
What Happened
A groundbreaking theoretical paper published on arXiv challenges one of machine learning's most fundamental assumptions: "Garbage In, Garbage Out." The research, titled "From Garbage to Gold: A Data-Architectural Theory of Predictive Robustness," provides a mathematical framework explaining why modern models can achieve state-of-the-art performance using high-dimensional, collinear, and error-prone tabular data.
The authors—synthesizing principles from Information Theory, Latent Factor Models, and Psychometrics—demonstrate that predictive robustness emerges not from data cleanliness alone, but from the synergy between data architecture and model capacity. This represents a paradigm shift in how we think about data quality for enterprise AI applications.
Technical Details
The paper makes several key theoretical contributions:
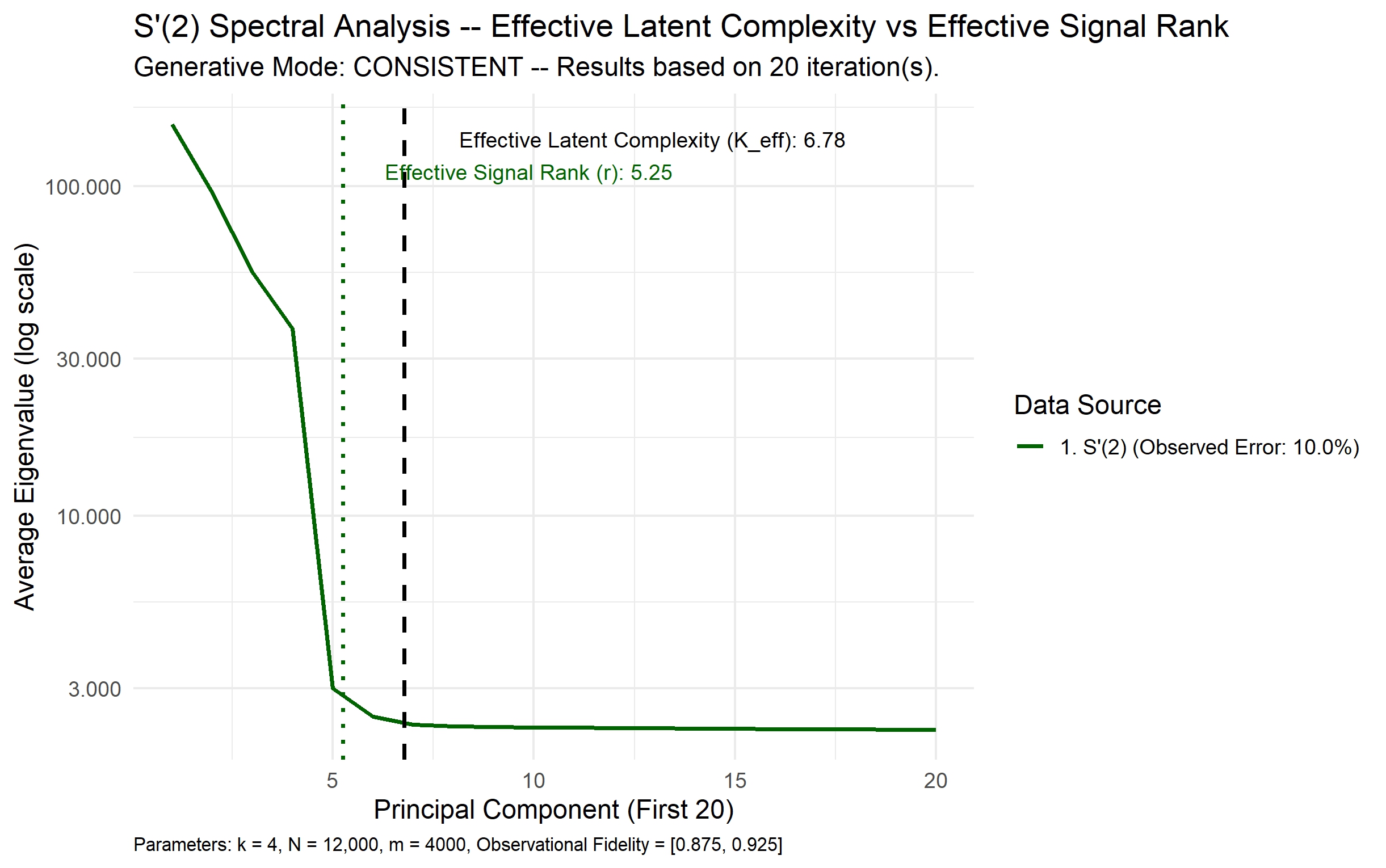
1. Partitioning Predictor-Space Noise
The researchers decompose what's traditionally called "noise" into two distinct components:
- Predictor Error: Measurement errors or inaccuracies in individual predictors
- Structural Uncertainty: Informational deficits arising from stochastic generative mappings between latent factors and observed variables
They prove mathematically that leveraging high-dimensional sets of error-prone predictors can asymptotically overcome both types of noise, whereas cleaning a low-dimensional dataset is fundamentally bounded by Structural Uncertainty.
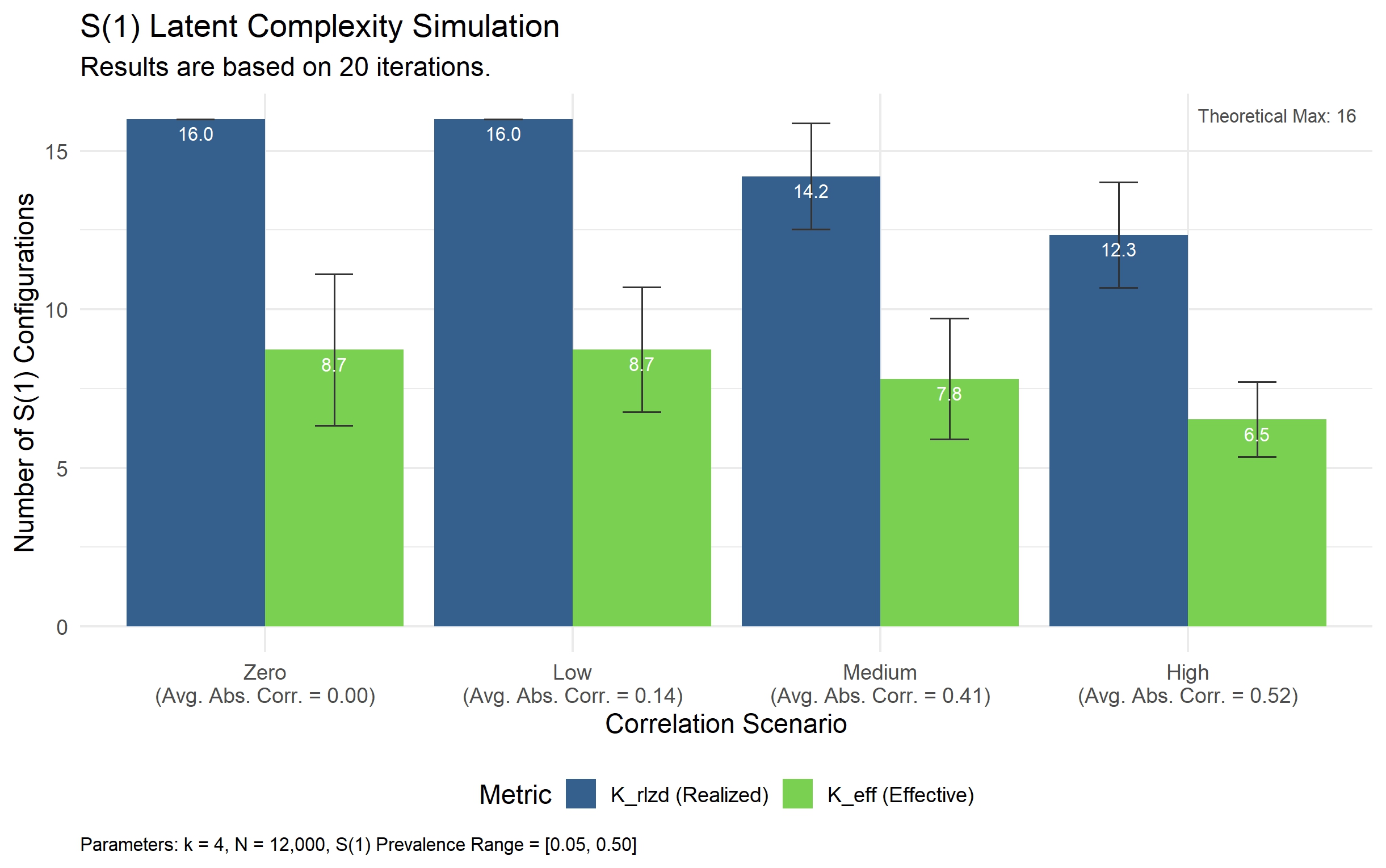
2. The Power of Informative Collinearity
The paper demonstrates why dependencies between predictors (collinearity) that arise from shared latent causes actually enhance model reliability and convergence efficiency. This "Informative Collinearity" reduces the latent inference burden on the model, making robust predictions feasible with finite samples.
3. Proactive Data-Centric AI
Moving beyond traditional data cleaning approaches, the authors propose "Proactive Data-Centric AI"—a methodology to identify which predictors enable robustness most efficiently. This involves:
- Deriving boundaries for Systematic Error Regimes
- Showing how models that absorb "rogue" dependencies can mitigate assumption violations
- Linking latent architecture to the phenomenon of Benign Overfitting
4. From Model Transfer to Methodology Transfer
The most significant practical implication is the theoretical rationale for "Local Factories"—learning directly from live, uncurated enterprise "data swamps." This supports a deployment paradigm shift from "Model Transfer" (moving trained models between environments) to "Methodology Transfer" (applying consistent learning approaches to local data).
The paper redefines data quality from item-level perfection to portfolio-level architecture, providing a mathematical foundation for working with messy, real-world enterprise data.
Retail & Luxury Implications
The Enterprise Data Reality
Luxury and retail companies sit on vast "data swamps"—customer transaction histories with missing values, inconsistent product categorization, merged datasets from acquisitions, and real-time operational data with varying quality standards. Traditional approaches would require extensive cleaning before modeling, creating bottlenecks and limiting agility.
This research provides theoretical justification for a different approach: embracing the mess and architecting data systems that leverage high-dimensional, redundant information.
Practical Applications
Customer Lifetime Value Prediction: Instead of painstakingly cleaning every customer attribute, companies could include hundreds of potentially noisy signals—social media engagement metrics, customer service interaction transcripts, in-store visit patterns, and third-party demographic estimates. The theory suggests that with proper architecture, the model can extract robust signals despite individual data quality issues.
Demand Forecasting: Retailers often struggle with incomplete historical data, especially for new products or in new markets. The framework suggests that including correlated but imperfect predictors (weather data, local event calendars, social sentiment, competitor pricing scrapes) can overcome gaps in primary sales data.
Personalization Systems: The "Informative Collinearity" concept explains why including multiple, partially redundant customer behavior signals (browsing history, wishlist items, past purchases, email engagement) often works better than trying to identify the "perfect" single predictor.
Implementation Considerations
While the theory is compelling, practical implementation requires:
- Computational Infrastructure: High-dimensional modeling demands significant resources
- Monitoring Systems: Understanding when models are leveraging "rogue" dependencies versus meaningful signals
- Governance Frameworks: New approaches to data quality assessment focused on portfolio architecture rather than individual field perfection
Business Impact
The most immediate impact is reduced time-to-value for AI initiatives. Companies can begin modeling with existing data architectures rather than waiting for extensive cleaning projects. This aligns particularly well with the luxury sector's need for agility in responding to rapidly changing consumer preferences.
Longer term, the shift toward "Methodology Transfer" could enable more consistent AI performance across global markets, as local teams apply proven approaches to their specific data environments rather than trying to adapt centralized models.
Implementation Approach
Technical Requirements
- Modern gradient boosting implementations (XGBoost, LightGBM, CatBoost) or neural networks capable of handling high-dimensional tabular data
- Infrastructure for real-time feature engineering from diverse data sources
- Monitoring systems to track model performance across different data quality regimes
Complexity Level: Medium-High
While the theoretical insight is profound, practical implementation requires sophisticated MLOps practices and careful experimentation. The transition from traditional data cleaning approaches represents a significant cultural and technical shift for most organizations.
Governance & Risk Assessment
Privacy Considerations
High-dimensional modeling often involves combining data from multiple sources, potentially increasing privacy risks. Companies must ensure compliance with GDPR, CCPA, and other regulations when implementing these approaches.

Bias Amplification
Models that leverage "rogue" dependencies might inadvertently amplify existing biases in enterprise data. Robust bias testing and mitigation strategies become even more critical.
Maturity Level: Theoretical Foundation
This research provides theoretical justification for approaches that some advanced teams are already using empirically. The framework helps explain why certain practices work and provides guidance for more systematic implementation.
Conclusion
The "From Garbage to Gold" research represents a fundamental shift in how we think about data quality for machine learning. For luxury and retail companies sitting on vast, messy enterprise data, it offers both theoretical validation and practical guidance for building more robust, agile AI systems.
The key insight isn't that data quality doesn't matter, but that data architecture matters more. By strategically designing predictor portfolios and embracing high-dimensional, redundant information sources, companies can extract gold from what was previously considered garbage.








