Key Takeaways
- EPM-RL uses reinforcement learning to distill costly multi-agent LLM reasoning into a small, on-premise model for product mapping.
- It improves quality-cost trade-off over API-based baselines while enabling private deployment.
What Happened

A new research paper from arXiv proposes EPM-RL, a framework that uses reinforcement learning (RL) to build an accurate and efficient on-premise e-commerce product mapping model. The core problem: deciding whether two e-commerce listings refer to the same product – a task made difficult by sellers injecting promotional keywords, platform-specific tags, and bundle descriptions into titles.
Recent LLM-based and multi-agent frameworks have improved robustness on these hard cases, but they rely on expensive external APIs, repeated retrieval, and complex inference-time orchestration. This makes large-scale deployment costly and difficult in privacy-sensitive enterprise settings.
Technical Details
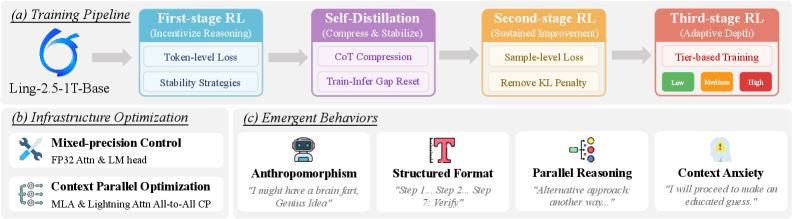
EPM-RL's central insight is to distill high-cost agentic reasoning into a trainable in-house model. The approach has two stages:
Parameter-Efficient Fine-Tuning (PEFT): Starting from a curated set of product pairs with LLM-generated rationales and human verification, the researchers fine-tune a small student model using structured reasoning outputs.
Reinforcement Learning Optimization: The model is further optimized using an agent-based reward that jointly evaluates:
- Output-format compliance
- Label correctness
- Reasoning preference scores from specially designed judge models
Preliminary results show that EPM-RL consistently improves over PEFT-only training and offers a stronger quality-cost trade-off than commercial API-based baselines. Crucially, it enables private deployment and lower operational cost.
Retail & Luxury Implications
Product mapping is the backbone of price monitoring and channel visibility – both critical for luxury and premium retail brands that need to maintain pricing integrity across marketplaces, authorized resellers, and unauthorized channels.
For luxury brands specifically:
- Price monitoring: Accurately matching a Dior handbag listing across Farfetch, Net-a-Porter, and the brand's own site to enforce MAP (Minimum Advertised Price) policies.
- Channel visibility: Detecting unauthorized sellers by matching product listings across marketplaces.
- Privacy: Running the entire system on-premise avoids sending sensitive product data (pricing, inventory) to third-party APIs.
The EPM-RL approach is particularly relevant for enterprises that have historically struggled with the cost and latency of agentic LLM pipelines. The paper suggests that RL can turn product mapping from a high-latency agentic pipeline into a scalable, inspectable, production-ready in-house system.
Business Impact
The paper does not provide quantified business metrics (e.g., cost savings, accuracy improvements over specific baselines), but the qualitative implications are clear:
- Lower operational cost: By distilling reasoning into a small student model, inference becomes cheaper than repeatedly calling GPT-4 or Claude via API.
- Faster inference: No need for multi-step agent orchestration at inference time.
- Better privacy: No data leaves the enterprise network.
- Inspectability: The small model and structured reasoning outputs are easier to audit than black-box API calls.
Implementation Approach
For a retail/luxury AI team looking to adopt EPM-RL:
Prerequisites:
- Curated dataset of product pairs with human-verified labels and LLM-generated rationales (the paper's first stage)
- Access to an LLM for generating initial rationales (one-time cost)
- A small student model (e.g., a distilled BERT or small T5 variant)
- RL infrastructure (reward model, training loop)
Complexity: Medium-High. Requires ML engineering expertise in fine-tuning and RL, plus domain expertise in product mapping.
Effort: Several weeks to months, depending on data availability and team experience.
Governance & Risk Assessment
- Privacy: Strong. On-premise deployment ensures no data leakage to third parties.
- Bias: The quality of the judge model and reward design directly impacts fairness. If the judge model has biases (e.g., against certain product categories or languages), those will propagate.
- Maturity: Preliminary results only. The paper does not report accuracy on large-scale benchmarks or real-world production data. Deploying in production would require extensive validation.
- Model drift: Product titles and marketplace behaviors evolve. The RL model may need periodic retraining.
gentic.news Analysis
EPM-RL arrives at a time when the industry is grappling with the cost and complexity of agentic AI. Our prior coverage of the "LLM-as-a-Judge Framework" (April 27, 2026) and the security framework for autonomous agents in commerce (April 21, 2026) both highlighted the tension between capability and operational cost. EPM-RL directly addresses this by distilling agentic reasoning into a smaller, cheaper model.
The paper's use of reinforcement learning (mentioned in 59 prior gentic.news articles) is notable. RL is increasingly being applied beyond game-playing to optimize real-world business processes. The recent "ReCast" paper (April 27, 2026) showed how RL can fix sparse-hit learning in generative models – a similar spirit of using RL for practical efficiency gains.
However, readers should be cautious. The paper reports "preliminary results" only, with no large-scale benchmark. The quality of the judge model and the reward design are critical – and the paper does not provide details on how these were constructed or validated. As with any RL-based system, reward hacking is a real risk.
For luxury brands with sensitive pricing data, the on-premise nature of EPM-RL is a significant advantage. But the technology is not yet mature enough for mission-critical deployment without extensive internal testing.
Bottom line: EPM-RL is a promising research direction that tackles a real pain point – the cost and privacy challenges of LLM-based product mapping. Watch this space, but don't rush to production.