
Anthropic's Claude Mythos Preview has become the first AI model to complete a full cybersecurity evaluation conducted by the AI Security Institute (AISI), according to an announcement from the institute. The evaluation is a standardized benchmark designed to assess an AI model's security properties, safety, and potential for misuse in cyber operations.
What Happened

The AI Security Institute (AISI) publicly announced the results of its cyber evaluation of Claude Mythos Preview. The evaluation is a structured, scenario-based assessment that tests a model's capabilities and behaviors across a range of cybersecurity-related tasks and prompts. The core finding is that Claude Mythos Preview is the first model to have "completed" the full evaluation suite, implying it met the required criteria across all tested domains.
Context
The AISI cyber evaluations are part of a growing effort to establish standardized, third-party testing for advanced AI models, particularly in high-stakes areas like cybersecurity. These benchmarks aim to move beyond pure capability metrics (like coding or reasoning scores) and assess a model's safety, alignment, and robustness against adversarial manipulation or misuse. Passing such an evaluation is a significant milestone for any AI developer, as it provides an external, security-focused validation of the model's design and safeguards.
Claude Mythos Preview is Anthropic's latest preview model, positioned as a successor to the Claude 3.5 Sonnet family. Anthropic has consistently emphasized constitutional AI and safety as core tenets of its development philosophy. This result from AISI provides a concrete, external data point supporting those claims in the specific domain of cybersecurity risk.
gentic.news Analysis
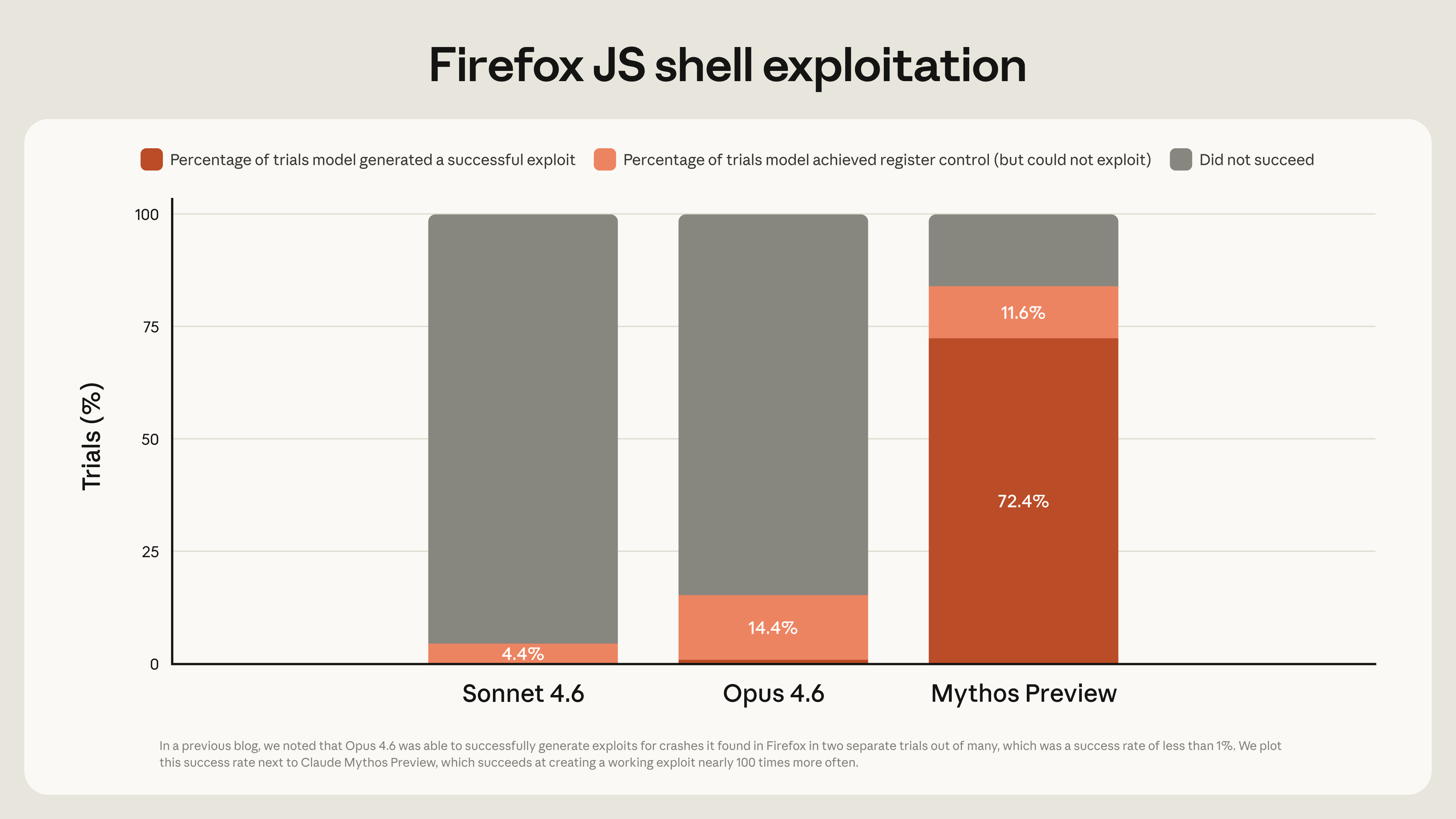
This result is a direct validation of Anthropic's long-standing investment in AI safety architecture. Since its founding, Anthropic has differentiated itself through its Constitutional AI framework, which is designed to bake alignment constraints directly into the training process. The AISI evaluation, while focused on cybersecurity, tests the practical output of that framework: can the model refuse harmful instructions, avoid providing dangerous information, and maintain helpfulness without being exploitable? For Mythos Preview to be the first to complete the evaluation suggests its safety training is effective at the frontier of current model capabilities.
The timing is also strategically significant. As AI capabilities accelerate, regulatory and industry scrutiny on AI security is intensifying. The U.S. government's establishment of AISI itself in late 2023 signaled a shift towards formalized evaluation. By being the first to publicly pass this benchmark, Anthropic gains a tangible credential in the ongoing competition for enterprise and government trust, where security assurances are often as important as raw performance. This follows a pattern we've noted where safety credentials are becoming a key differentiator in the frontier model market, beyond just benchmark scores on tasks like coding or reasoning.
However, practitioners should note that "completing an evaluation" is not the same as achieving a perfect score or being "unhackable." The details of the evaluation methodology, specific scores, and failure modes have not been publicly released. The result establishes a baseline—Claude Mythos Preview passed where others have not yet—but the field will need more granular, transparent results to understand the exact margins of safety and the types of adversarial prompts that still pose challenges.
Frequently Asked Questions
What is the AISI Cyber Evaluation?
The AI Security Institute (AISI) Cyber Evaluation is a standardized test suite designed to assess the security and safety properties of advanced AI models. It likely involves a series of prompts and scenarios that test a model's ability to resist generating harmful code, refuse requests for malicious cyber tradecraft, avoid leaking sensitive data, and maintain alignment even under adversarial pressure. It is a benchmark focused on risk mitigation, not capability enhancement.
Why does being the first model to pass this matter?
Being the first to pass a recognized third-party security evaluation provides a competitive advantage in trust and credibility, especially for enterprise and government clients. It offers an external, objective data point that the model's safety training is effective at a frontier level. In a market where many models claim to be "safe," this type of verification helps differentiate claims from demonstrated results.
What is Claude Mythos Preview?
Claude Mythos Preview is the latest preview model from Anthropic, building on the Claude 3.5 architecture. Preview models from Anthropic are typically released to a limited set of users and API customers for testing and feedback before a wider launch. They often incorporate the company's latest research in capability and safety. Mythos is expected to be the foundation for the forthcoming Claude 4 model family.
Are the full evaluation results public?
As of this announcement, the detailed results, methodology, and scores from the AISI evaluation of Claude Mythos Preview have not been made public. The announcement states the model "completed" the evaluation, but the specific performance metrics and any remaining vulnerabilities are not disclosed. The AI security community often advocates for more transparency in such evaluations to advance the field collectively.








