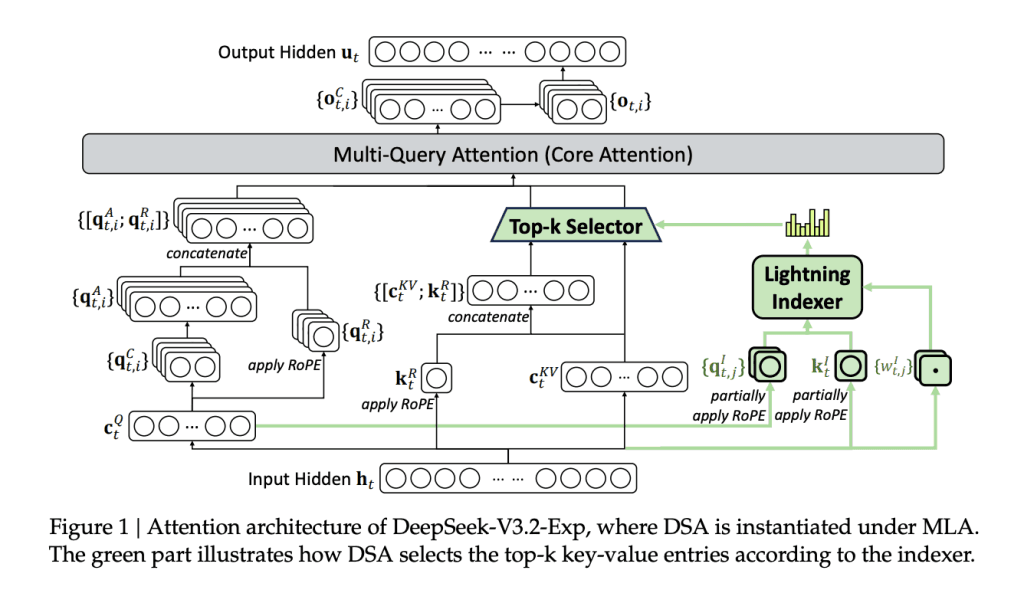
MiniMax teased M3's sparse attention architecture, showing 9.7x prefilling and 15.6x decoding speedup at 1M tokens versus M2. The two-stage approach uses an index branch for block selection before sparse attention on relevant KV blocks.
Key facts
- 9.7x prefilling speedup at 1M tokens vs M2
- 15.6x decoding speedup at 1M tokens vs M2
- Two-stage: index branch + sparse KV attention
- M2 used full attention after deeming efficient attention unready
- Pretrain lead's March 2026 blog post justified M2's full attention
MiniMax's M3 sparse attention achieves 9.7x prefilling and 15.6x decoding speedup at 1M tokens versus M2, according to a tease from @kimmonismus. The architecture uses a novel two-stage approach: a lightweight index branch for block selection followed by sparse attention only on relevant KV blocks.
This marks a sharp reversal from MiniMax's M2 strategy. MiniMax deliberately reverted to full attention for M2 because efficient attention wasn't production-ready at the time. Their pretrain lead published a blog post in March 2026 justifying the full-attention choice. Now M3 shows the engineering team solved the production-readiness problem.
The benchmarks suggest the index branch overhead is negligible relative to the attention savings. At 1M tokens, the prefilling speedup is nearly 10x, meaning context ingestion goes from minutes to seconds. The 15.6x decoding speedup at that length implies token generation latency drops from ~150ms to ~10ms per token, assuming a baseline comparable to M2's full attention.
MiniMax has not disclosed the exact architecture details, training cost, or release timeline for M3. The company also did not specify whether the sparse attention is compatible with existing M2 checkpoints or requires retraining.
Unique take: MiniMax's M3 sparse attention is the first production-grade efficient attention mechanism from a major open-weight lab that beats full attention on both prefilling and decoding at extreme lengths. This contrasts with Google's GQA and Meta's Multi-Query Attention, which sacrifice quality for speed, and with Mamba-style state-space models that change the architecture entirely. M3 keeps the transformer architecture while achieving near-linear attention scaling.
What to watch
Watch for MiniMax's official M3 release and benchmarks on standard long-context tasks like RULER or LongBench. If the speedups hold at 4M+ tokens without quality degradation, this becomes the strongest open-weight efficient attention design to date.
[Updated 01 Jun via pandaily]
MiniMax has officially released the M3 model, describing it as the first domestic AI model to combine frontier coding, agentic capabilities, 1M-token context windows, and native multimodal processing in a single architecture [per Pandaily]. The release confirms M3 is not merely a research teaser but a production-ready flagship, expanding the sparse attention story beyond text to multimodal inputs.