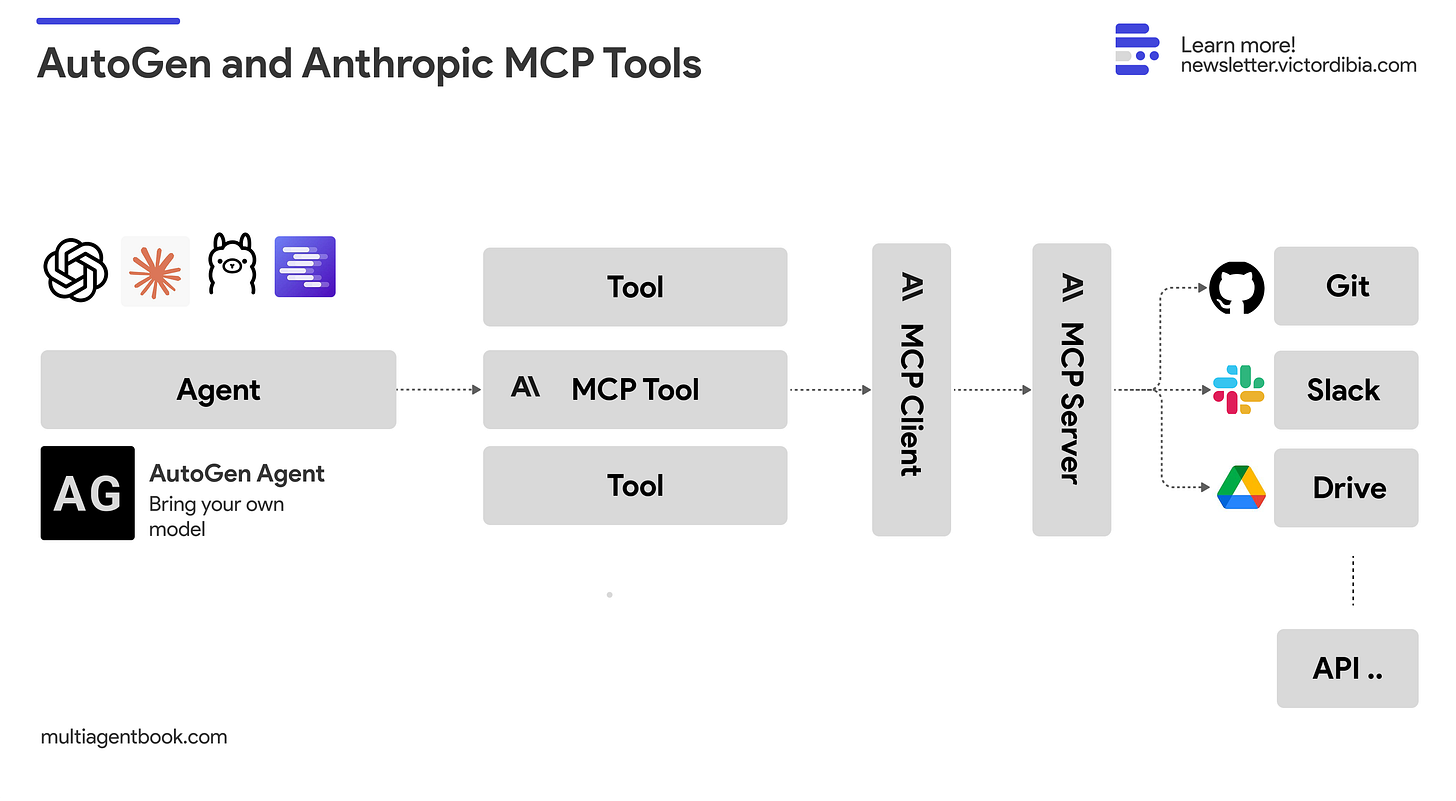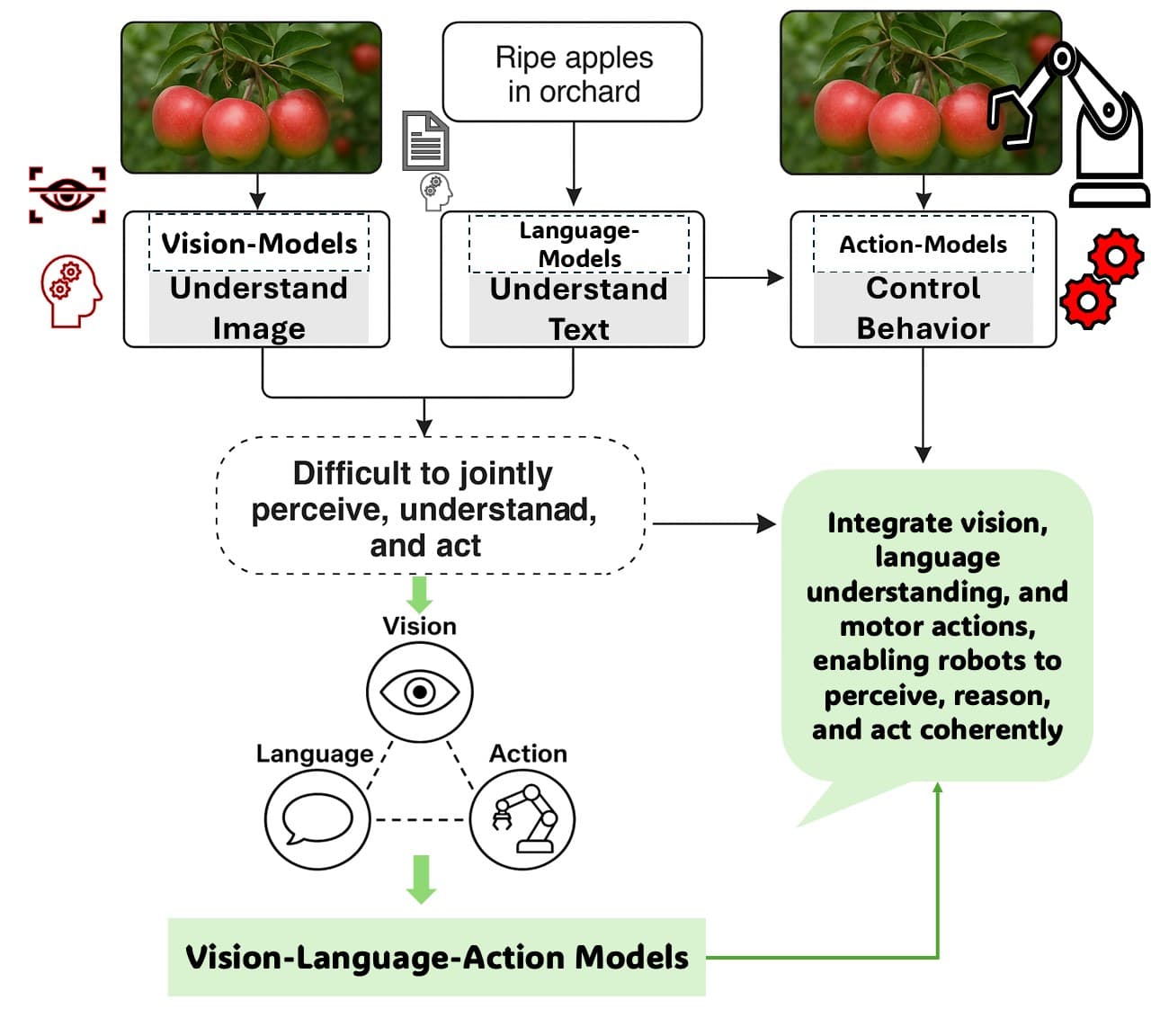
A developer has shared a concise technical blueprint for a vision-language-action agent pipeline, combining Google's Gemma language model with the Falcon Perception segmentation system. The architecture demonstrates a practical, modular approach to enabling AI agents to perceive visual scenes, extract precise spatial data, and reason about subsequent actions.
What Happened
Developer Prince Canuma, crediting Yasser Dahou, outlined a three-stage agent workflow in a social media post:
- Vision Understanding: The Gemma4 multimodal model analyzes an input image and decides what object or region needs to be segmented.
- Precise Segmentation: The task is handed off to Falcon Perception, a specialized model that returns pixel-accurate masks along with structured metadata, including the object's centroid coordinates, area fraction, and bounding box.
- Reasoning & Action: The extracted numerical metadata is fed back to Gemma4, which reasons over the spatial data to either call the next tool in a sequence or provide a final answer.
The post included a link to a demo video, suggesting a functional implementation of this pipeline.
Context & Technical Implications
This architecture represents a clear move toward tool-using, multimodal agents. Instead of relying on a single monolithic model to handle perception, reasoning, and action, it delegates subtasks to specialized components. Gemma4 acts as the central reasoning and planning engine, while Falcon Perception serves as a high-precision "perception tool."
The use of structured metadata (centroid, bbox) is key. It translates visual information into a numerical format that a language model can easily process and reason about, bridging the gap between pixel space and symbolic reasoning. This pattern is foundational for agents that interact with graphical user interfaces (GUI), robotics control, or any task requiring spatial understanding.
Key Components Mentioned:
- Gemma4: Google's latest open-weight multimodal model family, capable of processing both text and images.
- Falcon Perception: Likely referring to a model or system specialized in image segmentation, potentially related to the Falcon series of LLMs or a separate computer vision tool.
gentic.news Analysis
This development fits squarely into the accelerating trend of composable AI agent frameworks. It echoes the architectural philosophy behind projects like Microsoft's AutoGen or the growing use of LangChain for orchestrating multi-model workflows. The significance here is the specific integration of a strong open-source VLM (Gemma4) with a precision segmentation engine, creating a pipeline that is likely more accurate and efficient for spatial tasks than using a VLM alone for segmentation.
This follows Google's aggressive push with the Gemma 2 27B model in June 2024, which established strong performance in the open-weight category. The release of the multimodal Gemma 2 27B in early 2025 and the subsequent Gemma 3 iteration later that year demonstrated Google's commitment to making capable vision-language models accessible. The mention of "Gemma4" suggests continued rapid iteration, aligning with the competitive pace set by OpenAI's o1 series and Anthropic's Claude 3.5 Sonnet, which also emphasize tool use and reasoning.
The modular approach showcased here—using the best tool for each sub-task—is becoming a best practice in agent design. It contrasts with the pursuit of a single, giant "omni-model" and often yields better performance, cost efficiency, and debuggability. Practitioners building agents for real-world applications should pay close attention to this pattern of stitching together specialized models via structured data interfaces.
Frequently Asked Questions
What is Falcon Perception?
Based on the context, Falcon Perception appears to be a computer vision model or system specialized for image segmentation. It takes a natural language or instruction input (decided by Gemma4) and returns not just a mask but precise, quantifiable metadata like bounding boxes and centroids. This makes its output readily usable for downstream reasoning and tool-calling by a language model.
How does this compare to using a single model like GPT-4V?
A single large multimodal model (LMM) like GPT-4V or Claude 3.5 Sonnet can perform segmentation and reasoning within one system. This pipeline argues for a separation of concerns: a specialized segmentation model (Falcon Perception) may achieve higher pixel accuracy or faster performance than a generalist LMM, and feeding structured numeric data back to the reasoning model (Gemma4) can improve the reliability of its planning and tool calls.
What are the practical use cases for this pipeline?
This architecture is ideal for any agent task requiring precise spatial understanding and action. Primary use cases include robotic process automation (RPA) for controlling software via a GUI (clicking specific UI elements), robotics for object manipulation, image editing workflows guided by natural language, and detailed visual question answering that requires measuring or counting objects based on their precise location and size.
Is the code for this pipeline available?
The source post did not link to a public code repository. It presented the idea and a demo video. The blueprint, however, is clear enough for developers to implement using available models and agent frameworks, combining the Gemma API or an open-source variant with a segmentation model like SAM (Segment Anything Model) or a custom-trained variant to recreate the Falcon Perception component.