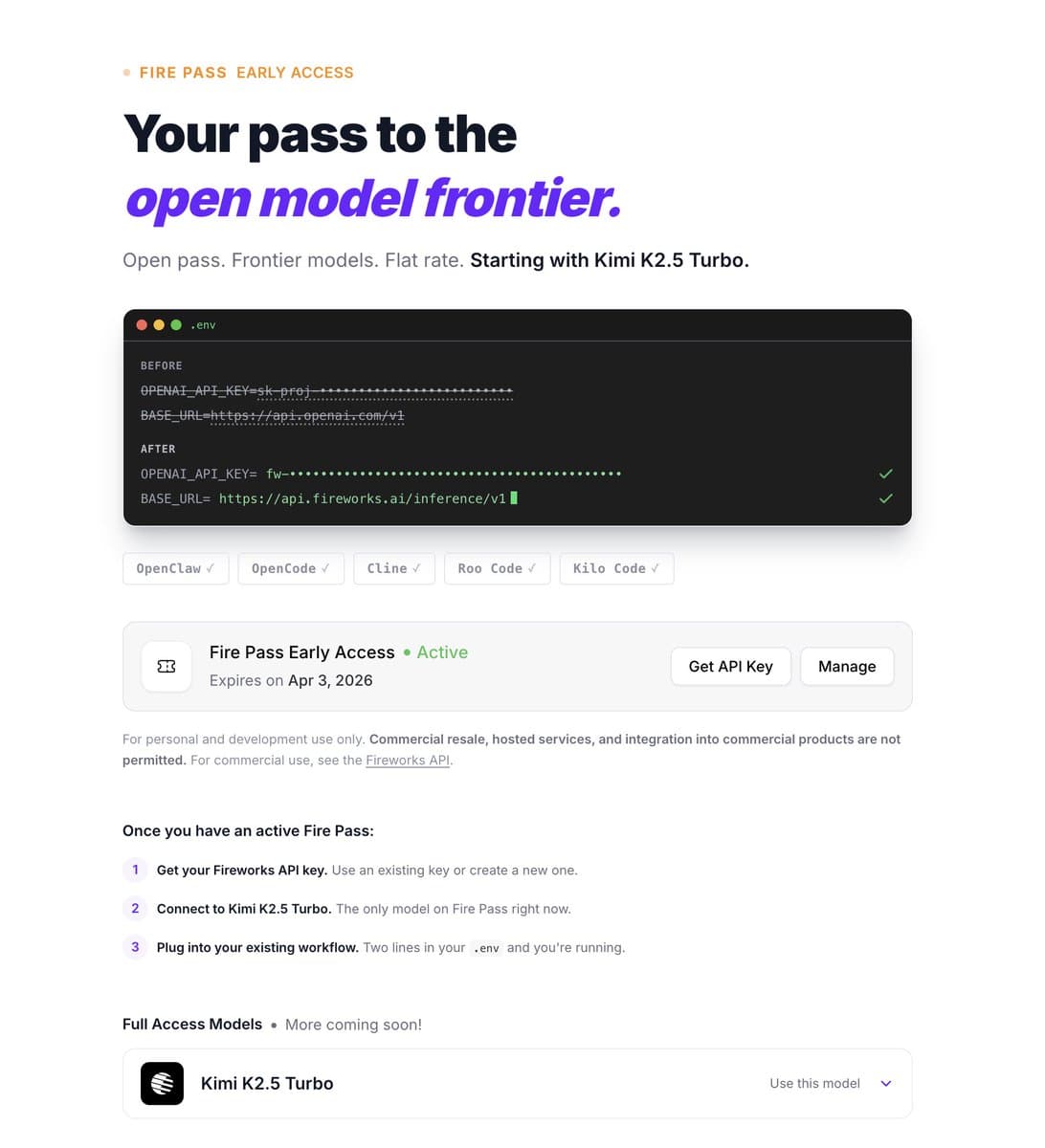
Fireworks AI has launched a new subscription service called "Fire Pass" that provides high-speed access to the Kimi K2.5 Turbo model, according to early user reports. The service is currently delivering inference speeds of approximately 250 tokens per second with reportedly high rate limits.
What's Available
The Fire Pass subscription offers:
- Model Access: Kimi K2.5 Turbo, a high-performance model from Moonshot AI
- Inference Speed: Approximately 250 tokens/second based on initial user testing
- Pricing: $7 per week after a free trial period
- Rate Limits: Described as "HIGH" by early testers, though specific limits haven't been officially published
Technical Context
Kimi K2.5 Turbo is Moonshot AI's latest model iteration, building on their Kimi Chat platform which gained attention for its exceptionally long context window capabilities (up to 200K tokens). The "2.5" designation suggests incremental improvements over previous versions, though Moonshot AI hasn't released detailed technical specifications for this particular variant.
Fireworks AI operates as an inference platform that optimizes and serves various large language models through API endpoints. Their infrastructure is designed to maximize throughput and minimize latency, which aligns with the high-speed performance reported for the Fire Pass service.
Market Positioning
The $7 weekly pricing ($28-30 monthly equivalent) positions Fire Pass between consumer-focused AI subscriptions like ChatGPT Plus ($20/month) and more expensive enterprise offerings. The combination of Kimi's technical capabilities with Fireworks' inference optimization creates a potentially competitive offering for developers and power users who prioritize speed and cost-effectiveness.
Limitations and Unknowns
Based on the available information, several questions remain:
- Exact rate limits and usage caps
- Whether the service includes other models beyond Kimi K2.5 Turbo
- Geographic availability and regional restrictions
- SLA guarantees and reliability metrics
- Comparison of performance against direct API access to Kimi models
Fireworks AI has not yet published official documentation or announcements about the Fire Pass service, so these details may emerge as the offering becomes more widely available.
gentic.news Analysis
This launch represents Fireworks AI's continued expansion beyond pure infrastructure-as-a-service into curated model access—a strategic move we've seen from other inference providers like Together AI and Anyscale. The focus on Kimi K2.5 Turbo is particularly interesting given Moonshot AI's recent momentum in the long-context space, where they've consistently pushed boundaries with context windows far exceeding typical models.
The 250 tokens/second speed is noteworthy but requires context: this represents throughput (tokens per second), not necessarily latency (time to first token). For batch processing or applications requiring high-volume generation, this throughput could be significant, but real-time interactive applications might prioritize different metrics.
The $7 weekly pricing suggests Fireworks is targeting individual developers and small teams rather than enterprise customers. This aligns with a broader trend of AI infrastructure companies creating tiered offerings that serve both individual developers and large organizations. The success of this model will depend on whether the performance and cost advantages justify the subscription over using Kimi's API directly or other model providers.
Frequently Asked Questions
What is Fireworks AI Fire Pass?
Fireworks AI Fire Pass is a new subscription service that provides access to the Kimi K2.5 Turbo model at high speeds (approximately 250 tokens/second) for $7 per week after a free trial. It's designed for developers and users who need fast, reliable access to this specific model.
How does Kimi K2.5 Turbo compare to other models?
Kimi K2.5 Turbo is Moonshot AI's latest model iteration, known for exceptional long-context capabilities (up to 200K tokens in previous versions). While detailed benchmarks aren't available for this specific variant, the Kimi family has generally performed well on tasks requiring long document understanding and complex reasoning.
Is the 250 tokens/second speed guaranteed?
The 250 tokens/second figure comes from early user testing, not official documentation. Actual performance may vary based on workload, network conditions, and system load. Fireworks AI hasn't published performance SLAs for this service yet.
What are the alternatives to Fireworks AI Fire Pass?
Alternatives include direct API access to Kimi models through Moonshot AI, other inference platforms like Together AI or Anyscale that may offer Kimi models, or competing models with similar capabilities from providers like Anthropic (Claude), OpenAI (GPT-4), or Google (Gemini).








