Anthropic's engineering blog introduces sandboxing that limits agent permissions based on their capabilities. The approach restricts destructive actions as agents gain more autonomy in products like Claude.
Key facts
- Anthropic sandboxes agents by capability level
- Permissions evolve with agent actions, not static roles
- Limits scope of potentially destructive actions
- Blog post does not disclose benchmark results
- Applies to Anthropic's own products like Claude
Anthropic published a blog post outlining a new access-control framework for AI agents: permissions evolve with the agent's demonstrated capabilities, not static roles. [According to @AnthropicAI] In Anthropic's own products, this is implemented via sandboxing, which limits the scope of any potentially destructive actions. The post argues that as agents become more capable—able to write code, execute commands, or access external services—the access and permissions granted should scale accordingly, not remain fixed at a single level.
The unique take here is that Anthropic is moving beyond binary permission models (agent vs. no agent) toward continuous, capability-gated access. This mirrors how human access control works in practice—junior engineers get read-only access, senior engineers get write access—but applied to AI agents that can escalate their own capabilities mid-session. The blog post does not disclose specific implementation details, benchmark results, or which Claude models this applies to.
This is a structural departure from the industry norm. Most AI agent frameworks today (LangChain, AutoGPT, Microsoft Copilot) use static permission scopes defined at deployment time. Anthropic's approach implies runtime permission escalation based on agent behavior, which introduces both safety benefits (containing a misbehaving agent) and attack-surface risks (adversarial prompts that trigger capability escalation). The post does not address how Anthropic measures agent capability or prevents gaming the escalation mechanism.
What to Watch
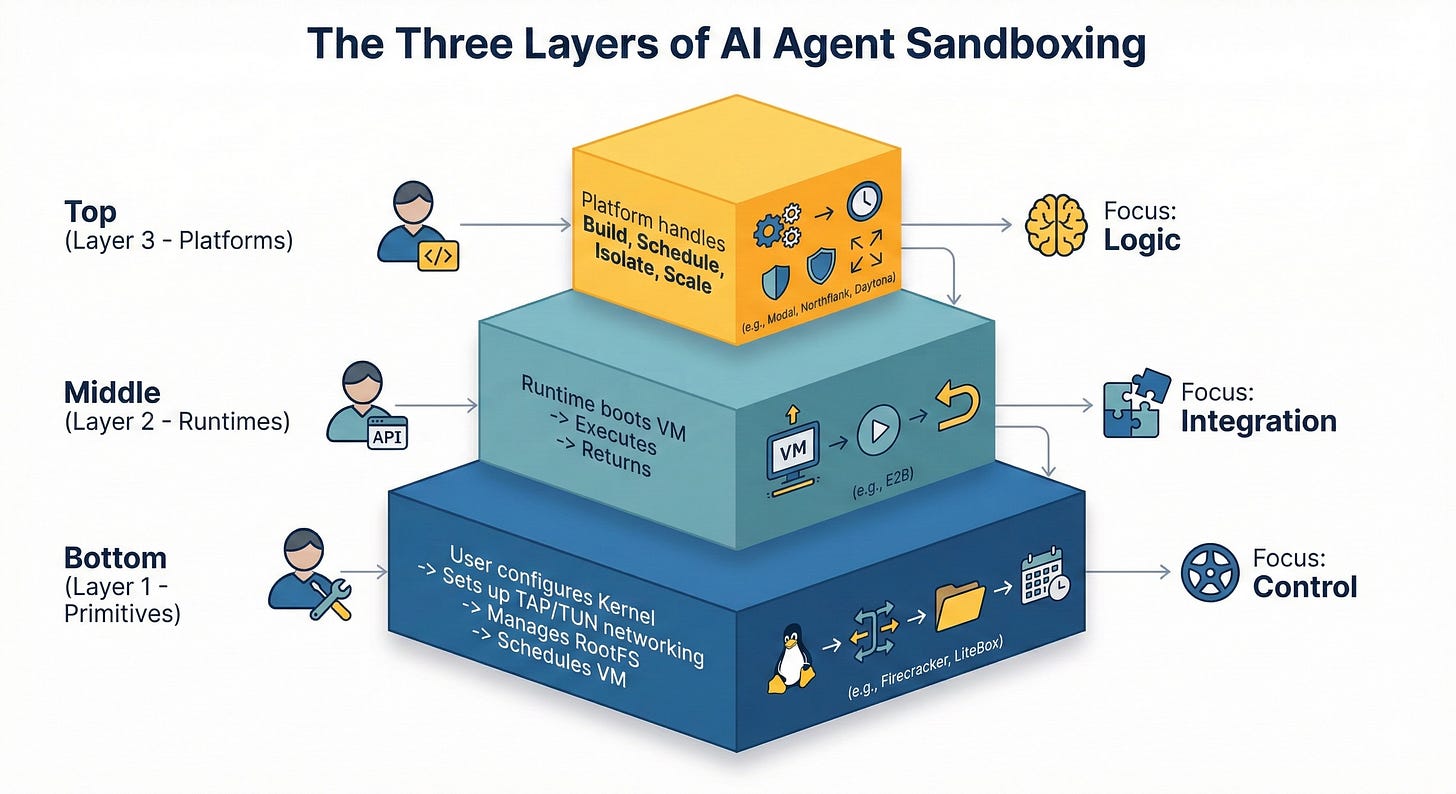
Watch for Anthropic to release technical details—how capability is measured, what escalation thresholds look like, and whether this is open-sourced or kept proprietary. Also watch for third-party audits or red-teaming results that test whether sandboxing can be bypassed via prompt injection.
What to watch
Watch for Anthropic to release technical details—how capability is measured, what escalation thresholds look like, and whether this is open-sourced or kept proprietary. Also watch for third-party audits or red-teaming results that test whether sandboxing can be bypassed via prompt injection.