A developer has publicly announced a significant overhaul of their automotive AI pipeline, stating they will replace their existing dash cam video analysis system with a new stack built on Google's Gemma 4 and Falcon Perception models.
The announcement, made on social media, is a concise but telling signal of how practitioners are rapidly adopting and integrating the latest generation of open-weight and specialized vision-language models for real-world, edge computing tasks.
What Happened
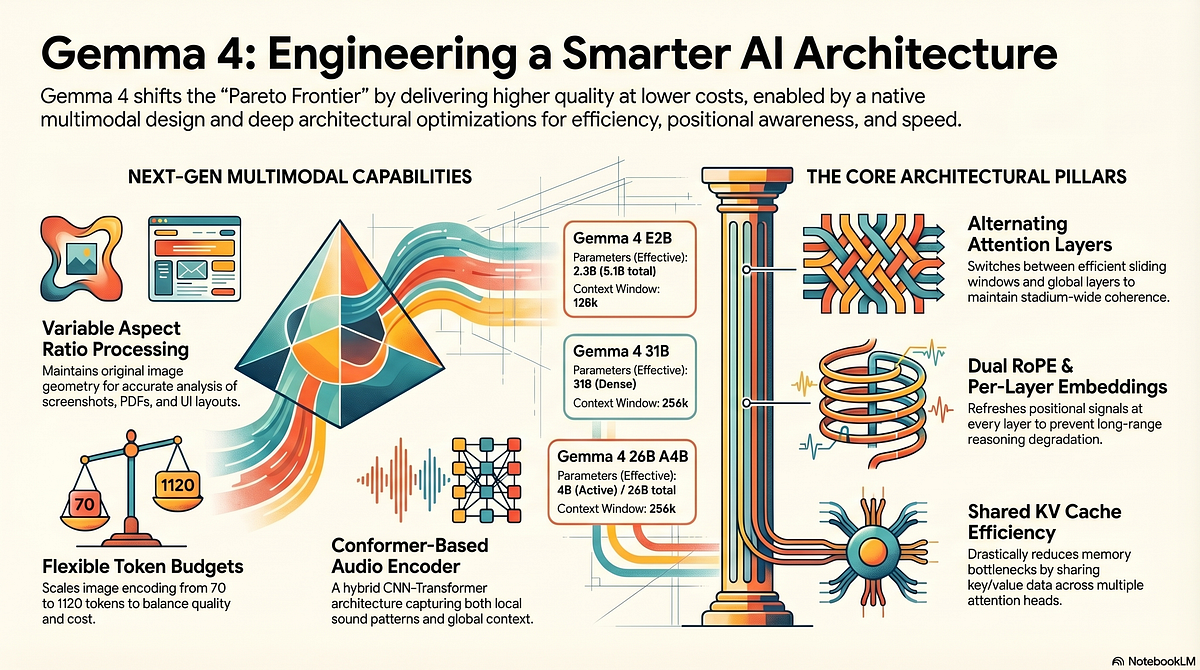
In a brief post, developer Prince Canuma stated: "I will replace my dash cam analysis with Gemma 4 + Falcon Perception." The statement indicates a complete replacement (replace my dash cam analysis) of an existing computer vision pipeline designed to interpret video from a vehicle's dashboard camera.
The new stack explicitly names two key components:
- Gemma 4: The latest iteration of Google's family of open-weight language models, which has recently expanded into strong multimodal capabilities.
- Falcon Perception: Likely referring to a vision model or a multimodal model from the Falcon family (developed by the Technology Innovation Institute in Abu Dhabi), specialized in perception tasks.
Context
Dash cam analysis is a growing application of edge AI, involving tasks like object detection (cars, pedestrians, traffic signs), lane departure warnings, collision prediction, and event logging (sudden braking, accidents). Traditionally, these systems might rely on a combination of specialized convolutional neural networks (CNNs) like YOLO for detection and a separate logic or simple language model for description or alert generation.
The developer's move suggests a shift towards a more integrated, multimodal approach. Instead of a patchwork of single-purpose models, they are opting for a stack centered on large, capable foundation models that can understand and reason about complex visual scenes in a more holistic way, potentially generating richer descriptions or more contextual alerts.
Key Implications of the Shift:
- From Specialized to Generalist Models: Replacing a dedicated CV pipeline with Gemma 4 (a general-purpose LM/VLM) indicates a bet on the robustness and flexibility of newer, larger models for a specialized task.
- Edge Deployment Challenge: Deploying models of this size (Gemma 4 likely has multi-billion parameter variants) on an edge device in a car is non-trivial. This suggests either the use of heavily quantized or distilled versions, or a hybrid cloud-edge architecture where heavy lifting is done off-vehicle when connectivity allows.
- The Rise of the "Model Stack": Practitioners are now thinking in terms of curating a stack of foundation models (one for language/vision reasoning, one perhaps for pure perception) rather than training a monolithic custom model from scratch.
gentic.news Analysis

This single-sentence announcement is a microcosm of a major trend we've been tracking: the operationalization of open-weight frontier models. This follows Google's aggressive release strategy for the Gemma family, which began with Gemma 1 in February 2024 and has rapidly iterated to push multimodal performance. Gemma 4 represents a direct challenger to other open-weight multimodal models like Meta's Llama 3.2 Vision or Qwen2-VL, and developers are now conducting real-world A/B tests in their projects.
The choice to pair it with "Falcon Perception" is particularly insightful. It suggests that even with a powerful VLM like Gemma 4, developers may still be layering in specialized models for core perceptual heavy-lifting—a "best-in-breed" approach. This aligns with our previous coverage on the hybrid AI system architecture trend, where a orchestrator model delegates tasks to more efficient specialist models. The Falcon family, historically strong on language, appears to be expanding its reach into perception, creating new options for developers building these hybrid stacks.
For the automotive AI space, this move is a canary in the coal mine. If a solo developer finds this stack swap worthwhile, it pressures incumbent automotive software suppliers whose pipelines are based on older, more rigid architectures. The battleground is no longer just accuracy on a dataset, but developer ergonomics and pipeline flexibility. The winning models will be those that are easiest to integrate into complex, real-time systems like a moving vehicle's sensor suite.
Frequently Asked Questions
What is Gemma 4?
Gemma 4 is the latest generation of Google's open-weight language model family. While earlier Gemma models were text-only, recent iterations have incorporated strong vision-language capabilities, allowing them to understand and reason about images and video. It is positioned as a powerful, commercially usable alternative to other open models like Llama.
What is dash cam analysis with AI?
AI-powered dash cam analysis uses computer vision and machine learning to automatically process video from a car's dashboard camera. It can identify objects (other vehicles, people, bicycles), read traffic signs, detect unsafe events (sudden swerving, close following distance), and sometimes generate narrative summaries of trips or incidents. This technology is used in fleet management, insurance telematics, and advanced driver-assistance systems (ADAS).
Why would a developer replace their entire system?
A developer might replace a working system for several key reasons: 1) Performance: Newer models like Gemma 4 may offer significantly better accuracy and contextual understanding. 2) Development Speed: Using a powerful foundation model can be faster than maintaining and fine-tuning multiple specialized models. 3) Functionality: A multimodal model can enable new features, like generating detailed natural language reports of a drive, that were difficult with the old pipeline.
Is it feasible to run these models in a car?
Running large models like Gemma 4 directly on an edge device in a car is challenging due to computational, memory, and power constraints. In practice, this likely involves using heavily optimized versions (via quantization, pruning, or distillation) or employing a split architecture where video is processed on a device but complex reasoning is handled by a cloud API when the car has connectivity, with results cached or synced later.