The Innovation — What the source reports
The source is a technical guide outlining the architecture and implementation of a multimodal product similarity engine specifically for fashion retail. The core premise is that identifying similar products is a foundational capability that powers numerous downstream applications, from personalized recommendations and visual search to inventory management and trend analysis.
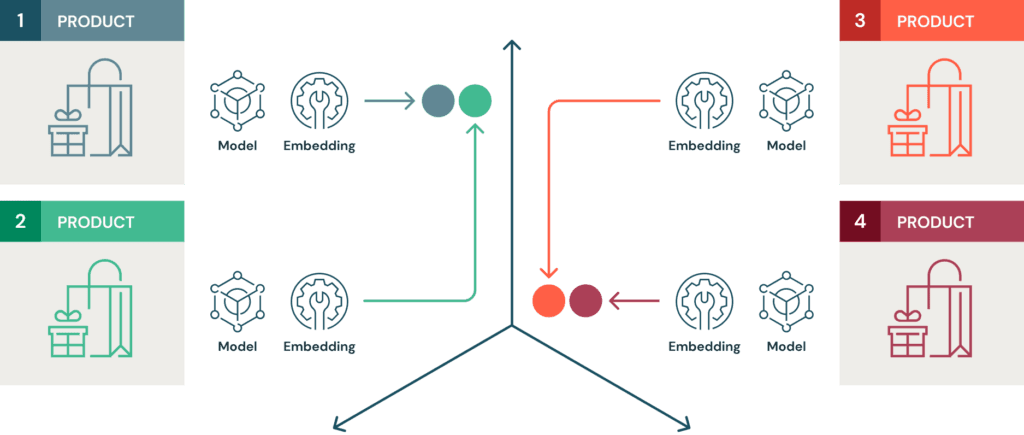
The proposed engine is "multimodal" because it generates and combines embeddings from both textual data (product titles, descriptions, attributes) and visual data (product images). By processing these two distinct data types through separate neural networks—typically a language model for text and a vision model like ResNet or CLIP for images—the system creates a unified vector representation for each product. These vectors are then indexed in a vector database, enabling fast similarity searches via nearest-neighbor algorithms.
The guide likely details the end-to-end pipeline: data ingestion from a product catalog, preprocessing, embedding generation, vector storage, and finally, the query interface. The ultimate output is a service that, given a query product (or even a user-uploaded image), returns a ranked list of the most similar items from the catalog based on their multimodal embeddings.
Why This Matters for Retail & Luxury — Concrete scenarios and departments
For luxury and premium retail, where product differentiation is subtle and curation is paramount, a robust similarity engine moves beyond a nice-to-have feature to become a critical operational tool.
- Enhanced Discovery & Recommendations: Move beyond simplistic "customers who bought this also bought" logic. A multimodal engine can understand that a "small saffiano leather crossbody bag" is visually and conceptually similar to a "compact grained calfskin pouch," even if the attribute tags differ. This powers "Find Similar" features, complete-the-look suggestions, and sophisticated recommendation widgets that understand style, material, and silhouette.
- Superior Visual Search: A customer can upload a street style photo or a screenshot from social media. The engine analyzes the visual query, finds products with similar visual characteristics (color, pattern, shape), and can refine results using any textual context provided, dramatically improving conversion from inspiration to purchase.
- Merchandising & Assortment Planning: Merchants can use the engine to audit their catalog for unintentional redundancies or identify gaps in their assortment. By querying a best-selling item, they can see if they have adequate coverage across similar styles or if they are missing a key variation.
- Customer Service & Styling: Personal stylists and customer service agents can use an internal tool powered by this engine to quickly find alternatives for out-of-stock items or suggest complementary pieces, providing a higher-touch, more knowledgeable service.
Business Impact — Quantified if available, honest if not
The source is a technical guide, so it does not provide proprietary business metrics. However, the business impact of deploying such a system can be inferred and is significant:
- Increased Average Order Value (AOV): By surfacing more relevant and visually-coherent alternatives or complements, the engine can directly encourage bundling and larger basket sizes.
- Higher Conversion Rates: Reducing search friction—whether a customer knows exactly what they want ("find similar") or only has a visual inspiration—shortens the path to purchase.
- Reduced Return Rates: When customers receive items that truly match their expectations (based on visual and descriptive similarity), the likelihood of returns due to "not as described" or "not as expected" decreases.
- Operational Efficiency: Automating product tagging and categorization using embedding clusters can reduce manual labor for merchandising teams.
The return on investment hinges on implementation quality, data cleanliness, and seamless integration into the user journey.
Implementation Approach — Technical requirements, complexity, effort
Building this engine is a mid-to-high complexity machine learning engineering project, not a simple plug-and-play solution. The guide outlines the core requirements:
- Data Pipeline: A robust pipeline to ingest and clean product catalog data (images, titles, descriptions, SKUs) is non-negotiable. For luxury brands, high-resolution, consistent product imagery is a major advantage.
- Model Selection: Choices must be made for the text encoder (e.g., Sentence-BERT, a fine-tuned BERT variant) and image encoder (e.g., CLIP, which is trained on image-text pairs and is particularly powerful for this cross-modal task, or a dedicated fashion-focused model like
facebookresearch/fashion_clip). - Embedding Generation & Fusion: The system must generate embeddings for all catalog items. A key design decision is how to fuse the text and image vectors—simple concatenation, weighted averaging, or more learned fusion mechanisms.
- Vector Database: Scaling to millions of SKUs requires a production-grade vector database like Pinecone, Weaviate, Qdrant, or Milvus for efficient approximate nearest neighbor (ANN) search.
- Serving Infrastructure: The final engine needs to be packaged as a scalable microservice (e.g., using FastAPI) that can handle real-time queries from front-end applications.
The effort spans data science, ML engineering, and backend development. Using managed services for embedding APIs and vector databases can reduce infrastructure complexity.
Governance & Risk Assessment — Privacy, bias, maturity level
- Maturity Level: The underlying technology (multimodal embeddings, vector search) is mature and battle-tested in tech giants. The challenge for retailers is in the implementation details and domain-specific tuning.
- Bias & Fairness: The engine will inherit and potentially amplify biases present in the training data of the base models (CLIP, etc.) and the retailer's own catalog. If a brand's historical imagery over-represents certain body types, ethnicities, or styles, the similarity results will be skewed. Regular auditing of results for diversity and fairness is crucial.
- Privacy: If the engine powers features using user-uploaded images, a clear data policy must govern the storage and use of those images. Typically, such images should be processed ephemerally for the search query and not stored permanently.
- Brand Dilution Risk: An overly aggressive "similar items" recommendation could surface lower-quality or off-brand products if not carefully constrained. The system must respect brand boundaries and price tiers, potentially requiring business rules layered on top of the pure similarity scores.
gentic.news Analysis
This hands-on guide arrives amidst a clear industry trend: the move from monolithic, legacy recommendation systems to modular, AI-native capabilities. As covered in our recent articles on frameworks like DIET, MCLMR, and LSA, the state of the art in recommender systems is rapidly advancing toward causal inference, lifelong learning, and dynamic personalization. A multimodal similarity engine is not the final destination but a critical, reusable component that can feed into these more sophisticated systems. It provides the foundational "understanding" of the product catalog.
The technical approach described aligns with the broader shift towards open, composable AI infrastructure. Interestingly, the implementation of such an engine—involving workflow orchestration for data processing, model inference, and indexing—is precisely the type of challenge that new open-source automation platforms like Sim aim to simplify. Following Sim's recent release and its subsequent update with a distributed KV cache engine, it's evident the tooling ecosystem is evolving to support the scalable deployment of such multimodal AI pipelines. For a luxury brand's AI team, the choice is between building and maintaining this entire pipeline in-house or leveraging a growing set of specialized platforms and managed services to accelerate time-to-value. The core competitive advantage will lie not in the generic embedding model, but in the proprietary product data, the nuanced business rules applied on top, and the seamless integration into a unique, brand-elevating digital experience.