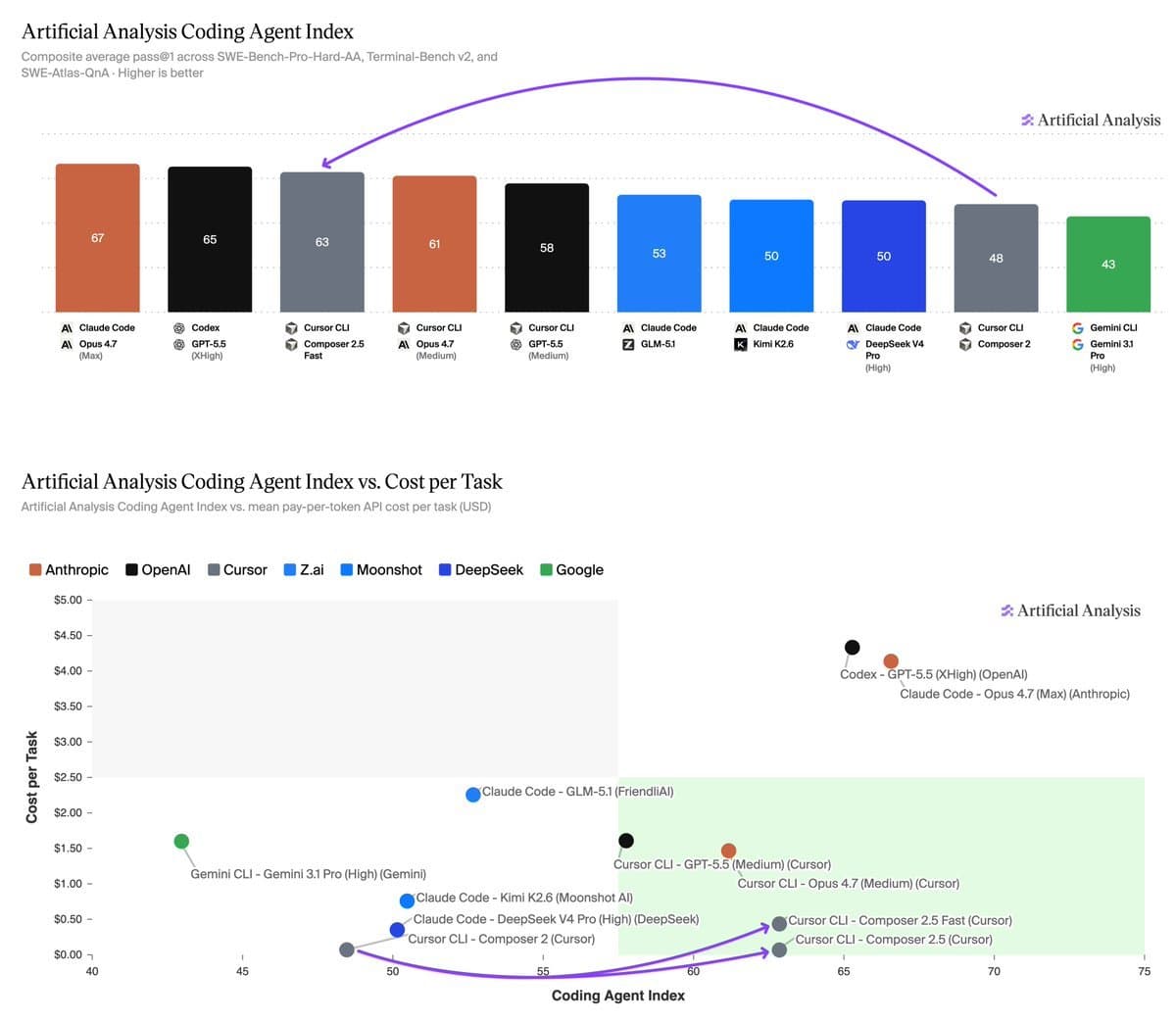
Composer 2.5 scored 62 on the Artificial Analysis Coding Agent Index. The two models above it score 65 and 66, but cost 60x more per task.
Key facts
- Composer 2.5 scores 62 on Artificial Analysis Coding Agent Index
- Top two models score 65 and 66
- Cost per task: $0.07 vs. $4-5
- Cost differential is 60x
- Source: @kimmonismus tweet
Composer 2.5, the latest coding agent from the unnamed developer behind the @kimmonismus handle, scored 62 on the Artificial Analysis Coding Agent Index [According to @kimmonismus]. The top two models on the index — likely Claude Code or GPT-4-based agents, though the source does not specify which — scored 65 and 66 respectively.
The critical differentiator is cost. Composer 2.5 runs at $0.07 per task, while the two higher-scoring models cost $4-5 per task — a 60x price differential. "At some point 'slightly better' stops being worth '60x more expensive,' and most engineering teams crossed that point a while ago," the source wrote.
The unique take here is that the coding agent market is bifurcating along cost-per-task lines, not raw benchmark scores. For many production engineering teams, a 3-4 point delta on a synthetic benchmark is dwarfed by a 60x cost multiplier when scaling to thousands of daily tasks. The Artificial Analysis Coding Agent Index, which weights correctness, latency, and cost, appears to capture this trade-off more usefully than pure accuracy benchmarks like SWE-Bench.
The source did not disclose which specific models occupy the top two slots, nor the exact methodology of the Artificial Analysis Coding Agent Index. The index itself is maintained by Artificial Analysis, a third-party benchmarking organization that has increasingly focused on agentic coding tasks in 2026.
For context, the cost-per-task gap has widened dramatically over the past 90 days. As of early 2026, most frontier coding agents ran at $1-3 per task, but newer optimized models like Composer 2.5 have driven costs below $0.10 by using smaller, task-specific architectures and aggressive caching strategies [per previously reported industry trends]. This mirrors the pattern seen in text generation models in 2024-2025, where cost compression eventually dominated raw quality competition.
Key Takeaways
- Composer 2.5 scores 62 on coding index at $0.07/task vs $4-5 for rivals scoring 65-66.
- 60x cost savings with near-parity performance.
What to Watch
Watch for the next update of the Artificial Analysis Coding Agent Index, expected within 30 days. If Composer 2.5 holds the cost advantage while top models stagnate near 66, expect a wave of enterprise migrations. Also watch whether Claude or OpenAI respond with a cost-optimized tier below $0.50 per task.
What to watch
Watch for the next Artificial Analysis Coding Agent Index update within 30 days. If Composer 2.5 holds cost advantage while top models stagnate near 66, expect enterprise migrations. Also watch whether Claude or OpenAI respond with a cost-optimized tier below $0.50 per task.
[Updated 27 May via scmp_tech]
The previously unnamed developer behind Composer 2.5 has been identified as Alibaba Group, with the model formally named Qwen3.7-Max [per SCMP]. It scored 1,541 on the Code Arena ranking, claiming fourth place globally and outperforming rival models from OpenAI and Google. This makes Alibaba the only developer besides Anthropic to break into the ranking's top five spots.