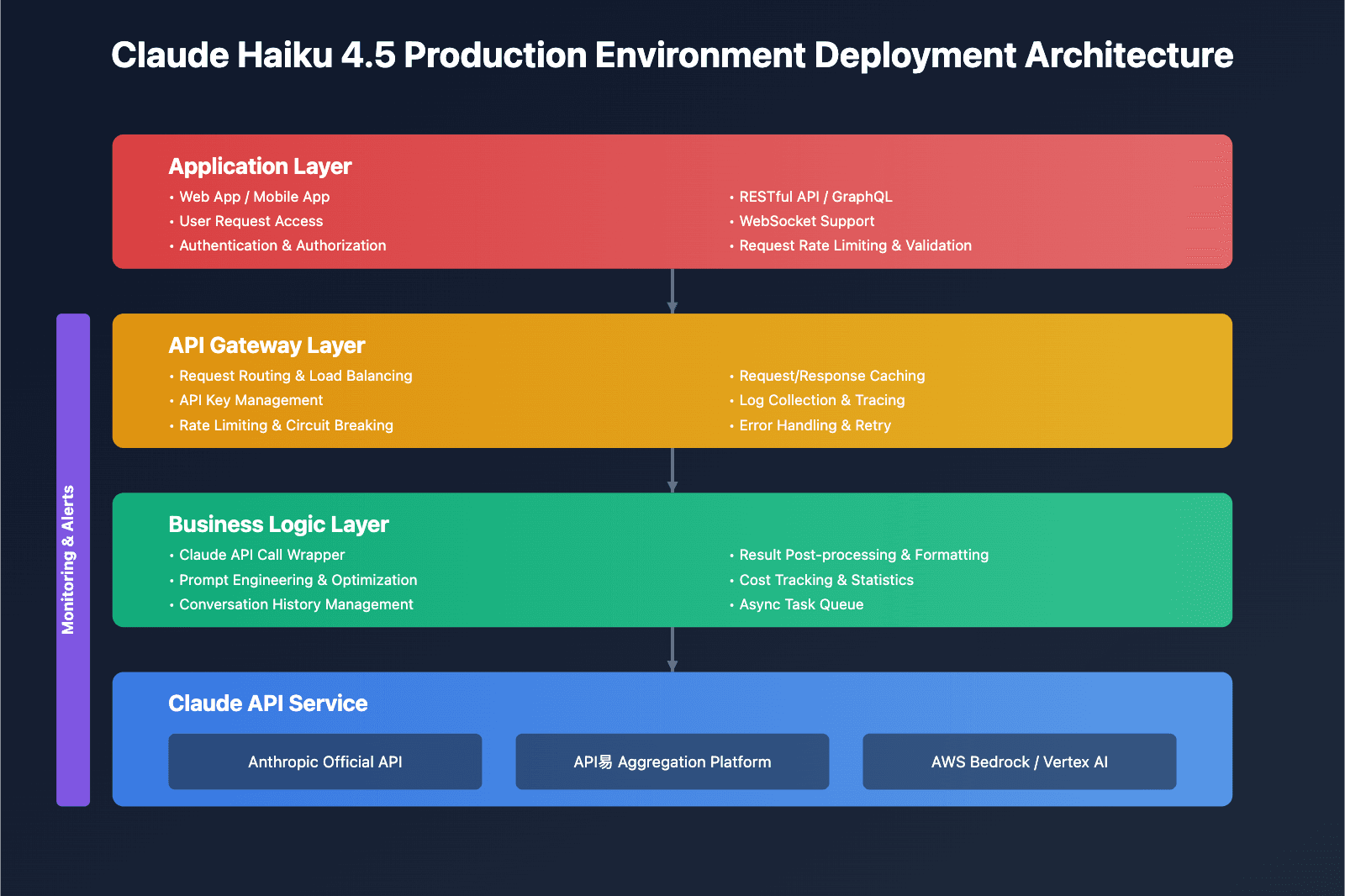
What Changed — A Solo Developer's AI-Powered Database

A nursing student at NYU just published The Drug Database — a free, no-signup pharmaceutical reference with over 660,000 pages covering drug profiles, conditions, drug classes, and pre-generated comparisons. The source data comes from RxNorm, FDA DailyMed, MED-RT, and DrugBank, with over 1.57 million drug-drug interaction rows.
The key technical insight? Claude Haiku powered the classification layer that organized thousands of conditions across dozens of medical specialties. The student used Haiku where rigid rule-based systems would have failed — mapping ingredients to brand names, brand names to conditions, conditions to drug classes, and drug classes back to every drug that treats them.
This isn't a demo. It's a production site with a site-wide issue reporting tool already live.
What It Means For You — Claude Haiku as a Classification Engine
Most Claude Code users reach for Sonnet or Opus for complex tasks. This project demonstrates a smarter pattern: use Haiku for bulk classification jobs where cost matters and accuracy is good enough.
Haiku is 5x cheaper than Sonnet and 20x cheaper than Opus. For batch-processing thousands of medical records into a connected knowledge graph, that cost difference is the difference between "I can build this" and "I need a grant."
The student's approach mirrors what we covered in "Doby Cuts Claude Code Navigation Tokens by 95% with Spec-First Workflow" — using a cheaper model for the heavy lifting and reserving expensive models for the edge cases.
Try It Now — Applying This to Your Projects
1. Use Haiku for Bulk Classification
# Example: Classify a CSV of product descriptions using Claude Code
claude code --model haiku
Then in your prompt:
I have a CSV of 10,000 medical conditions. Classify each one into its specialty
(cardiology, neurology, etc.) and output a new CSV with the specialty column added.
Use the MED-RT ontology as a reference. If uncertain, mark as "unclassified."
2. Build a Knowledge Graph with Haiku
The student's architecture is instructive: Haiku doesn't just classify — it connects. Every entity maps to related entities. You can replicate this pattern:
# CLAUDE.md — for knowledge graph projects
- Use Haiku for initial classification passes
- Reserve Opus for conflict resolution and edge cases
- Always output structured JSON with entity IDs and relationship arrays
- Validate against a schema before committing to the database
3. Cost-Effective Iteration
# Run a Haiku pass on 10,000 records
claude code --model haiku --cost-limit 0.50
# Then review and fix with Opus only on flagged items
claude code --model opus "Review the unclassified items from haiku_output.json and resolve them"
Why Haiku Worked Here
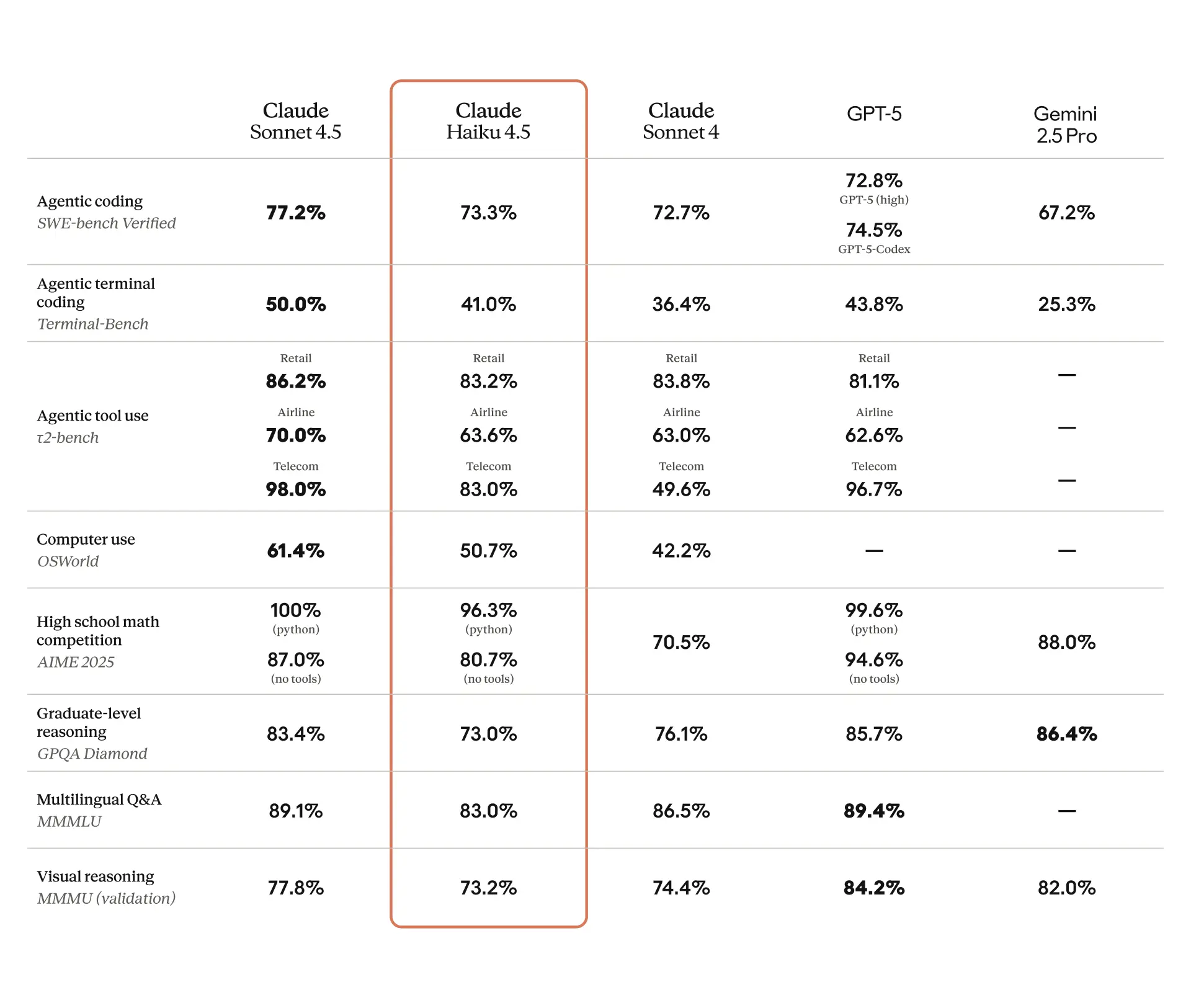
The medical domain is high-stakes, but classification is a bounded task. Haiku doesn't need to reason about treatment protocols — it needs to recognize that "atrial fibrillation" maps to "cardiology." That's pattern matching, not deep reasoning.
This aligns with Anthropic's model hierarchy: Haiku excels at structured, repetitive tasks with clear inputs and outputs. The student's success validates using Haiku for the 80% of work that doesn't require Opus-level reasoning.
The Takeaway
You don't need a team or a budget to build production-grade knowledge systems. Claude Haiku, combined with public data sources and a clear schema, can handle classification at scale. The constraint isn't the model — it's whether you can define the relationships clearly enough.
Check out The Drug Database to see the result. Then ask yourself: what dataset in your domain could benefit from the same approach?
gentic.news Analysis
This story fits a pattern we've tracked across 644 Claude Code articles: solo developers using cheaper models for bulk work. The student's use of Haiku mirrors the trend we've seen with Claude Code users adopting Sonnet 4.6 for coding and reserving Opus 4.6 for debugging — a tiered model strategy that optimizes cost without sacrificing quality.
Notably, this project uses public data sources (RxNorm, FDA DailyMed) rather than proprietary APIs. This is a growing pattern in the Claude ecosystem: developers combine Anthropic models with open data to create tools that compete with paid services. We saw a similar approach in our coverage of "Cua Driver Open-Sourced" — the community building on public infrastructure.
The student's success also validates Haiku 4.5's positioning. While Opus 4.6 grabbed headlines with its 94.1% ThermoQA score (covered April 23), Haiku quietly handles the production workloads that actually ship products. For Claude Code users, the lesson is clear: match the model to the task, not the hype.






