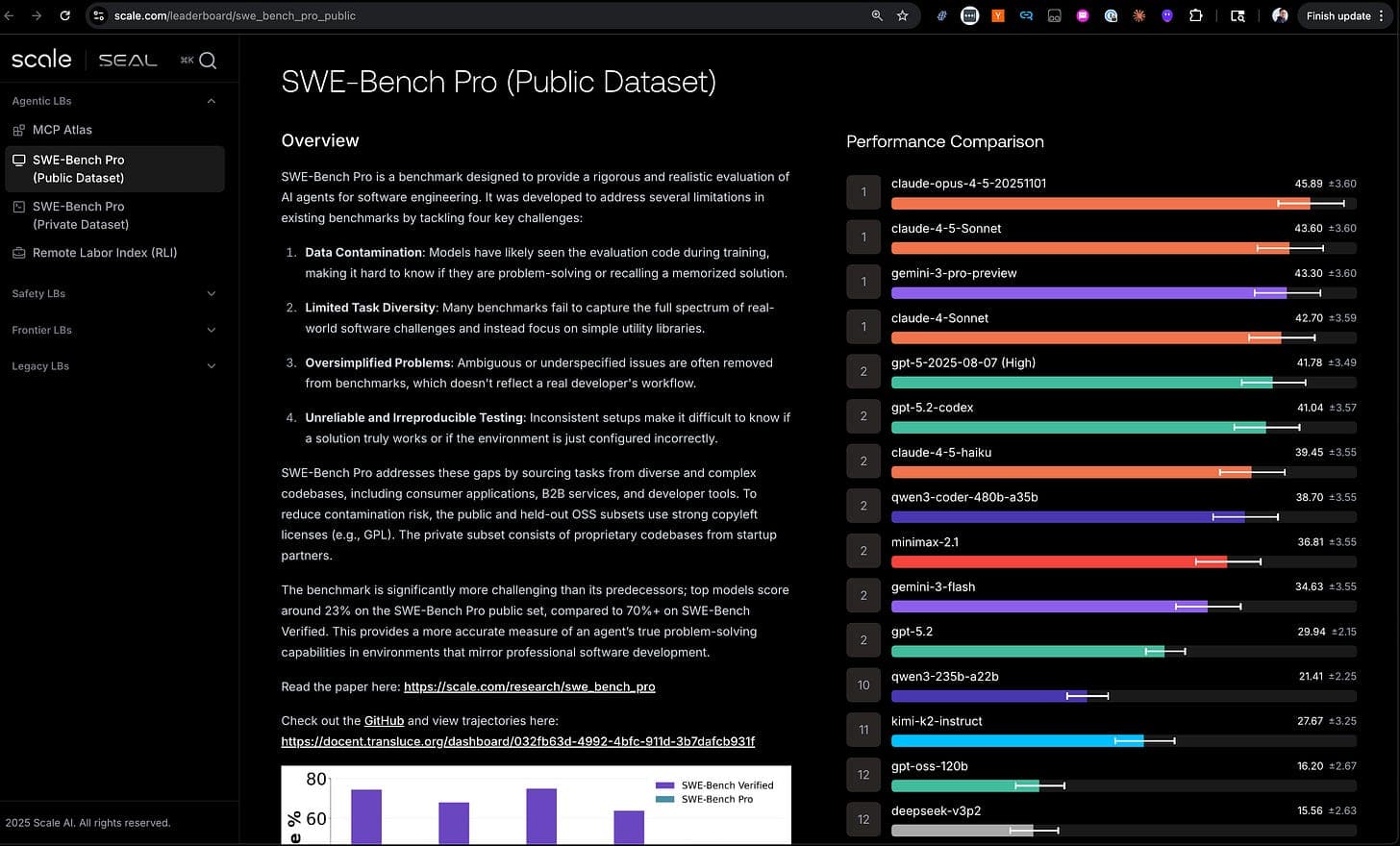
A fundamental architectural schism is defining the next generation of AI agents. It’s not about model size or training data, but about the harness—the infrastructure layer that wraps a large language model (LLM) to transform it from a stateless predictor into a capable, multi-step agent. Major players—Anthropic, OpenAI, CrewAI, and LangChain—are placing radically different bets on how much of this scaffolding should exist, a decision that directly dictates performance, control, and future-proofing.
Key Takeaways
- A central debate in agent engineering pits a 'thin harness' approach (Anthropic) against 'thick harness' designs (LangGraph).
- The infrastructure layer, not the model, is becoming the primary product differentiator.
The Spectrum of Control: From Thin Loops to Thick Graphs
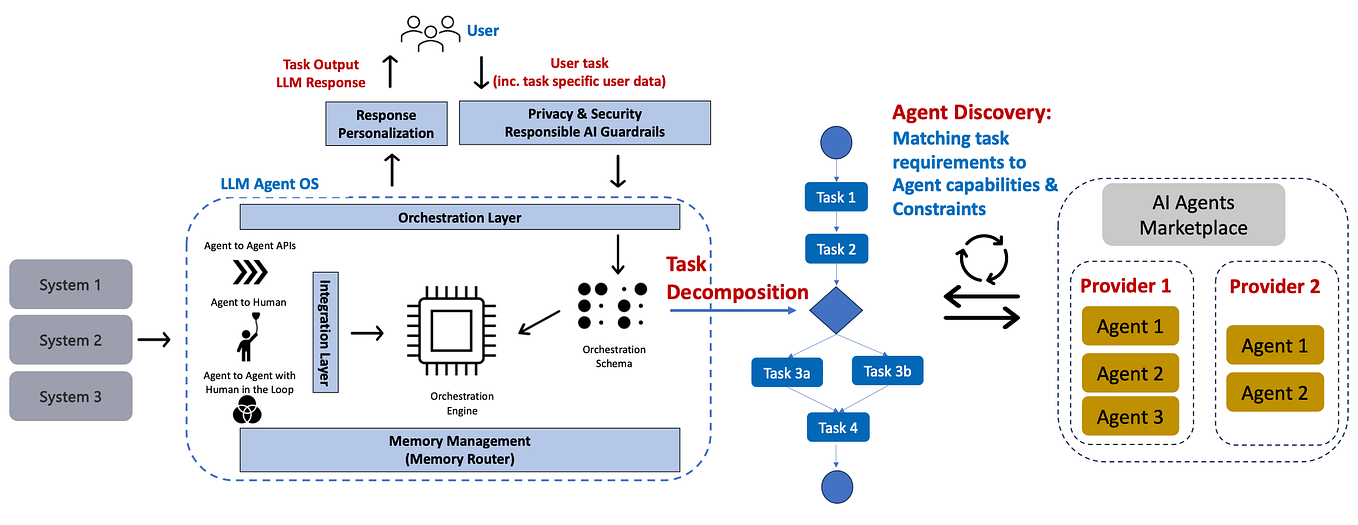
The core agreement, as articulated in the analysis, is that the model is not the product; the infrastructure around it is. The disagreement is on the density of that infrastructure.
- Anthropic’s “Thin Harness” Bet: Anthropic advocates for a minimalist “dumb loop.” The harness assembles the prompt, calls the model (Claude), executes its tool calls, and repeats. All planning, reasoning, and decision-making is pushed to the model. Their thesis is simple: as models grow more capable, the surrounding infrastructure should shrink, not expand.
- OpenAI’s “Code-First” Middle Ground: OpenAI’s recently launched Agents SDK takes a similar model-centric view but adds more structural guardrails. Workflow logic lives in native Python, not a proprietary graph language, but the SDK introduces strict priority stacks for instructions, multiple orchestration modes, and explicit patterns for agent handoff.
- CrewAI’s Deterministic Backbone: CrewAI introduces a split architecture. Its Flows layer provides hard-coded logic for routing and validation, ensuring deterministic control. Its Crews handle autonomous, LLM-driven tasks. This creates pockets of intelligence within a framework of explicit control.
- LangChain/LangGraph’s “Thick Harness” Philosophy: At the opposite end of the spectrum, LangGraph encodes the agent’s logic directly into the harness. Every decision point is a node in a graph; every transition is a defined edge. Multi-step planning, routing, and workflow state are managed by the infrastructure, not left to the model’s discretion.
The Scaffolding Principle: Build to Remove
The most compelling metaphor for this debate is construction scaffolding. It is temporary infrastructure that enables workers (the LLM) to reach heights they otherwise couldn’t. The goal is to remove it as the building (the model’s capabilities) is completed.
This pattern is observable in practice. AI startup Manus reportedly rebuilt its agent five times in six months, each iteration stripping away complexity—turning complex tool definitions into simple shell commands, eliminating “management agents” in favor of basic handoffs. Similarly, Anthropic has systematically deleted planning steps from Claude Code’s harness as new model versions internalize those capabilities.
The Critical Catch: Model-Harness Co-Dependence
However, a significant complication has emerged: models are now trained with specific harnesses in the loop. Claude Code’s model learned to reason using the exact scaffolding it was built with. Changing or removing that scaffolding can cause performance to drop—the worker was trained on that specific support structure.
This creates a delicate engineering challenge: build scaffolding designed to be removed, but remove it carefully and in sync with model improvements.
Performance Proof: The Harness is the Differentiator
The ultimate test for any agent system is the “future-proofing test”: can you drop in a more powerful model and see improved performance without adding harness complexity?
The power of the harness itself was demonstrated starkly by LangChain. On the SWE-Bench derivative benchmark TerminalBench 2.0, LangChain changed only the infrastructure—using the same underlying model and weights—and its ranking jumped from outside the top 30 to 5th place. The model didn’t change. The scaffolding did.
Key Architectural Trade-Offs
Thin Harness (Anthropic) Model-as-brain Low High Open-ended tasks, rapid model iteration Thick Harness (LangGraph) Logic-in-infrastructure High Lower Complex, deterministic workflows, audit trails Middle Ground (OpenAI, CrewAI) Structured autonomy Medium Medium Balanced applications needing reliability & smartsWhat This Means for Practitioners
Choosing an agent framework is no longer just about API convenience. It is a foundational architectural decision with long-term implications:
- For prototyping and research: A thin harness allows you to test the raw reasoning ceiling of your model but may produce less reliable, deterministic outputs.
- For production systems requiring reliability: A thicker harness provides guardrails, predictable state management, and easier debugging, but may limit the model’s novel problem-solving.
- For forward compatibility: Your harness design should anticipate being simplified. Avoid encoding logic that a smarter model should handle natively. The goal is to make the scaffolding temporary.
gentic.news Analysis
This debate crystallizes a maturation in the AI stack. For years, the focus was almost exclusively on the model—bigger, better, cheaper. The launch of the OpenAI o1 model family in late 2024, with its internal chain-of-thought, was a peak of that trend. Now, the industry is recognizing that the orchestration layer is where most real-world value is captured and where fierce competition is settling.
This aligns with the strategic pivot we’ve seen from LangChain, which, following its 2025 funding round, has doubled down on LangGraph as its core enterprise product. Conversely, Anthropic’s bet is a direct extension of its core philosophy of building capable, honest models—trust the AI. OpenAI’s middle path reflects its dual identity as both a frontier research lab and a platform business serving millions of developers.
The co-dependence of model and harness presents a new training challenge. We may soon see model providers like Anthropic and OpenAI offer “harness-aware fine-tuning” or release model variants explicitly optimized for their own SDK’s scaffolding, locking developers deeper into their ecosystems. The alternative is open frameworks that remain harness-agnostic, a space where projects like CrewAI are competing.
The terminal benchmark results are the most actionable data point for engineers: before switching models, try optimizing your harness. The infrastructure is not just glue; it is the chassis that determines how the engine’s power is delivered to the road.
Frequently Asked Questions
What is an AI agent harness?
An AI agent harness, or scaffolding, is the infrastructure code that wraps a large language model (LLM) to enable multi-step reasoning, tool use, memory, and state management. It transforms a single-turn LLM call into a persistent, capable agent that can execute complex tasks.
Which agent framework is the best?
There is no single “best” framework. The choice depends on your priority. Choose a thin harness (like Anthropic’s approach) for maximizing model flexibility and reasoning on open-ended tasks. Choose a thick harness (like LangGraph) for complex, deterministic workflows where control, auditability, and reliability are critical. Middle-ground options (OpenAI Agents SDK, CrewAI) offer a balance.
Why does changing the harness improve performance without changing the model?
The harness manages critical functions like planning, state tracking, and tool selection. A more efficient harness can provide the model with better context, reduce prompt overhead, make more optimal routing decisions, and prevent reasoning errors. It optimizes the environment in which the model operates, letting the same underlying intelligence produce better results.
What is the “future-proofing test” for an agent system?
The future-proofing test asks: if you replace your current LLM with a more powerful one (e.g., a newer, smarter model), does the agent’s performance improve without requiring you to add more complexity or logic to the harness? A well-designed, thin harness should pass this test, as it relies on the model’s intelligence. A overly complex, thick harness may not, as the model may be constrained by rigid infrastructure.