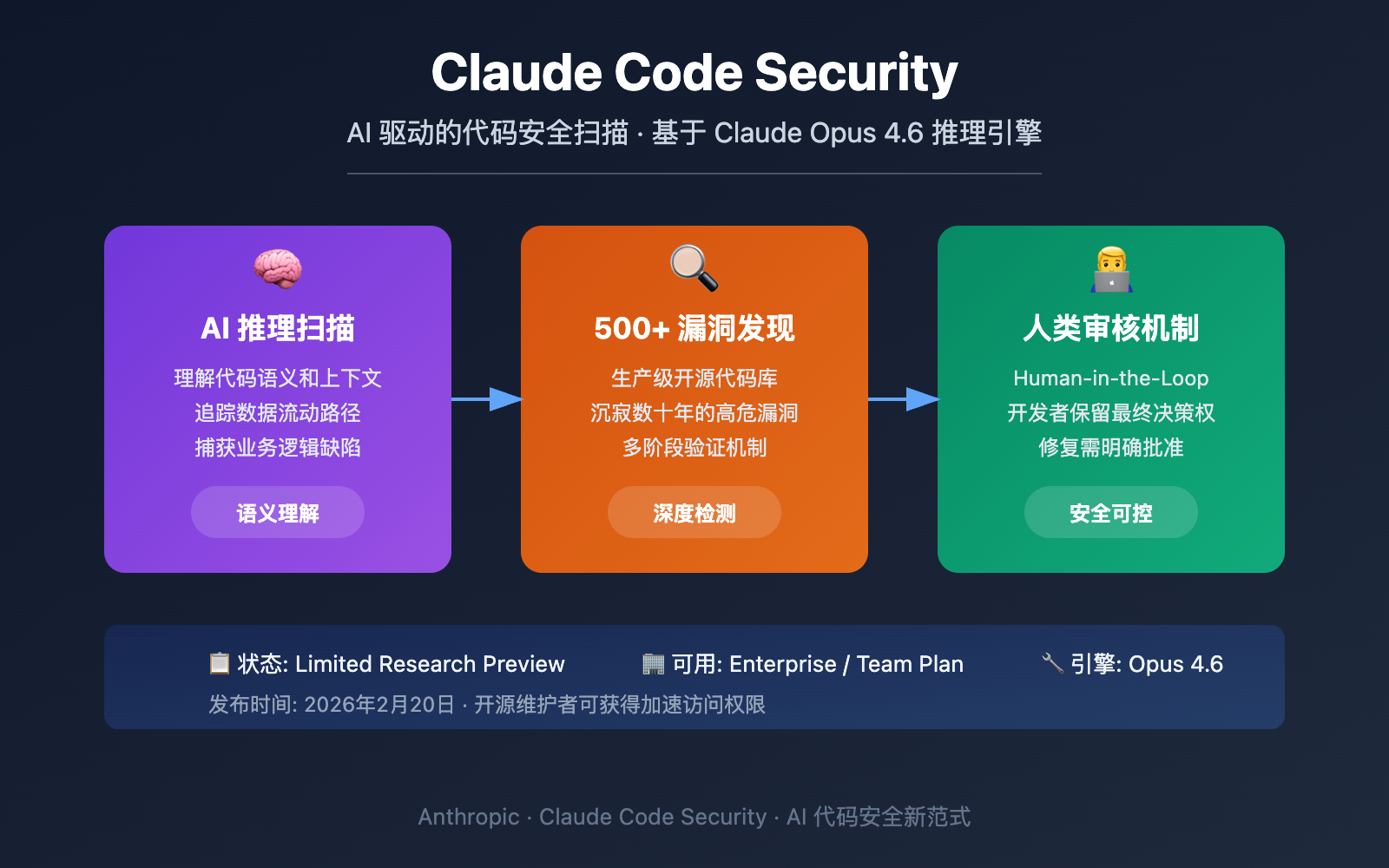
Researcher @emollick demonstrated Opus 4.8 building a complete RPG in Claude Code with zero human feedback. The model generated 3 PDF manuals, playtest notes, a website, and a playable solo adventure before deploying to Netlify.
Key facts
- Opus 4.8 built an RPG in Claude Code without human feedback.
- Output included 3 PDF manuals and a playable solo adventure.
- The model deployed the project to Netlify autonomously.
- Demonstration by researcher @emollick.
- Claude Code launched in early 2026 by Anthropic.
Anthropic's Opus 4.8, accessed through Claude Code, autonomously built and play-tested a new tabletop RPG, according to a demonstration by researcher Ethan Mollick (@emollick). The model produced 3 PDF manuals, playtest notes, a functional website, and a solo adventure, then deployed the entire project to Netlify. Mollick reported giving no feedback during the process [@emollick].
What Claude Code Enabled
The demonstration shows Claude Code handling a multi-step creative workflow: designing game mechanics, writing narrative content, formatting PDFs, coding a website, and managing deployment. Unlike typical AI coding tools that require iterative prompting, Opus 4.8 executed the entire pipeline without human intervention. The result includes a playable solo adventure hosted on Netlify.
One Unique Take
While prior models could generate code or text, Opus 4.8's ability to self-verify through play-testing and then deploy a production-ready artifact marks a shift from assistant to autonomous agent. The zero-feedback constraint is key — previous demonstrations of AI game development required human guidance at each step. This suggests Claude Code is approaching the reliability needed for unsupervised project completion.
Implications for AI Agent Workflows
The demonstration aligns with Anthropic's focus on agentic capabilities in Claude Code, which was launched in early 2026. The ability to autonomously produce a multi-file, multi-format project with deployment suggests progress toward self-directed AI agents. However, the single demonstration does not guarantee consistent performance across diverse tasks. The model's failure modes remain undocumented.
What to watch
Watch for Anthropic to release benchmarks on Claude Code's success rate on multi-step agentic tasks, and whether Opus 4.8 can replicate this performance on game development with different genres or constraints. Also monitor user reports of failure cases — the zero-feedback claim will be tested by replication attempts.