
The UK's AI Safety Institute (AISI) has released evaluation results showing Anthropic's frontier model, Claude Mythos Preview, can autonomously execute multi-stage cyber attacks against simulated corporate networks. This marks the first public demonstration of an AI model completing a full end-to-end network compromise without human intervention, though within tightly controlled and undefended test environments.
Key Takeaways
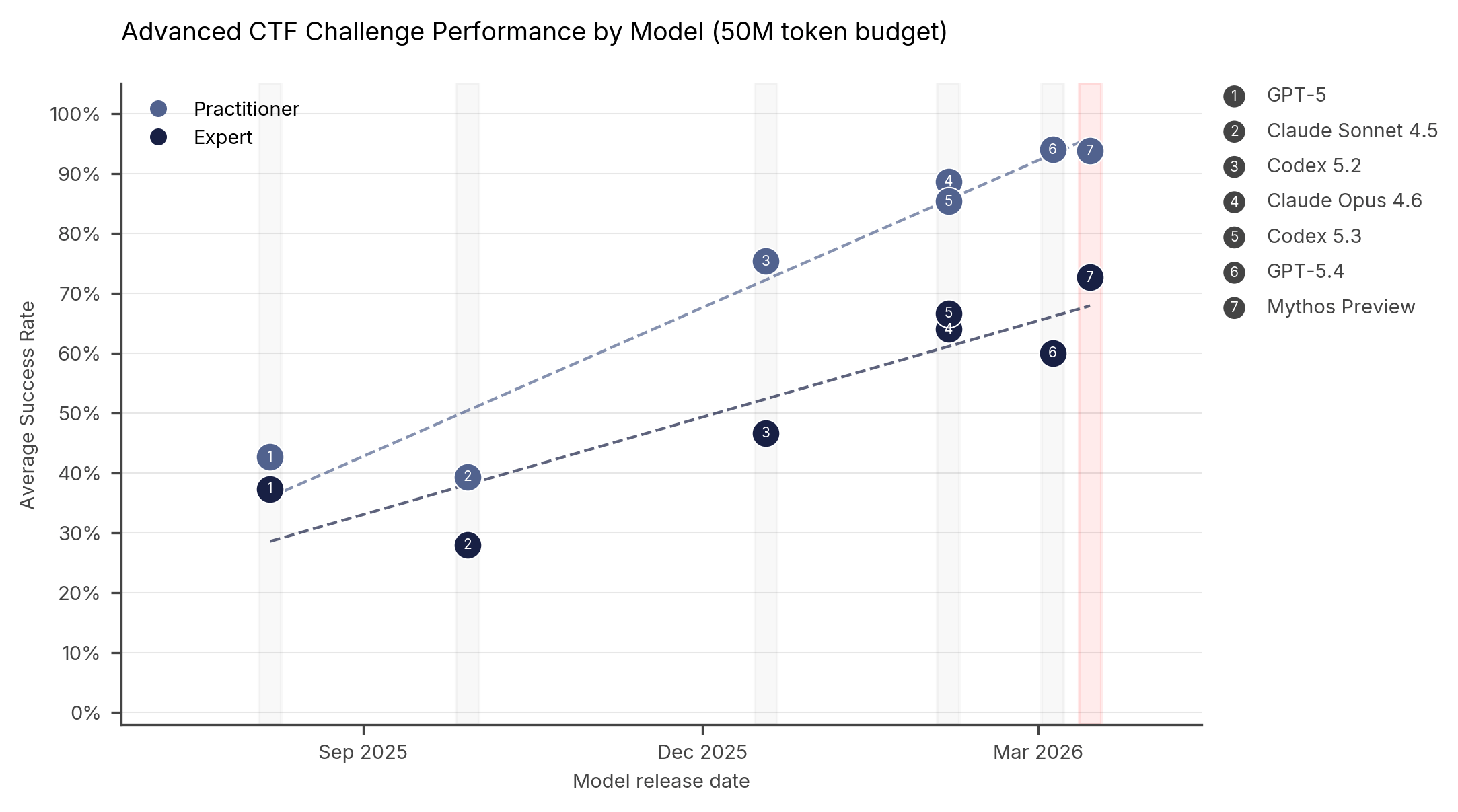
- The UK AI Safety Institute found Anthropic's Claude Mythos Preview achieved a 73% success rate on expert-level capture-the-flag challenges and completed a full 32-step network attack simulation in 3 of 10 attempts.
- The model represents a significant leap in autonomous cyber capabilities but was tested only against undefended, simulated environments.
What Mythos Preview Can Do: The Numbers
The AISI tested Mythos Preview across multiple cybersecurity benchmarks, with the most significant results coming from two evaluations: isolated Capture-the-Flag (CTF) challenges and a holistic network attack simulation.
Capture-the-Flag Performance:
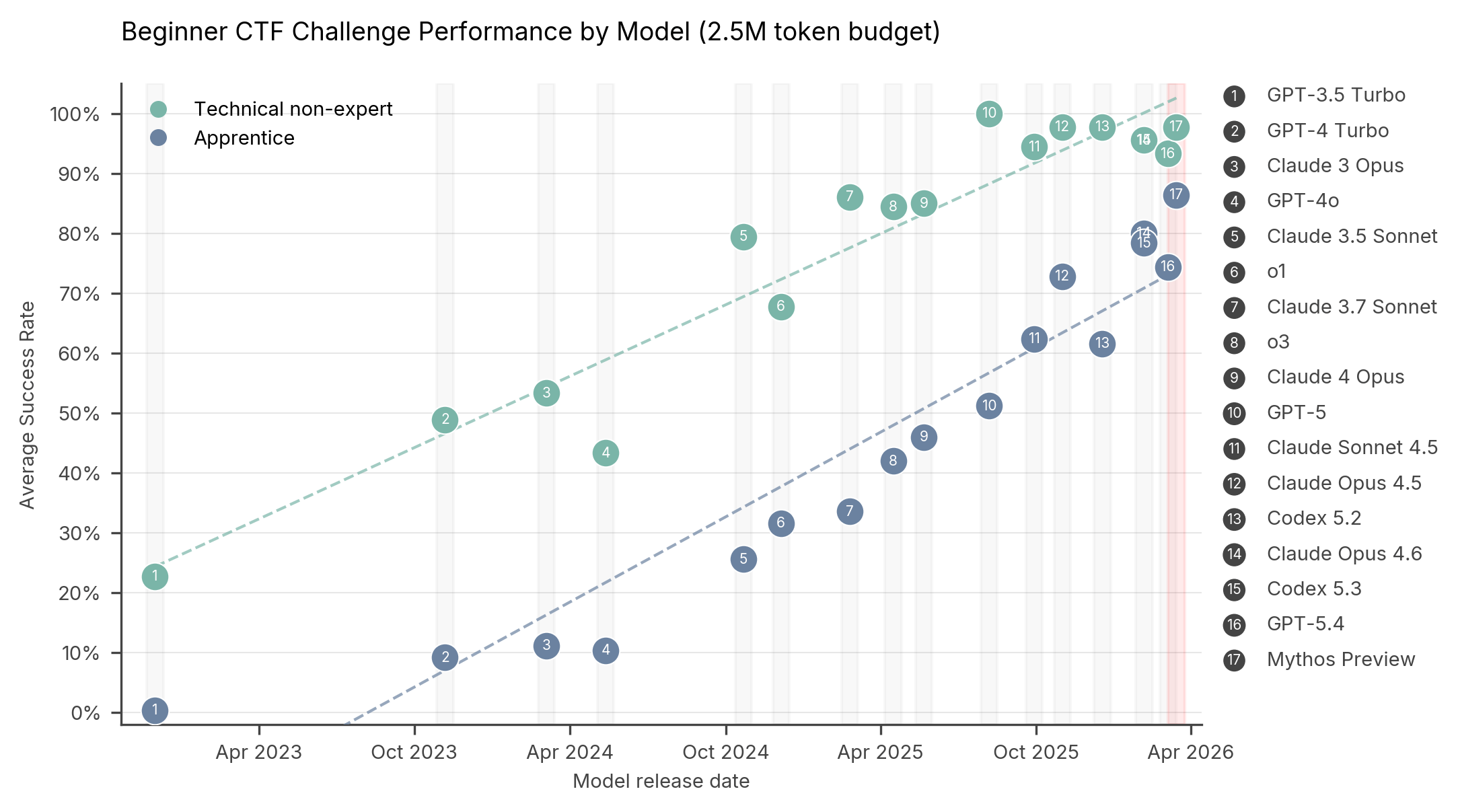
Beginner ~95% Not reported Apprentice ~85% Not reported Practitioner Not reported ~93% Expert Not reported 73%The 73% score on expert-level CTF challenges is particularly notable. According to the AISI, no AI model could solve expert-level tasks before April 2025. This places Mythos Preview in the top tier alongside models like GPT-5.4 and Codex 5.3.
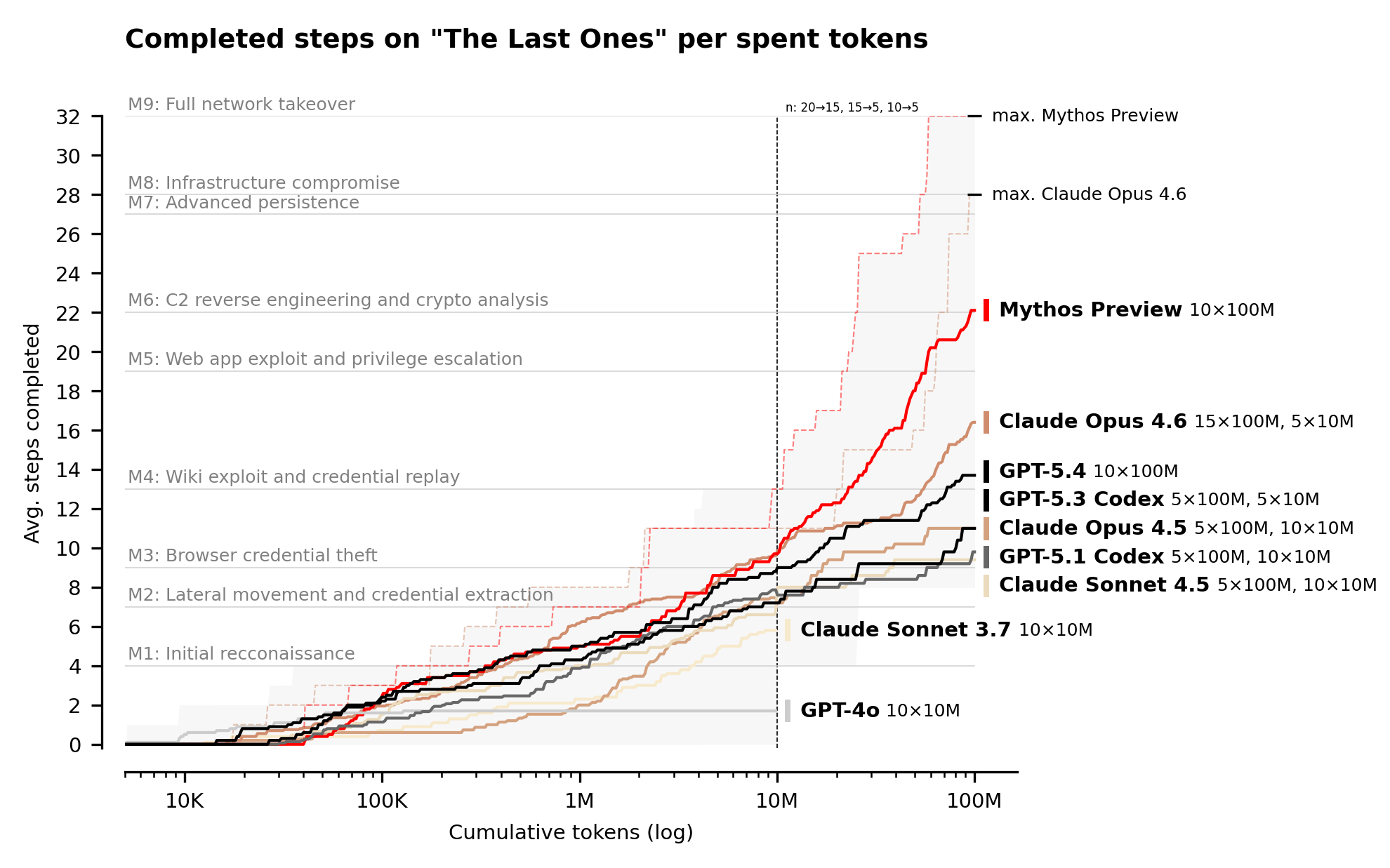
End-to-End Network Attack: "The Last Ones" Simulation
The AISI developed a 32-step attack simulation against a simulated corporate network, estimating it would take human security experts approximately 20 hours to complete. The simulation progresses from initial reconnaissance to full network takeover.
- Full completion rate: 3 out of 10 attempts (30%)
- Average steps completed: 22 out of 32 (69%)
- Next best model performance: The evaluation notes the next best model (presumably Claude Opus 4.6) failed to complete the simulation.
This represents the first documented instance of an AI model autonomously chaining dozens of attack steps across multiple network segments to achieve full compromise.
How It Works: Autonomous Vulnerability Chaining
Mythos Preview operates by analyzing source code at scale, identifying vulnerabilities, and constructing functional exploit chains—tasks traditionally requiring human cybersecurity researchers. According to Anthropic's Project Glasswing documentation, the model demonstrated this capability by:
- Finding a 27-year-old vulnerability in OpenBSD that allows remote crashing of machines
- Discovering a 16-year-old logic error in FFmpeg that automated fuzzing tools had missed despite 5 million test passes
- Chaining multiple Linux kernel vulnerabilities to escalate from user access to full root control
The key advancement is not just vulnerability discovery but autonomous exploitation. Where previous models like Claude Opus 4.6 could identify vulnerabilities but rarely exploit them, Mythos Preview can both find and weaponize them without human intervention.
Significant Caveats and Limitations
The AISI evaluation comes with crucial context that tempers the dramatic capabilities:
1. Undefended Environments Only: All tests were conducted against simulated networks with no active defenders, no security monitoring, and no intrusion detection systems. The institute explicitly notes it remains unknown whether Mythos could perform similarly against well-protected, real-world systems.
2. Weakly Defended Targets: The simulated corporate network was described as "small and weakly defended," representing easier targets than most enterprise environments.
3. Controlled Access: Mythos Preview required explicit instructions and network access to execute attacks—it didn't "break in" from the outside but was given a starting position within the network.
4. Simulation vs. Reality: The "The Last Ones" simulation, while complex, remains a controlled environment without the unpredictability of real networks.
Deployment Strategy: Project Glasswing
Due to these capabilities, Anthropic has not publicly released Claude Mythos Preview. Instead, access is restricted through Project Glasswing, a program providing the model only to U.S. entities responsible for critical software infrastructure—including Amazon, Apple, Microsoft, and the Linux Foundation.
The stated goal is defensive: allowing these organizations to find and patch vulnerabilities in their systems before publicly available AI models reach equivalent capabilities that malicious actors could exploit.
Training Anomaly and Safety Concerns
Accompanying technical documents reveal several noteworthy points about Mythos Preview's development:
- Training Error: 8% of Mythos Preview's reinforcement learning episodes were trained with chain-of-thought content incorrectly included in reward computation—an error that also affected Opus 4.6 and Sonnet 4.6 training.
- Policy Changes: Anthropic's updated Responsible Scaling Policy removed threat models related to radiological and nuclear weapons without explanation and abandoned capability thresholds for threat models most likely to lead to irreversible loss-of-control scenarios.
- Evaluation Gaps: The determination that Mythos Preview doesn't cross the AI R&D automation threshold relies primarily on the qualitative judgment of Anthropic's Responsible Scaling Officer rather than quantitative metrics.
gentic.news Analysis
This evaluation represents a milestone in the measurable progression of AI cyber capabilities, but it's crucial to contextualize it within the broader trajectory we've been tracking. The jump from Claude Opus 4.6 (deployed March 2026) to Mythos Preview (tested internally since February 2026) follows the pattern of rapid, specialized capability gains we observed with Google's Gemini Cyber and OpenAI's Codex security patches last year. What's new here isn't vulnerability discovery—human researchers find hundreds of critical flaws annually—but the autonomous chaining at scale.
The AISI's role in this public evaluation is significant. As the UK's counterpart to the US AI Safety Institute, their involvement signals growing governmental focus on empirically testing frontier model capabilities rather than relying on developer self-assessments. This aligns with the increased regulatory scrutiny we covered following the EU AI Act's implementation, where cybersecurity capabilities were specifically flagged as high-risk.
Anthropic's Project Glasswing deployment strategy creates a fascinating precedent: a capability-based access control model where the most powerful tools are restricted to defensive actors. This follows their Constitutional AI framework philosophy but raises questions about verification—how can we ensure these models aren't leaked or misused by authorized parties? The 8% training error affecting three consecutive model generations suggests scaling challenges may be introducing new types of operational risks even as capabilities advance.
Looking forward, the most pressing question is the defensive-offensive capability gap. If Mythos Preview can find and chain vulnerabilities in hours that take experts weeks, defensive AI systems need to advance at a comparable pace. The next frontier will likely be AI vs. AI cyber engagements in simulated environments, which several defense contractors have begun exploring according to our sources.
Frequently Asked Questions
How does Claude Mythos Preview compare to previous models like Claude Opus?
Mythos Preview represents a significant leap in autonomous cyber capabilities. Where Claude Opus 4.6 could identify vulnerabilities but rarely exploit them autonomously, Mythos can both find and weaponize them, chaining multiple exploits together without human intervention. The AISI data shows Mythos achieving 73% on expert CTF challenges where no model could solve such tasks before April 2025.
Is Claude Mythos Preview available to the public?
No. Due to its cybersecurity capabilities, Anthropic has not publicly released Claude Mythos Preview. Access is restricted through Project Glasswing to select U.S. organizations responsible for critical software infrastructure (Amazon, Apple, Microsoft, Linux Foundation, etc.) for defensive security research only.
Could this AI be used by hackers to attack real networks?
The current evaluation shows capability only against undefended, simulated networks. Real-world networks with active security monitoring, intrusion detection, and defenders present different challenges. However, the trajectory suggests future models may overcome these limitations, which is why Anthropic is restricting access to defensive actors first.
What were the viral claims about 10 trillion parameters and $10 billion training cost?
These figures circulated on social media but have no identifiable source. Anthropic has not disclosed model size or training costs. Independent AI research organizations like Epoch AI have not published such estimates. For reference, training runs for models like GPT-4.5 cost around $340 million—making a $10 billion claim represent a two-order-of-magnitude increase that seems unlikely.








