Key Takeaways
- Airbnb engineers detail the construction of a massive, internally operated metrics storage system.
- The system ingests 50 million samples per second, manages 1.3 billion active time series, and stores 2.5 petabytes of data, overcoming challenges in tenancy, shuffle sharding, and observability at scale.
What Happened
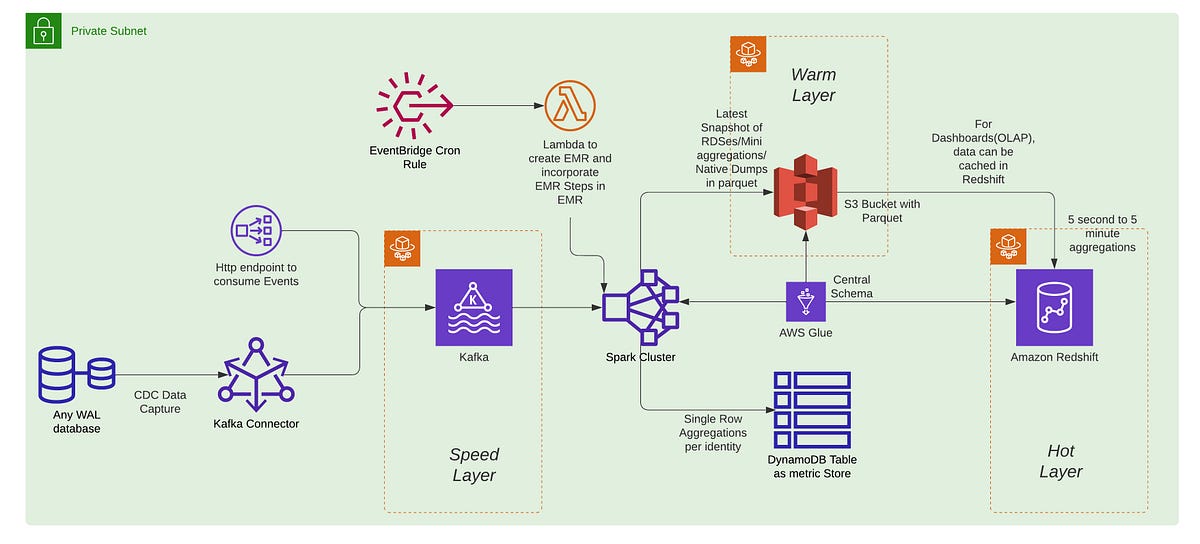
Airbnb has publicly detailed the engineering behind its new, internally built metrics storage system. Faced with an observability data deluge—1.3 billion active time series and 50 million samples ingested every second—the company moved from a hosted provider to a custom solution. The core mandate was to persist and serve this data (totaling 2.5 petabytes) performantly and reliably. The blog post serves as a technical case study, focusing on the architectural decisions made to achieve fault tolerance and manage multi-tenancy at this extreme scale.
Technical Details: Shuffle Sharding, Tenancy, and Guardrails
The engineering challenges centered on isolating workloads and preventing systemic failures. Airbnb's solution hinged on several key techniques:
- Application-Centric Tenancy: Instead of organizing data by team (which changes frequently), Airbnb assigned a "tenant" to each of its roughly 1,000 services. This provided stable attribution for metric growth and laid groundwork for future chargeback models.
- Shuffle Sharding for Fault Isolation: This technique ensures each tenant writes to and reads from a random, unique subset of storage and query nodes. The primary benefit is fault containment: a DDoS attack or failure impacting one tenant's assigned shards leaves other tenants' data on unaffected shards intact. This gives each tenant a near-single-tenant experience within a shared, cost-efficient cluster.
- Comprehensive Guardrails: To protect the system from unpredictable demand, Airbnb implemented strict, tenant-level limits. These include caps on the number of time series emitted, ingestion rates, and query payloads (e.g., limiting fetches to under 5,000 series or 500MB of data per query).
- Multi-Cluster Strategy for Reduced Blast Radius: After stabilizing a single, highly reliable cluster, the strategy evolved to distribute tenants across multiple clusters. Dedicated clusters for specialized workloads (like compute infrastructure) ensure a failure in one area doesn't cascade to others, aiming for over 99.9% availability.
Retail & Luxury Implications: The Foundation for AI Observability
While not about AI models directly, this engineering work is foundational for any enterprise, including luxury retailers, running AI at scale. The implications are indirect but critical:
Observability for AI Systems: Modern retail AI—from dynamic pricing engines and demand forecasting models to personalized recommendation agents and computer vision for inventory—generates massive volumes of operational metrics. Tracking model performance, latency, drift, and error rates in real-time requires a metrics backend capable of Airbnb-like scale. Without a robust system, you are "flying blind" as your AI estate grows.
Infrastructure for Agentic AI: The trend in retail AI is moving from static models to agentic systems that perform complex, multi-step tasks. As covered in our related article on RAG vs Fine-Tuning, and the recent declaration of the end of the 'RAG era' for agents, these systems are inherently stateful and generate complex telemetry. Airbnb's approach to shuffle sharding and tenant isolation is a blueprint for how to host multiple, independent AI agent workloads without them interfering with each other.
Chargeback and Cost Attribution: As AI development decentralizes across brand houses and digital teams, the ability to attribute infrastructure cost (compute, storage, query load) to specific services or applications becomes essential. Airbnb's tenant model, designed with chargeback in mind, is directly applicable to managing the cost of internal AI platforms.
In essence, before a luxury group can deploy AI agents that manage VIP client interactions or supply chain orchestration at scale, it must have the industrial-grade observability plumbing to support them. Airbnb's post is a masterclass in building that plumbing.








