MiniMax M3 introduces sparse attention, a 1M context window, and multimodality. Together AI handled the serving infrastructure to deliver fast inference.
Key facts
- Model: MiniMax M3 with sparse attention.
- Context window: 1 million tokens.
- Multimodal: text, images, audio support.
- Serving partner: Together AI for inference.
- No benchmark or parameter count disclosed.
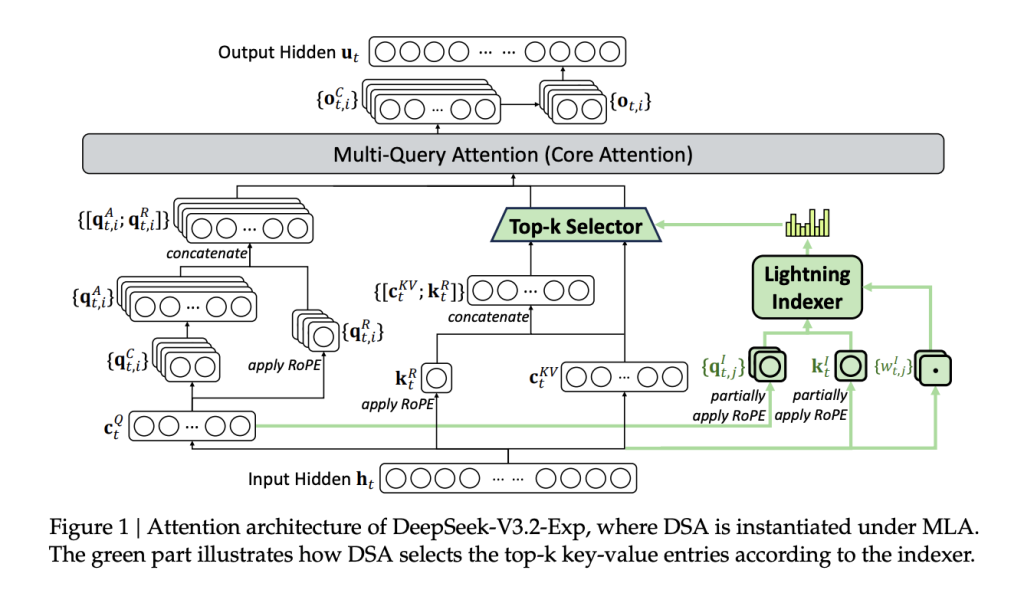
MiniMax's M3 model, announced via a post by Skyler Miao on X @MiniMax_AI, combines three technical innovations: sparse attention, a 1M-token context window, and multimodal input processing. The sparse attention mechanism reduces the quadratic complexity of standard full attention, enabling the model to handle sequences up to 1 million tokens without proportional compute scaling. This makes M3 suitable for tasks like long-document summarization, codebase analysis, and retrieval-augmented generation over large corpora.
Together AI, a cloud provider specializing in AI inference, contributed the serving layer to make M3 fast at production scale. The partnership highlights a growing trend: model developers focusing on architecture while infrastructure partners optimize deployment. Together's inference stack likely uses custom kernels and batching to exploit M3's sparse attention sparsity, achieving latency competitive with dense models of similar size.
Sparse Attention and Context Scaling
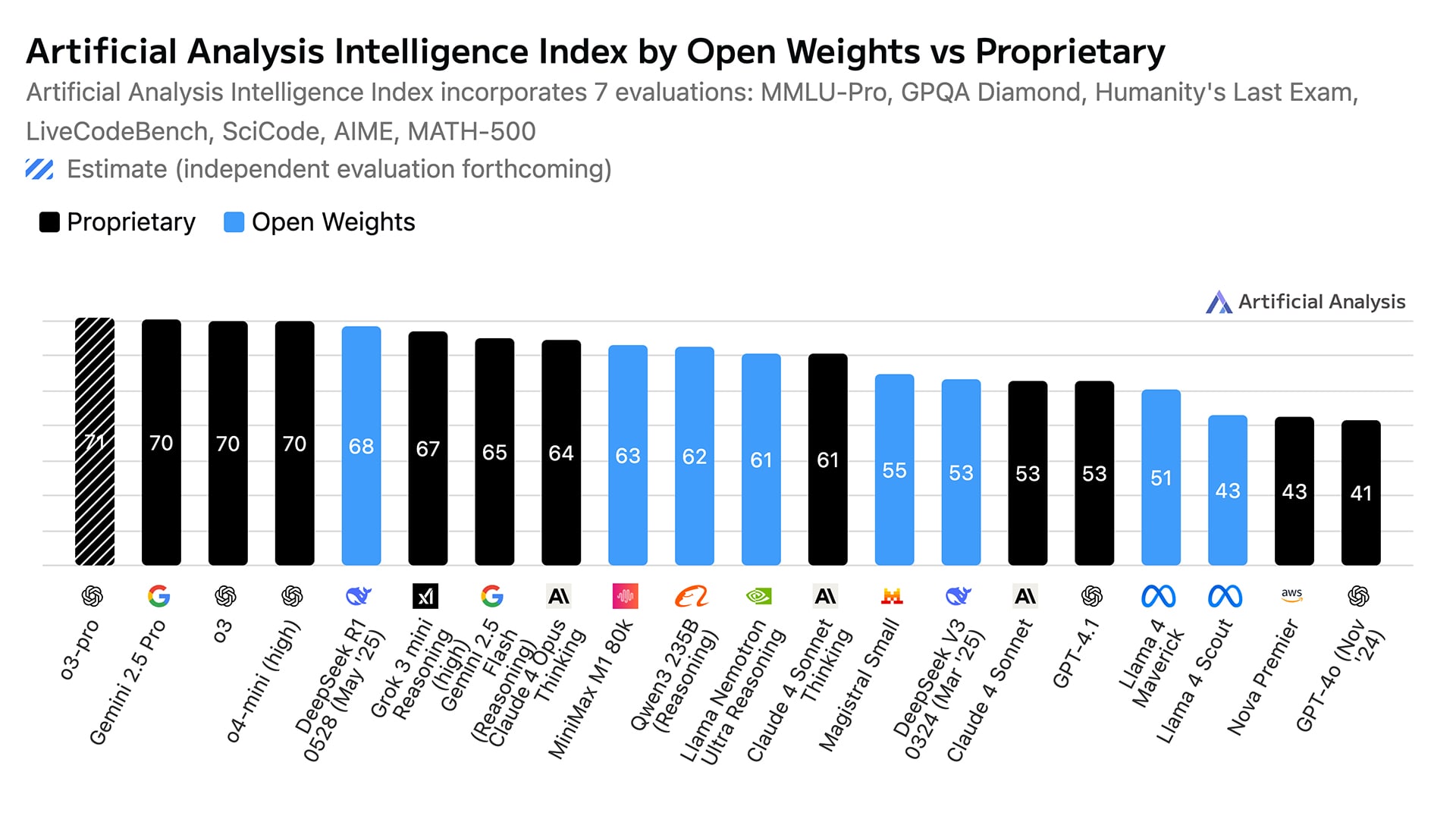
Sparse attention has been explored in earlier models like Longformer (Beltagy et al. 2020) and BigBird (Zaheer et al. 2020), but M3's implementation appears to target real-time inference at 1M tokens. The exact sparsity pattern (e.g., fixed stride, dilated sliding window, or learned) was not disclosed. A 1M context window places M3 alongside GPT-4 (128K tokens) and Claude 3 (200K tokens) but exceeds them by 5-8x, though benchmark comparisons are absent from the announcement.
Multimodal Capabilities
M3 supports multiple modalities including text, images, and audio, per the source. This aligns with the industry shift toward unified models, as seen with Gemini 1.5 Pro and GPT-4V. No specific benchmarks or performance numbers were provided for multimodal tasks.
Serving Infrastructure
Together AI's role is critical: without optimized inference, sparse attention can be slower than dense attention due to irregular memory access patterns. Together's team likely implemented fused kernels and speculative decoding to mask the overhead. The result is a model that, according to the announcement, runs "fast" at scale.
Missing Details
The source does not disclose model size (parameter count), training data, open-source availability, pricing, or benchmark results. These omissions make it difficult to assess M3's practical value relative to existing models. The announcement is promotional rather than technical, leaving many questions unanswered.
What to watch
Watch for benchmark results (e.g., RULER, Needle-in-a-Haystack, MMLU) and open-source availability. If M3 is released under a permissive license, it could challenge Llama 3.1 and Mistral in long-context tasks. Also monitor Together AI's inference pricing and latency benchmarks.