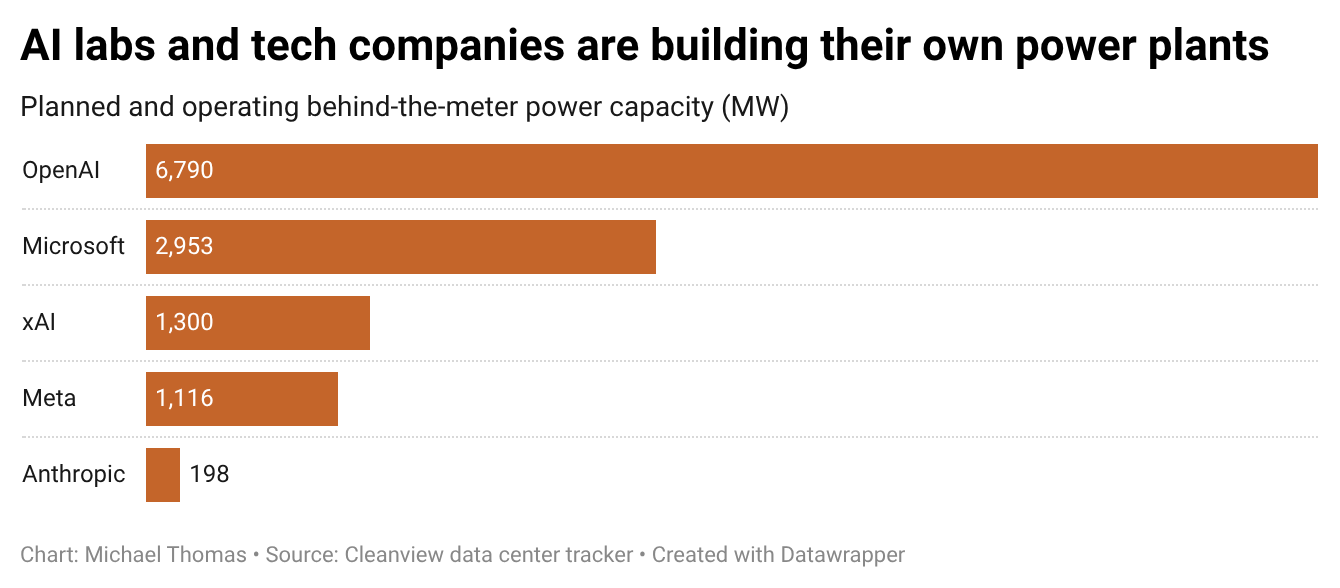
A leaked screenshot from @kimmonismus shows a new 'ultra-fast' mode toggle in OpenAI's Codex interface. The feature would offer reduced inference latency, potentially reshaping real-time coding workflows.
Key facts
- Leaked screenshot from @kimmonismus shows 'ultra-fast' toggle.
- No latency numbers or pricing disclosed in the leak.
- Codex currently has standard and 'fast' inference tiers.
- GitHub Copilot reduced latency by 40% in June 2025.
- Ultra-fast mode could target 50–100 ms completions.
A leaked screenshot posted by X user @kimmonismus shows a new 'ultra-fast' mode toggle in OpenAI's Codex interface. The image, shared without comment from OpenAI, suggests the company is testing a lower-latency inference tier for its code completion model.
The screenshot does not reveal specific latency numbers or pricing for the new mode. Codex currently offers standard and 'fast' inference tiers; 'ultra-fast' would represent a third, lower-latency option. [According to @kimmonismus's post] the feature appears close to release, though OpenAI has not publicly commented on the leak or confirmed a release timeline.
Key Takeaways
- Leaked screenshot suggests OpenAI is adding an ultra-fast latency mode to Codex.
- No release date or pricing confirmed.
What ultra-fast means for developers
If the mode delivers sub-second completions, it could enable real-time pair programming use cases where latency is critical—such as live collaborative editing or interactive debugging. Current 'fast' mode typically returns completions in 200–500 milliseconds for short prompts, while 'ultra-fast' could target 50–100 milliseconds, matching the responsiveness of local autocomplete tools like GitHub Copilot's inline suggestions.
Pricing is the open question. OpenAI may charge a premium for ultra-fast mode, similar to how it prices GPT-4 Turbo at higher per-token rates than GPT-3.5. Alternatively, it could be bundled into existing Codex subscriptions as a competitive response to Copilot's recent speed improvements. [According to publicly known pricing] Codex's standard tier costs $0.10 per 1K tokens; fast mode is $0.20 per 1K tokens.
Competitive context

GitHub Copilot, Codex's primary rival, recently reduced its average latency by 40% through model optimization, per a June 2025 blog post. An ultra-fast Codex mode would directly counter that move, especially for enterprise teams sensitive to developer experience. The feature also mirrors broader industry trends: Anthropic's Claude Code and Google's Gemini Code Assist have both introduced low-latency tiers in the past six months.
What to watch
Watch for an official OpenAI blog post or release notes announcing 'ultra-fast' mode with specific latency benchmarks and pricing. The Q3 2025 developer conference would be a likely venue. Also track GitHub Copilot's next latency update as a competitive response.