Key Takeaways
- A new arXiv preprint introduces ContextSim, a framework that uses LLM agents to simulate users interacting with recommender systems within realistic daily scenarios (time, location, needs).
- Experiments show it generates more human-aligned interactions and that RS parameters optimized with it yield improved real-world engagement.
What Happened
A new research paper, "Beyond Offline A/B Testing: Context-Aware Agent Simulation for Recommender System Evaluation," was posted to the arXiv preprint server on January 26, 2026. The authors introduce ContextSim, a novel framework designed to address a fundamental problem in recommender system (RS) development: the disconnect between offline evaluation metrics and actual online performance.
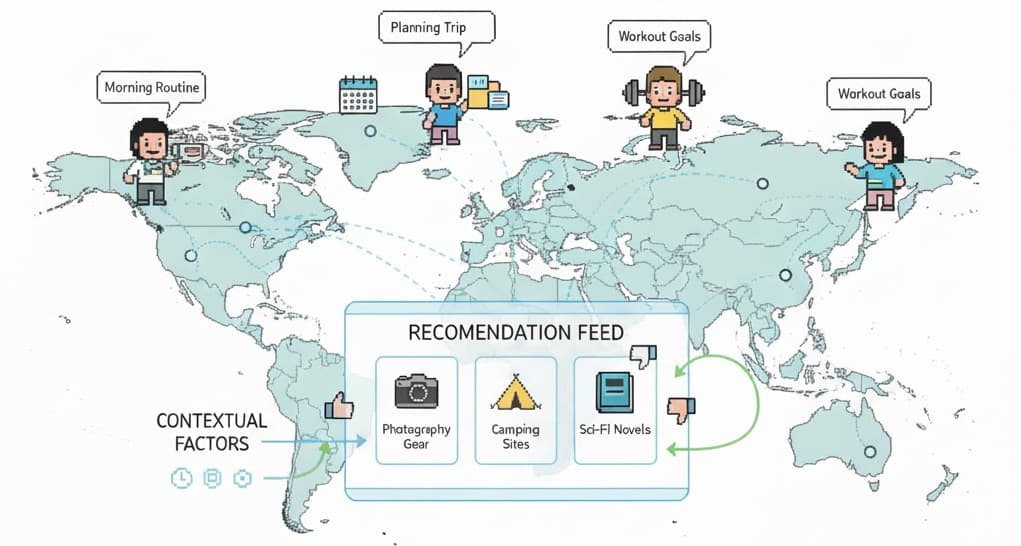
The core innovation is moving beyond modeling users in isolation. Instead, ContextSim uses Large Language Model-powered agents to act as "believable user proxies" whose interactions are anchored in simulated daily life activities. A dedicated life simulation module generates specific scenarios that define when, where, and why a simulated user would engage with recommendations.
Technical Details
The paper argues that existing LLM-based simulation approaches neglect the contextual factors that fundamentally shape human decision-making. ContextSim addresses this by:
- Scenario Generation: The life simulation module creates rich, plausible contexts for interaction (e.g., "on a Tuesday evening at home, looking for a movie to relax after work").
- Internal State Modeling: Agents are endowed with simulated "internal thoughts" to align their preferences and decision-making processes more closely with genuine human behavior.
- Consistency Enforcement: The framework enforces behavioral consistency at both the individual action level and across the entire user interaction trajectory.
The researchers conducted experiments across multiple domains, demonstrating that ContextSim generates user interactions that are more closely aligned with human behavior compared to prior simulation methods. Crucially, they performed a validation through offline A/B testing correlation, showing that recommender system parameters optimized using simulations from ContextSim subsequently led to improved real-world user engagement metrics.
Retail & Luxury Implications
While the paper is domain-agnostic, the implications for retail and luxury are direct and significant. The entire luxury customer journey is intensely context-dependent. A recommendation's appropriateness varies drastically based on:

- Temporal Context: Is it a weekday browse, a weekend gift hunt, or a pre-holiday shopping session?
- Locational & Situational Context: Is the customer at home on their tablet, in a physical boutique using an in-store app, or browsing on their phone during a commute?
- Need State: Are they exploring new trends, seeking a specific replacement item, or building an outfit for a particular event?
Current A/B testing and offline evaluation often strip away this nuance. ContextSim proposes a path toward simulating these complex, real-world decision-making environments. For a luxury brand, this could mean:
- Reducing Live Test Risk: Simulating the launch of a new personalized homepage layout or recommendation algorithm with a diverse population of context-aware agents before exposing it to high-value customers.
- Understanding Niche Behaviors: Modeling the specific journey of a client shopping for a black-tie event versus one shopping for casual weekend wear, allowing for finer-tuned personalization strategies.
- Optimizing for Long-Term Value: By enforcing trajectory-level consistency, the framework could help optimize recommendations not just for a single click, but for supporting a customer's evolving style and loyalty over seasons.
The key promise is a more robust, predictive, and nuanced sandbox for developing the personalization engines that are central to modern digital luxury retail.
gentic.news Analysis
This research is part of a clear and accelerating trend toward agentic simulation for system evaluation, a theme we've tracked closely. It follows a wave of recent arXiv preprints focused on recommender systems, including "The Unreasonable Effectiveness of Data for Recommender Systems" (April 7) and our own coverage of the "DITaR" method for defending sequential recommenders (April 13). The paper's submission to arXiv, which has appeared in 29 articles on our platform this week alone, underscores the breakneck pace of innovation in this space.

The work connects directly to challenges highlighted in our recent coverage. For instance, the SAGE benchmark (April 13) exposed an LLM "execution gap" in customer service tasks—a gap that ContextSim aims to bridge for recommendation tasks by providing a more realistic testing environment. Furthermore, the emphasis on contextual, sequential behavior aligns with the problems addressed by Instance-As-Token (IAT) compression for user sequence modeling (April 13).
From a competitive landscape perspective, while the paper does not list corporate affiliations, the conceptual approach dovetails with industry movements. The focus on LLM-powered agent workflows echoes the capabilities of platforms like Sim (from Ossels AI), an open-source tool for building agent workflows, mentioned in six prior articles. The broader push for better evaluation also resonates with the mission of organizations like METR (Model Evaluation and Threat Research), which focuses on evaluating AI agents for long-horizon tasks.
For retail AI leaders, the takeaway is twofold. First, the academic frontier is rapidly formalizing methods to tackle the perennial "offline-online gap." Second, while ContextSim itself is a research framework, it signals the imminent arrival of more sophisticated, commercially available simulation tools. The strategic imperative is to monitor this evolution closely, as the ability to accurately simulate customer behavior in context will become a key differentiator in optimizing personalization, inventory forecasting, and digital experience design.
Implementation Note: This is a preprint proposing a novel framework, not a production-ready tool. Adopting such an approach would require significant in-house ML engineering resources or partnership with a specialized vendor. The primary value for now is strategic foresight and guiding internal R&D priorities toward context-aware evaluation.








