As the artificial intelligence industry grapples with the diminishing returns of simply scaling up parameter counts, a fundamental architectural shift is emerging. Liquid AI's newly announced LFM2-24B-A2B model represents a significant departure from conventional Transformer designs, blending convolutional and attention mechanisms to address the critical scaling bottlenecks plaguing modern large language models.
The Scaling Crisis in Modern AI
The generative AI race has long operated on a "bigger is better" principle, with companies competing to build models with ever-increasing parameter counts. However, this approach has hit practical limits. Traditional Transformer architectures rely on Softmax Attention mechanisms that scale quadratically (O(N²)) with sequence length, creating massive computational and memory demands. As sequence lengths increase for more complex reasoning tasks, the Key-Value (KV) caches required devour VRAM, creating insurmountable bottlenecks for both training and inference.
This scaling crisis arrives at a critical moment for the AI industry. Recent studies have revealed concerning gaps in LLM capabilities, including inadequate responses to technology-facilitated abuse scenarios (2026-02-23) and the discovery of the "double-tap effect" where repeating prompts dramatically improves accuracy from 21% to 97% (2026-02-18). These findings suggest fundamental architectural limitations beyond mere parameter scaling.
The LFM2-24B-A2B Architecture: A Hybrid Solution
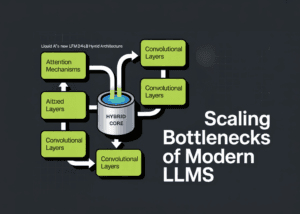
Liquid AI's breakthrough comes in the form of a carefully engineered hybrid architecture that strategically combines different computational approaches. The LFM2-24B-A2B employs a 1:3 ratio between two distinct layer types:
Base Layers: These utilize efficient gated short convolution blocks that excel at capturing local patterns and dependencies with linear computational complexity. Unlike attention mechanisms, convolutions don't suffer from quadratic scaling, making them ideal for processing long sequences efficiently.
Attention Layers: These employ Grouped Query Attention (GQA), a more memory-efficient variant of traditional attention that reduces the KV cache size while maintaining strong performance on tasks requiring global context understanding.
This architectural innovation represents more than just a technical tweak—it's a fundamental rethinking of how language models should be structured. By distributing computational responsibilities between specialized components, Liquid AI has created a model that maintains strong performance while dramatically improving efficiency.
Implications for the AI Industry
The timing of this development is particularly significant given the broader industry context. As artificial intelligence continues its rapid advancement, threatening traditional software models (2026-02-24), efficiency becomes a competitive differentiator. The LFM2-24B-A2B's hybrid approach offers several transformative implications:
Reduced Infrastructure Costs: By addressing the quadratic scaling problem, this architecture could significantly lower the computational resources required for both training and inference, potentially democratizing access to powerful AI capabilities.
Environmental Impact: The energy consumption of massive AI models has become a growing concern. More efficient architectures like Liquid AI's could substantially reduce the carbon footprint of AI development and deployment.
New Capabilities: The ability to process longer sequences more efficiently opens doors to more complex reasoning tasks, better document understanding, and improved multi-step problem solving—areas where current LLMs often struggle.
Commercial Viability: As AI increasingly competes with traditional SaaS solutions in the white-collar economy, efficiency improvements translate directly to competitive advantages in deployment costs and responsiveness.
The Future of AI Architecture
Liquid AI's hybrid approach suggests a future where AI development focuses less on brute-force scaling and more on architectural elegance. This shift mirrors historical transitions in computing, where specialized hardware and optimized algorithms eventually surpassed raw clock speed as the primary drivers of performance improvement.
The LFM2-24B-A2B model, with its 24 billion parameters, demonstrates that significant capabilities can be achieved without resorting to trillion-parameter behemoths. This could accelerate innovation by lowering the barrier to entry for organizations without massive computational resources.
As the industry continues to evolve, we can expect to see more experimentation with hybrid architectures, specialized components, and novel approaches to the fundamental challenges of language modeling. Liquid AI's contribution represents an important milestone in this journey—one that prioritizes intelligent design over indiscriminate scaling.
Source: MarkTechPost (2026-02-25)








