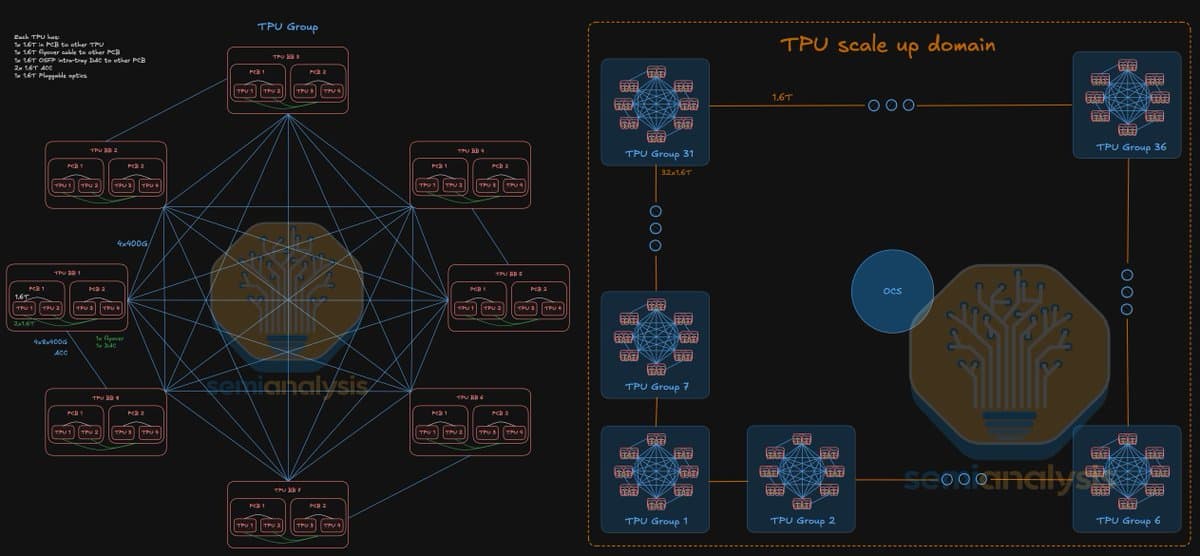
Google unveiled a new inference TPU with a Broadfly network topology at Cloud Next in Las Vegas. The design scales a single pod to 1,152 chips — 4.5x larger than the previous Ironwood generation.
Key facts
- 1,152 TPUs per pod with Broadfly topology.
- 4.5x larger pod than Ironwood generation.
- Maximum 7 hops between any two TPUs.
- Unveiled at Google Cloud Next in Las Vegas.
- Focus is inference, not training.
At Google Cloud Next in Las Vegas, Google detailed a new inference-focused TPU that abandons traditional torus or fat-tree interconnects. The chip uses a novel topology called "Broadfly," first described by @SemiAnalysis_.
How Broadfly works
Broadfly is a high-radix network design that packs more direct connections per TPU, reducing the number of hops data must traverse. In a 1,152-chip pod, the maximum hop count between any two TPUs is just 7 — a stark contrast to Ironwood's larger network diameter. This tighter coupling cuts inference latency for models that require cross-chip communication, such as mixture-of-experts (MoE) architectures or large-scale transformer serving.
Why this matters
The 4.5x pod-size increase over Ironwood is not merely a density play. By keeping hop count low at scale, Google can serve models with larger memory footprints — think 1T+ parameter MoEs — without hitting the communication bottlenecks that plague ring-based topologies. The unique take: Broadfly effectively inverts the traditional trade-off between scale and latency. Most interconnects force a choice between big pods (high diameter) or low latency (small pods). Google's design claims both.
Competitive context
NVIDIA's NVLink-based DGX systems top out at 576 GPUs per domain (Hopper generation), with a maximum of 8 hops in a 576-GPU Dragonfly+ topology. Broadfly's 1,152-chip pod with 7 hops doubles the scale while maintaining comparable or better diameter. Google did not disclose the per-chip bandwidth or whether the TPU uses optical interconnects; those details will likely surface in a paper or at a future conference.
Inference-first design
The focus on inference — not training — signals Google's intent to capture the growing model-serving market. As inference workloads shift toward larger batch sizes and longer context windows (e.g., 1M-token Claude or Gemini), network topology becomes a first-order latency factor. Broadfly's high-radix, low-diameter design is purpose-built for this regime.
Key Takeaways
- Google unveiled a Broadfly TPU topology at Cloud Next, scaling pods to 1,152 chips — 4.5x larger than Ironwood — with max 7 hops.
- This inference-first design challenges NVIDIA's NVLink on scale and latency.
What to watch

Watch for Google to publish a detailed paper on Broadfly's routing algorithm and per-chip bisection bandwidth at ISCA or SC26. Also track whether Google Cloud offers the 1,152-chip pod as a single reservation unit — that would signal enterprise inference demand.