Integration test failures are a notorious time-sink for developers. The root cause is often buried in thousands of lines of messy, unstructured log output, forcing engineers into a manual, frustrating search. New research from Google tackles this problem head-on with TestPilot, an AI-powered agent designed to autonomously diagnose and debug integration test failures.
Key Takeaways
- Google introduced TestPilot, an AI agent that diagnoses integration test failures by sifting through logs and suggesting code fixes.
- It autonomously resolved 15% of real-world Python test failures in an experiment.
What the Agent Does

TestPilot is an autonomous system that takes a failing integration test as input and attempts to produce a correct, actionable fix. Its core capability is navigating the complex, multi-step debugging workflow that a human engineer would follow:
- Parsing Logs: It ingests the massive, often unstructured log output from a failed test run.
- Hypothesis Generation: Based on the logs and the test code, it formulates potential root causes for the failure.
- Code Exploration & Validation: It can read relevant source files, run additional diagnostic commands (like
git blameorgrep), and execute code to test its hypotheses. - Patch Generation: If it identifies a likely bug, it generates a suggested code patch to resolve the issue.
The system operates in a loop, using the outputs from its actions (new logs, command results) to refine its understanding and guide its next step, mimicking a developer's iterative debugging process.
Key Results & Performance
In an experimental evaluation on a dataset of real-world, flaky integration tests from large-scale Python projects, TestPilot demonstrated its practical utility:
- Autonomous Resolution Rate: The agent autonomously produced the correct fix for 15% of the failing tests.
- Action Efficiency: It executed a median of 19 actions (like reading files or running commands) per debugging session.
- Human-in-the-Loop Potential: For a much larger portion of failures, TestPilot successfully identified the root cause and relevant code, even if it didn't generate the final patch. This output can dramatically accelerate a human developer's work by pinpointing the problem area.
The research highlights that the 15% fully autonomous fix rate, while not a majority, represents a meaningful automation of a complex, high-cognitive-load task that currently consumes significant engineering hours.
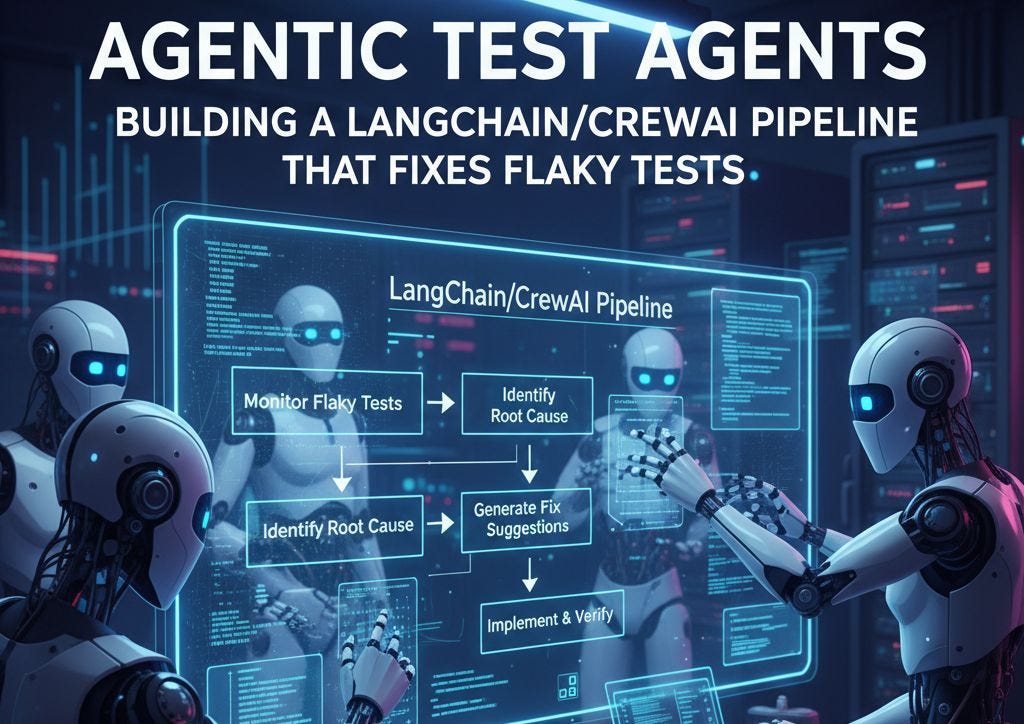
How TestPilot Works: Architecture & Training
TestPilot is built as a plan-and-execute agent powered by a large language model (LLM). The architecture separates high-level planning from precise tool execution.
- Planner: A large LLM (like Gemini or GPT-4) acts as the "brain." Given the current state (test failure, logs, previous actions), it decides on the next high-level action (e.g., "Read the source code of module X," "Run command Y to check system state").
- Tools & Executor: The planner's decisions are translated into concrete executions by a set of tools. These tools include a code editor (to read/write files), a command-line executor, and a test runner. The executor runs the action and returns the results (code content, command output, new test status) to the planner for the next cycle.
Crucially, TestPilot was not trained from scratch on this specific task. Instead, it uses in-context learning and few-shot prompting. The system is provided with examples of successful debugging trajectories in its prompt, allowing a powerful pre-trained LLM to generalize to new test failures. This approach bypasses the need for massive, task-specific fine-tuning datasets.
Why It Matters: From Flaky Tests to Reliable CI/CD
Integration tests are essential for verifying that different parts of a software system work together correctly. However, they are often brittle, non-deterministic ("flaky"), and painfully slow to debug. This creates bottlenecks in continuous integration and deployment (CI/CD) pipelines.
TestPilot addresses the debugging bottleneck, not just the test execution bottleneck. While other AI coding tools focus on generating code or unit tests, TestPilot targets the downstream, more chaotic problem of failure analysis. Its value proposition is reducing mean time to resolution (MTTR) for CI failures.
For engineering teams, especially at scale, even a 15% reduction in manual debugging for integration failures could free up hundreds of developer-hours for feature work instead of forensic log analysis.
gentic.news Analysis
This research from Google is a strategic move into a high-value, under-automated niche of the software development lifecycle. While AI pair programmers like GitHub Copilot have focused on code creation, and agents like Devin from Cognition AI aim for full-task automation, TestPilot zeroes in on the specific, painful, and costly problem of post-failure diagnostics. This aligns with a broader trend we identified in our 2025 coverage of the "MLOps Observability" sector, where AI is increasingly applied not to building systems but to maintaining and understanding them.
The use of a plan-and-execute agent architecture with rich tools (code editor, shell) mirrors the approach taken by other advanced coding agents, suggesting a convergence on this paradigm for complex, multi-step software tasks. However, Google's focus on integration tests—a domain with massive, noisy data (logs)—is distinct. It leverages the LLM's strength in pattern recognition and reasoning over unstructured text.
This work also subtly reinforces the strategic importance of large-scale, proprietary datasets. Google's ability to experiment on "real-world, flaky integration tests from large-scale Python projects" is a competitive advantage. It provides a testing ground that is far more representative of the messy reality of enterprise software than curated benchmarks like SWE-Bench. As we noted in our analysis of "Google's Gemini 2.0: The Infrastructure Play," the company's vast internal codebase serves as a unique R&D lab for AI-for-engineering tools. TestPilot is a direct product of that environment. If this technology matures, it could become a key differentiator for Google's cloud and developer platform offerings, directly attacking a core pain point for their largest enterprise customers.
Frequently Asked Questions
What is an integration test?
An integration test verifies that different modules or services within an application work correctly together. Unlike a unit test that checks a single function, an integration test might simulate a user logging in, which involves the frontend, authentication service, and database all interacting. These tests are complex and often fail due to subtle environment or timing issues, making them hard to debug.
How is TestPilot different from GitHub Copilot?
GitHub Copilot is primarily a code completion and generation tool that assists as you write code. TestPilot is an autonomous debugging agent that acts after a test has failed. It takes the failure and logs as its starting point, then plans and executes a series of investigative actions (reading code, running commands) to diagnose the root cause, a task Copilot is not designed to do.
Does TestPilot work with any programming language?
The published research paper details experiments conducted on Python integration tests. The architecture is language-agnostic in principle, as it relies on the LLM's understanding of code and tools like a shell. However, its effectiveness would depend on the LLM's proficiency in other languages and the availability of appropriate tooling (e.g., a Java compiler) in its execution environment.
Is TestPilot available to use now?
No. TestPilot is a research project from Google, detailed in an academic paper. It is not a publicly released product or API. The research demonstrates a proof-of-concept and its results. It may inform future features within Google's cloud developer tools or remain an internal capability.