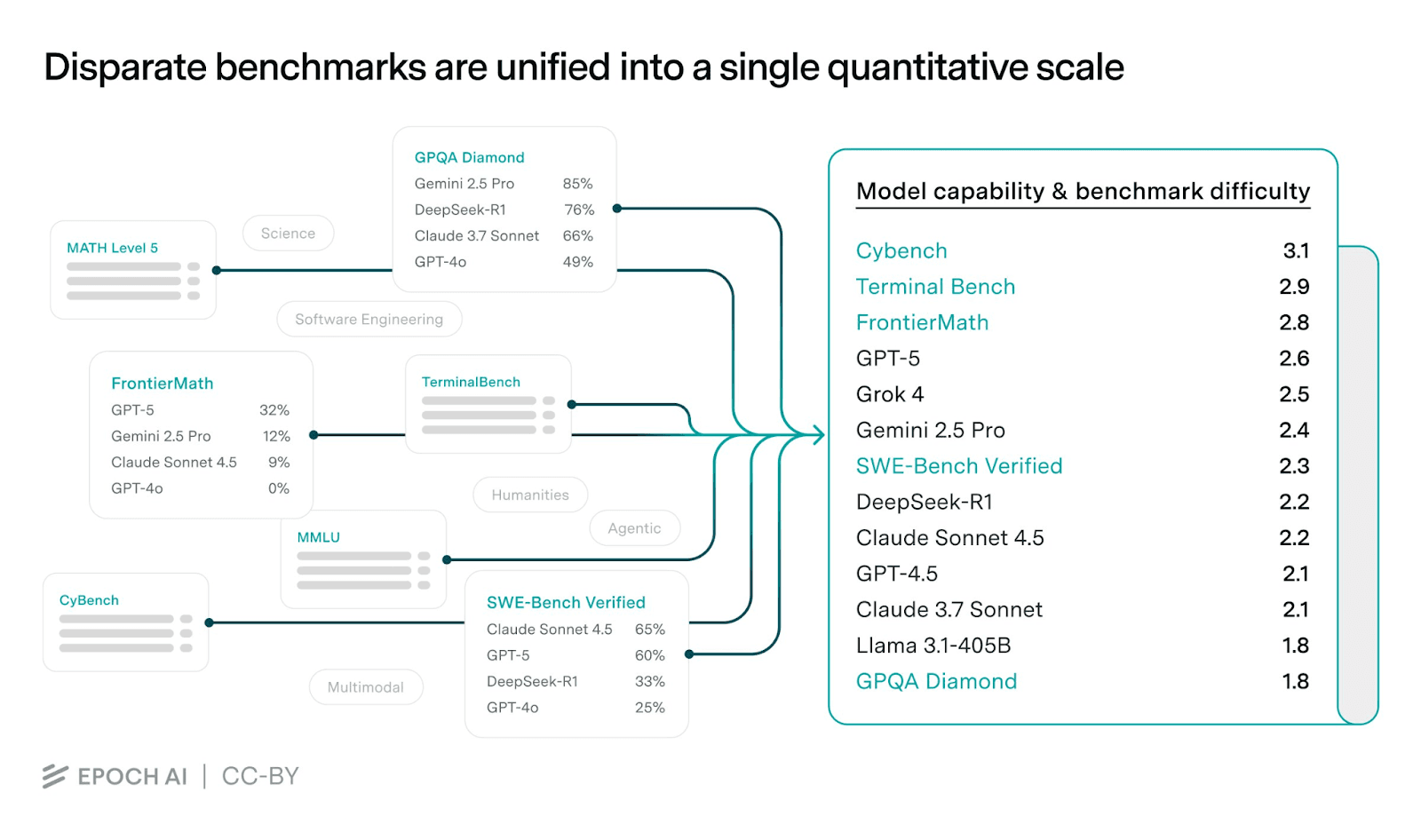
Epoch AI released CursorBench, a benchmark for AI code editors. It evaluates 500+ real-world editing tasks, measuring accuracy and latency.
Key facts
- 500+ real-world code editing tasks in CursorBench.
- 15% accuracy gap between top models and humans.
- 3x latency variation across tested models.
- Covers Python, JavaScript, TypeScript, and Go.
- First benchmark for agentic multi-file editing.
Epoch AI published CursorBench, a new benchmark designed to evaluate AI-powered code editing tools like Cursor, Claude Code, and GitHub Copilot. The benchmark covers 500+ tasks derived from real-world pull requests, measuring both correctness of edits and execution speed According to Epoch AI.
CursorBench fills a gap left by SWE-bench and HumanEval, which test isolated code generation rather than iterative editing workflows. The benchmark's task set includes bug fixes, feature additions, and refactoring across Python, JavaScript, TypeScript, and Go. Each task provides a codebase snapshot, a natural language instruction, and a ground-truth diff.
Early results show a 15% accuracy gap between top models and human performance, with latency varying 3x across models. The benchmark also measures edit precision—whether models introduce unintended changes. Epoch AI plans to release leaderboards and a public evaluation harness.
Why This Benchmark Matters
CursorBench arrives as AI code editors shift from autocomplete to agentic multi-file editing. Cursor, valued at $9B+, recently announced a GPT-size model trained from scratch for code generation [per prior coverage]. Claude Code and GitHub Copilot also target the same workflow. CursorBench provides the first standardized test for this emerging category, potentially becoming the de facto metric for code editing agents.
How It Works
Tasks are sourced from open-source repositories with verified pull request diffs. Models receive the repository state before the PR and must output the correct diff. Evaluation includes exact match, edit distance, and functional correctness via test suites. Latency is measured end-to-end including inference and context loading.
Epoch AI's methodology mirrors SWE-bench but focuses on smaller, more frequent edits typical of daily development—not whole-repository patches. This makes CursorBench more representative of real-time coding assistant use.
Key Takeaways
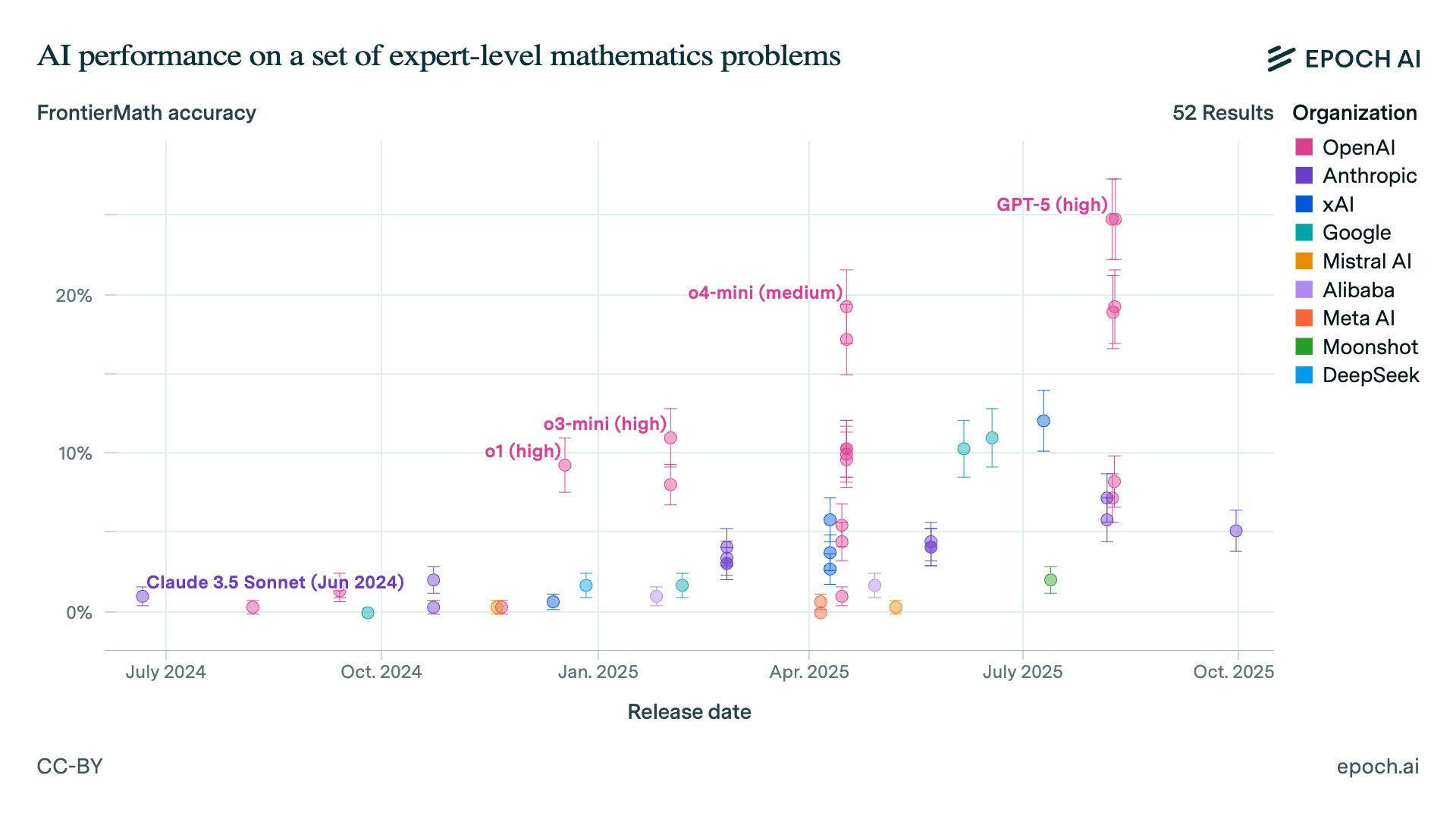
- Epoch AI launched CursorBench, a 500-task benchmark for AI code editors.
- It reveals a 15% accuracy gap vs.
- humans and 3x latency variance.
What to watch
Watch for the first public CursorBench leaderboard release, expected within two weeks, and whether Cursor's new custom model closes the 15% gap to human performance.
Source: news.google.com
[Updated 28 Jun via epoch_ai_gradient_updates_gn]
Alongside CursorBench, Epoch AI also introduced MirrorCode, a benchmark testing whether AI can reconstruct entire programs from behavioral descriptions alone. MirrorCode tasks models with rebuilding software from scratch based on input-output examples, aiming to measure the upper bound of autonomous coding. Early results show even top models fail on projects exceeding 500 lines, highlighting a sharp capability ceiling in end-to-end software generation [per Epoch AI].