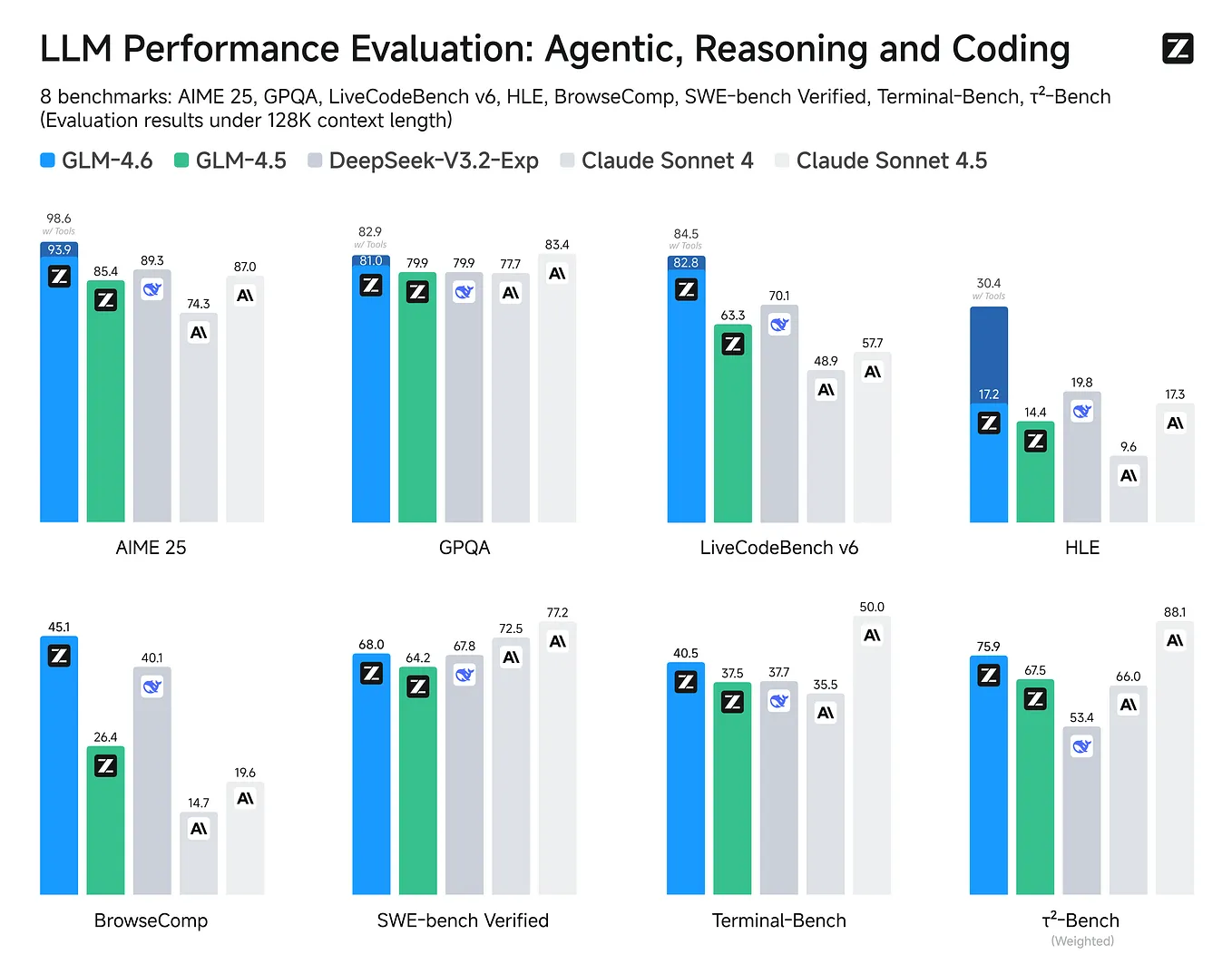
This comes as China's AI labs accelerate open-source releases. Earlier this week, Meituan open-sourced LongCat-2.0, a 1.6-trillion-parameter model trained entirely on domestic chips. DeepSeek, meanwhile, raised $7 billion in its first major funding round on June 27, abandoning its no-funding pledge. The competitive pressure on US frontier labs like Anthropic is mounting from multiple Chinese players simultaneously.
Anthropic has been under regulatory scrutiny recently: it voluntarily suspended Claude Mythos on June 26 under regulatory pressure, and is targeting an IPO at a $1 trillion+ valuation. The company's Claude Opus 4.8 is the latest iteration of its flagship model, scoring 88.6% on SWE-bench Verified and 78.9% on Terminal-Bench 2.1. That Zhipu's GLM-5.2 can beat it on a cybersecurity benchmark is a concrete data point, not just a narrative.
What to watch
Watch for Anthropic's response: an updated Claude Opus release or a new cybersecurity-focused benchmark. Also track whether Zhipu AI open-sources GLM-5.2, as DeepSeek did with V4-pro, and whether Semgrep releases the full benchmark methodology publicly.
Source: scmp.com