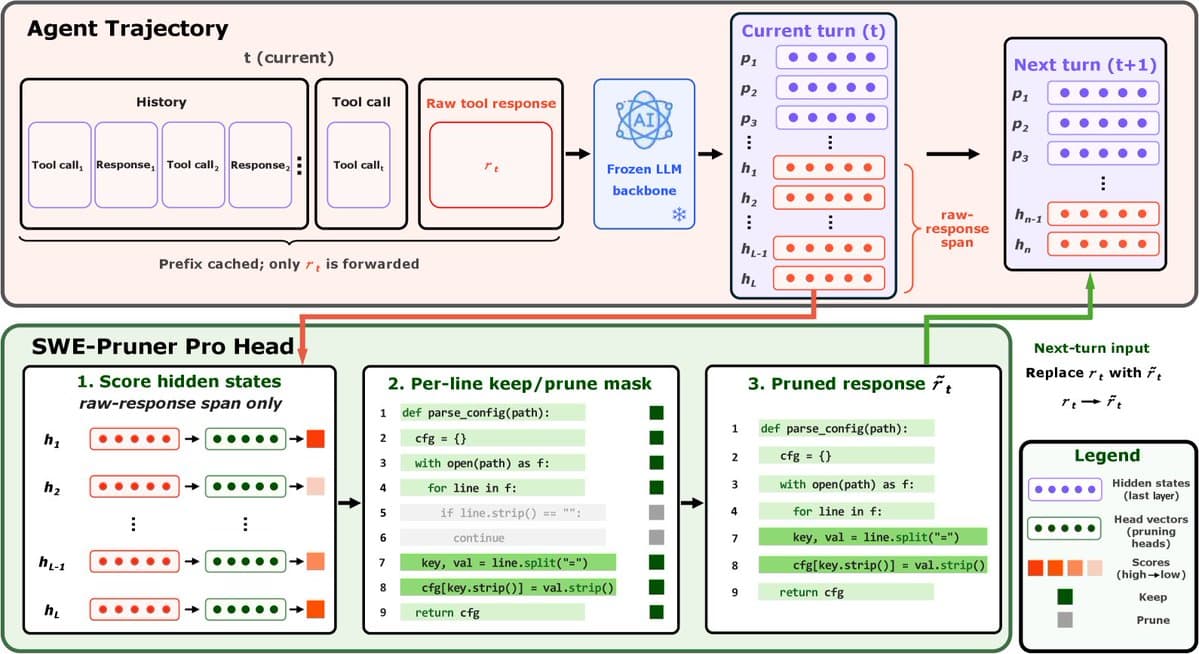
AI engineer and builder Akshay Pachaar has proposed a fundamental shift in how to architect large language model (LLM) agents, moving from a model-centric to a harness-centric design. In a detailed conceptual thread, he argues that the prevailing mental model of "a model with tools bolted on" is flawed. Instead, he posits that the core intelligence should be deliberately pushed outward from a thin LLM, with a runtime harness composing these externalized capabilities.
Pachaar is now building a minimal, open-source implementation of this harness architecture from scratch, promising a didactic and easy-to-read codebase with "no magic."
Key Takeaways
- AI engineer Akshay Pachaar outlined a novel 'harness' architecture for LLM agents that externalizes intelligence into memory, skills, and protocols.
- He is building a minimal, didactic open-source implementation of this design.
The Core Inversion: From Model-Centric to Harness-Centric
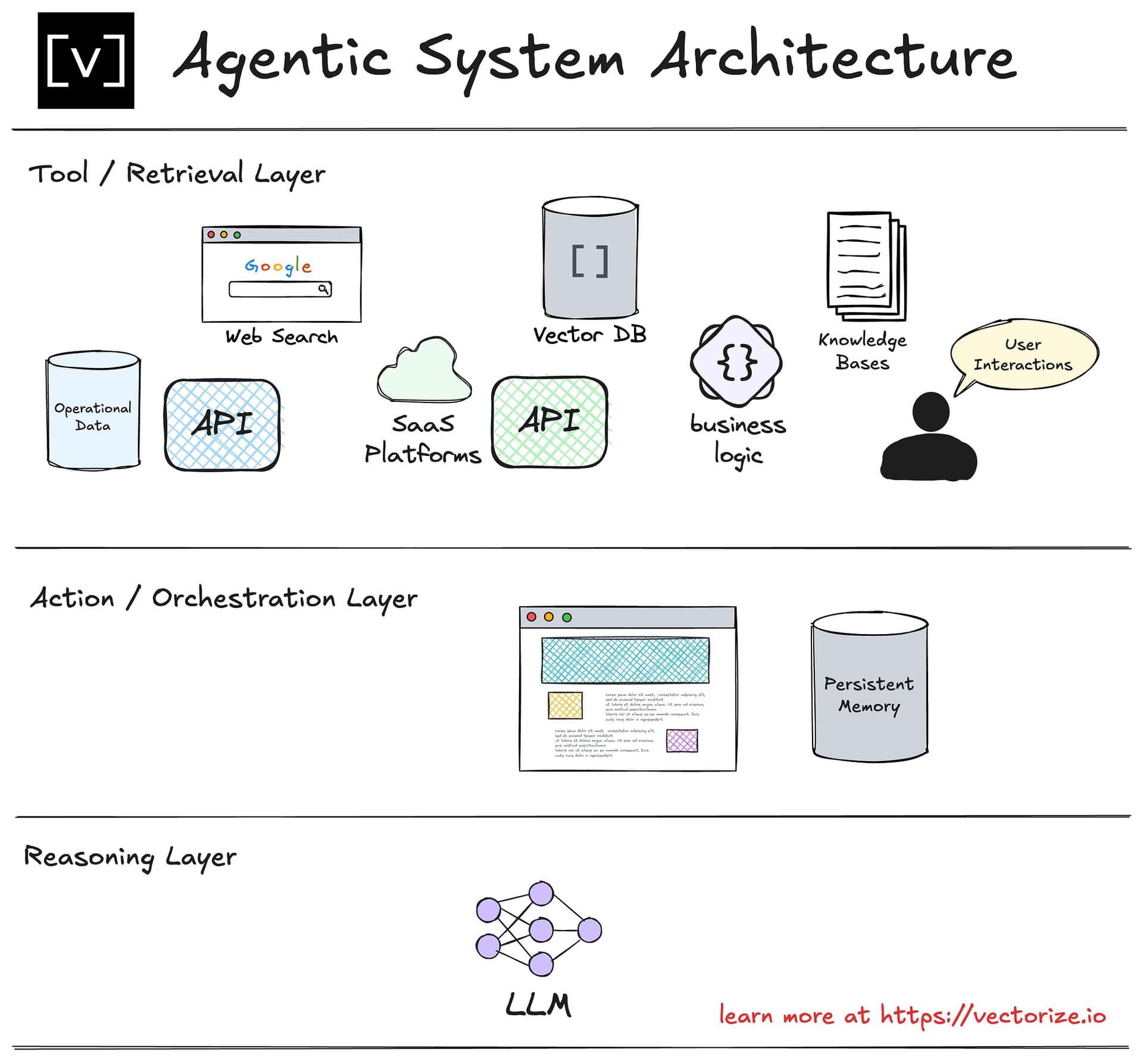
The central thesis challenges a common assumption. Most agent frameworks, from LangChain to LlamaIndex and AutoGen, conceptually start with an LLM and then attach tools, memory, and planning loops. Pachaar's architecture inverts this relationship.
The Thin Model Core: The LLM itself becomes a deliberately limited component. Its primary role is not to store all knowledge or procedures internally but to serve as a general reasoning engine directed by the harness.
The Intelligent Harness: The harness becomes the central orchestrator. It manages the flow of information and tasks between three key externalized dimensions and the core model, applying necessary governance at the boundaries.
The Three Externalized Dimensions
Pachaar defines three orbits around the harness core, each holding a specific type of intelligence that should not be burdened onto the model's weights or context window.
1. Memory
This holds state the model shouldn't carry. It's subdivided by lifecycle and purpose:
- Working Context: The immediate state of the current task.
- Semantic Knowledge: Factual databases and retrieved information.
- Episodic Experience: A record of past actions and outcomes.
- Personalized Memory: User-specific preferences and history.
2. Skills
This holds procedural knowledge—the "how-to" of specific tasks:
- Operational Procedures: Code for executing specific actions (e.g., calling an API, running a calculation).
- Decision Heuristics: Rule-based or learned guidelines for making choices.
- Normative Constraints: Guardrails and safety policies that define acceptable behavior.
3. Protocols
This holds the interaction contracts, defining how the agent communicates with different entities:
- Agent-to-User: The dialogue and instruction-following interface.
- Agent-to-Agent: Coordination and communication rules for multi-agent systems.
- Agent-to-Tools: The standardized schema for tool discovery, calling, and handling outputs.
The Critical Mediators
Between the core harness and these external modules sit what Pachaar calls mediators. These are the subsystems that govern all interaction, ensuring safety, efficiency, and correctness:
- Sandboxing: Isolating tool execution for security.
- Observability: Logging and tracing the agent's decision path.
- Compression: Summarizing or filtering information flowing to and from the model to manage context limits.
- Evaluation: Continuously assessing the quality of actions and outputs.
- Approval Loops: Human-in-the-loop or automated checkpoints for critical decisions.
- Sub-agent Orchestration: Managing hierarchies or teams of specialized agents.
A Practical Framework for Design
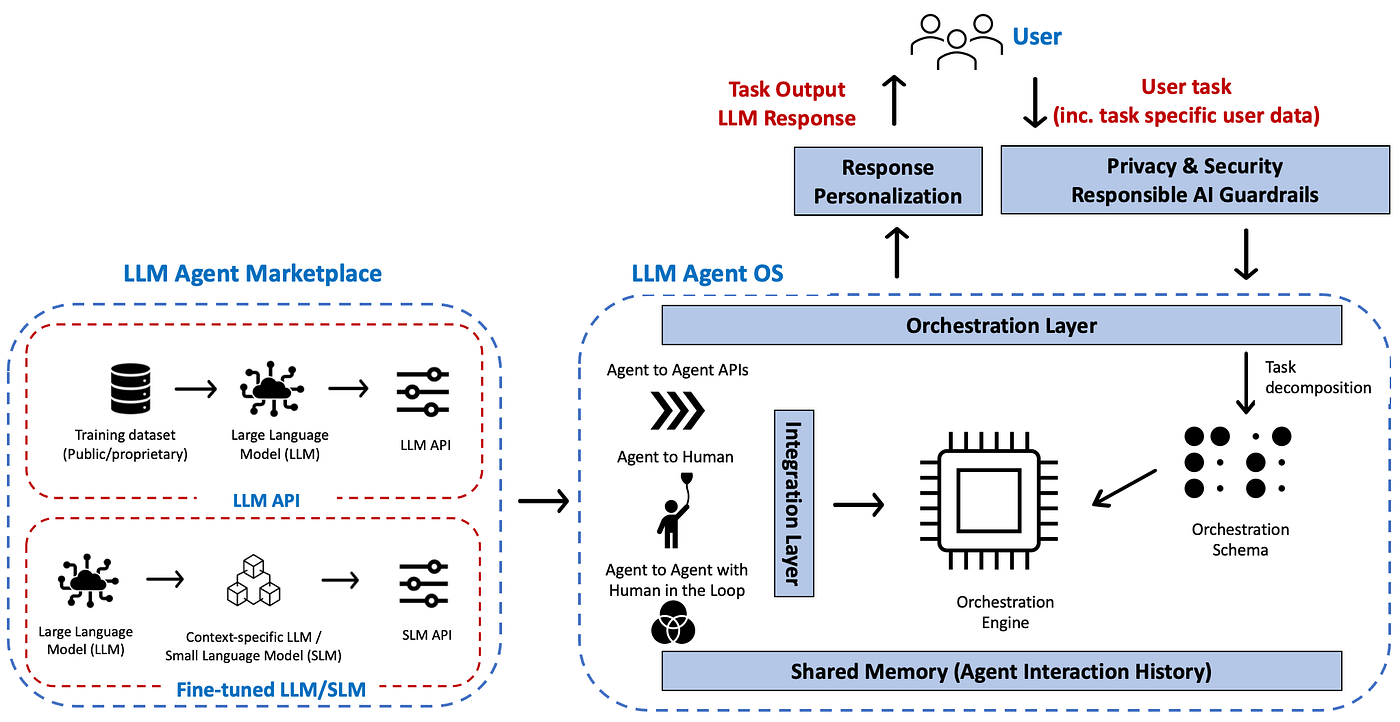
The power of this architecture, according to Pachaar, is that it provides a clear decision framework for engineers: "for any new capability, where should it live?"
- Stable knowledge → Memory
- Learned playbooks → Skills
- Communication contracts → Protocols
- Loop governance → Mediators
"Harness design becomes a question of what to externalize, and how to mediate it," he concludes.
The Coming Open-Source Implementation
Pachaar has announced he is actively building a "minimal agent harness from scratch" based on these principles. The goals are didactic clarity and the elimination of opaque abstractions ("no magic"). This project aims to serve as a reference implementation for this inverted architectural philosophy, contrasting with more monolithic or model-heavy frameworks. An open-source release is promised "soon."
gentic.news Analysis
Pachaar's conceptual framework arrives amid a significant industry trend toward decomposing and specializing the components of AI systems. His emphasis on a "thin model" aligns with the rising practice of using smaller, cheaper, and faster models for core reasoning when they are effectively guided by robust external systems—a trend we noted in our coverage of Google's Gemini 1.5 Flash and its optimization for agentic workflows. The explicit separation of Skills and Protocols also resonates with the direction of OpenAI's recently launched "structured outputs" feature for the GPT-4o API, which moves contract definition from prompt engineering to a formal API layer.
This architectural thinking directly challenges the approach of earlier frameworks like LangChain, which began as a thick wrapper around LLMs and has been criticized for its complexity. Pachaar's design philosophy shares more DNA with emerging, leaner libraries focused on control and transparency. His focus on Mediators for sandboxing and approval loops touches on the critical production concerns—safety, cost, and reliability—that have stalled many agent projects, a topic we explored in depth following Scale AI's launch of its Agent Evaluation platform.
If Pachaar's open-source harness delivers on its promise of clarity and minimalism, it could become a influential template for developers building mission-critical, auditable agents, especially in enterprise contexts where governance is non-negotiable. The success will hinge on whether the simplified architecture can match the functionality and ease-of-use of more established, but arguably bloated, frameworks.
Frequently Asked Questions
What is an LLM agent harness?
An LLM agent harness is the surrounding software architecture that manages a core large language model. It handles memory, tool use, safety checks, and interaction protocols, orchestrating the LLM's reasoning within a larger, reliable system. Akshay Pachaar's concept specifically inverts the standard design by making the harness the primary intelligence composer and the LLM a thinner component.
How is this different from frameworks like LangChain or AutoGen?
Traditional frameworks like LangChain often start with the LLM as the central component and add capabilities around it. Pachaar's proposed architecture makes the harness the central component, with the LLM as one of several resources it manages. The goal is a clearer separation of concerns (memory, skills, protocols) and explicit governance via mediators, aiming for greater transparency and control than more monolithic frameworks.
What are the practical benefits of this 'harness' architecture?
The main proposed benefits are improved system design clarity, easier auditing and observability, better cost control (by using smaller, cheaper models), and more robust safety through formalized mediators for sandboxing and approval. It provides a blueprint for deciding where new code or knowledge should reside in an agent system.
When will the open-source harness be available?
Akshay Pachaar has stated he is building it now and will open-source it "soon." He describes it as a minimal, didactic implementation designed to be easy to read and understand, serving as a reference for the harness-centric design philosophy.