
A quiet but critical infrastructure layer for the global humanoid robotics boom is being built in India. Workers are being equipped with cameras and sensors to film thousands of first-person demonstrations of mundane hand tasks. The goal is not to automate these workers' jobs immediately, but to capture the subtle, implicit knowledge of physical interaction—grip angles, finger timing, slip correction, and force application—that robots currently lack.
This process creates supervised datasets where visual input (what the camera sees) is paired with the correct physical action (hand and finger movements). These datasets are then used to train AI models that map perception to action, a foundational requirement for dexterous humanoid robots.
Key Takeaways
- Labs in India are capturing detailed human motion data—focusing on grip, force, and error recovery—to train AI models for humanoid robots.
- This addresses the critical bottleneck of acquiring physical intelligence data for robotics.
What's Being Collected: The "Missing Layer" of Physical Intelligence

The core insight driving this data collection is that robots fail on tiny physical details long before they fail on high-level planning. Programming a robot to "fold a towel" requires not just an abstract sequence, but the micro-adjustments a human makes instinctively.
The data capture focuses on:
- Ordinary hand tasks: Grasping, folding clothes, sorting objects, using simple tools.
- First-person perspective: Cameras are mounted on the workers to record exactly what their eyes see, creating a direct visual context for each action.
- Motion sequences: The valuable output is not just a video of a folded towel, but a temporal sequence of hand positions, joint angles, and force profiles.
- Error recovery: Crucially, the recordings include moments where the human recovers from a slip or mis-grip, providing invaluable data for robust, real-world operation.
As described in the source, "The useful part is not the towel or box itself but the sequence: where the hand starts, how force changes, when fingers adjust, and how the body recovers from small mistakes."
Why This Data is Critical for the Humanoid Boom
The recent surge in humanoid robot prototypes from companies like Tesla (Optimus), Figure, 1X Technologies, and Boston Dynamics has highlighted a major bottleneck: a lack of large-scale, high-quality data on physical interaction. While large language models (LLMs) are trained on trillions of tokens of text scraped from the web, there is no equivalent "web of physical actions."
This human-collected data addresses several key challenges:
- Bypassing Hand-Coding: It is prohibitively expensive and brittle to hand-code the physics and control rules for every possible object and task. Learning from demonstration is a more scalable path.
- Providing Supervised Labels: In each video clip, the human's successful action provides the "ground truth" label for what the robot should do given that visual input. This is the fuel for training visuomotor control policies.
- Capturing Implicit Knowledge: Much of human dexterity is subconscious. Filming experts performing tasks captures this tacit knowledge in a machine-readable format.
The Business Model: Data as the New Oil for Robotics
This activity positions India as a key supplier in the global AI robotics supply chain—not for hardware, but for the foundational data required to animate that hardware. The economic model is clear: the current cost of collecting this detailed physical data in North America or Europe is extremely high. By leveraging a large workforce where labor costs are lower, companies and research labs can acquire massive datasets at a fraction of the price.
This is reminiscent of earlier waves of AI data annotation, where regions with lower labor costs became hubs for labeling images for computer vision and text for natural language processing. The difference here is the complexity and modality of the data—it's spatiotemporal, multi-sensor, and tied to physical embodiment.
Technical Implementation and Future Trajectory
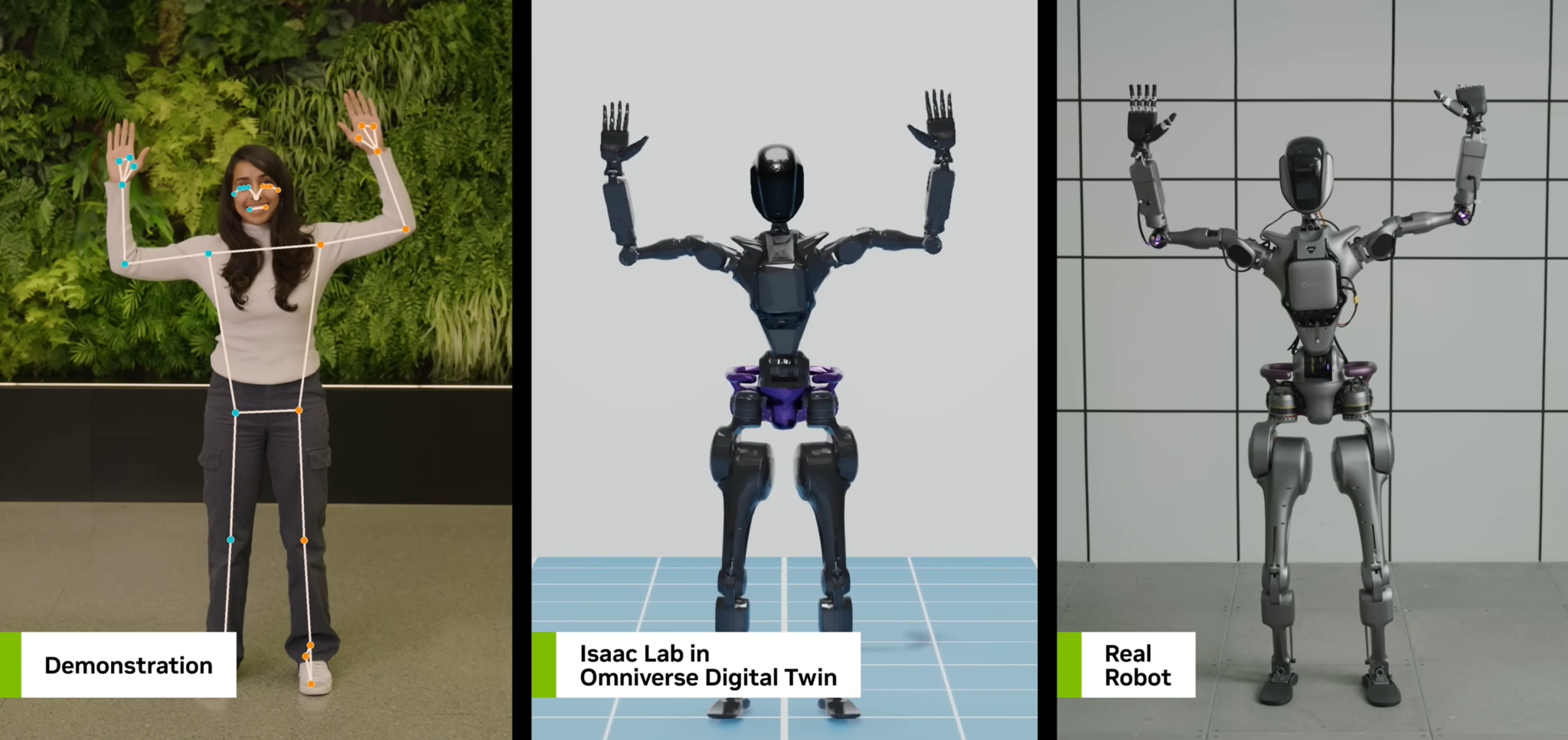
The collected data likely feeds into several technical approaches:
- Imitation Learning: Directly training a policy to mimic the human actions observed in the videos.
- Foundation Models for Robotics: Training large, general-purpose visuomotor transformer models on millions of human demonstration clips, akin to how RT-2 or other vision-language-action models are built.
- Simulation-to-Real Transfer: The human motion data can be used to create more realistic simulated environments for training robots before deployment in the real world.
The long-term arc, as noted in the source, is that "physical intelligence gets extracted before it gets automated." The very process of using human labor to train robots is what will eventually make that human labor less necessary for those specific tasks.
gentic.news Analysis
This development is a direct, pragmatic response to the most pressing bottleneck in embodied AI: the data scarcity problem for physical skills. While companies like Google DeepMind have pushed the envelope with sim-trained systems like RT-2, and OpenAI has explored reinforcement learning from human feedback for robotics, their progress is ultimately gated by access to diverse, real-world physical interaction data. The Indian "motion farms" represent an industrial-scale solution to this constraint, creating the labeled datasets needed to train the next generation of control policies.
This trend aligns with a broader shift we've covered, where the focus of competitive advantage in AI is moving from model architecture to data pipelines and curation. We saw this first in language models, where proprietary data mixtures became key differentiators. Now, for robotics, the race is to secure exclusive or high-quality sources of physical demonstration data. The entities building these data collection operations—whether they are robotics companies themselves or third-party data vendors—are building a moat that is difficult and time-consuming to replicate.
Looking forward, this activity may catalyze two developments. First, it could lead to the emergence of standardized human motion datasets (like ImageNet for robotics), accelerating academic and open-source research. Second, it raises important ethical and economic questions about data sourcing, worker compensation, and the long-term displacement of the very jobs being used for training. The narrative of "humans training their replacements" is starkly literal in this context, and the industry will need to navigate this carefully.
Frequently Asked Questions
What kinds of tasks are Indian workers filming for robots?
Workers are filming first-person perspectives of repetitive hand-based tasks that require dexterity and tactile feedback. This includes grasping objects of various shapes and weights, folding textiles like towels and clothing, sorting items into bins, and using simple tools like screwdrivers or kitchen utensils. The focus is on capturing the micro-adjustments and recovery from errors that are second nature to humans but poorly understood by machines.
Why is India becoming a hub for this type of data collection?
India offers a combination of a very large workforce and relatively lower labor costs compared to North America and Europe. Collecting high-fidelity physical demonstration data is extremely labor-intensive and expensive. By scaling this operation in a cost-effective market, companies and research labs can amass the thousands of hours of annotated video data required to train robust robot control models, making India a strategic supplier in the global AI robotics data supply chain.
How is this data used to train robot AI?
The video sequences, often paired with sensor data on hand pose and force, create supervised learning examples. Each frame of video serves as the visual input (observation), and the corresponding human hand movement serves as the correct action (label). Machine learning models, typically deep neural networks, are trained on millions of these examples to learn a policy: a function that maps what the robot's cameras see to what its motors should do. This is a form of imitation learning, bypassing the need for engineers to manually program every possible movement.
Will this make humanoid robots a reality sooner?
Yes, significantly. The lack of large-scale, real-world physical interaction data has been a major roadblock for developing generally dexterous robots. This data collection effort directly attacks that bottleneck. By providing the "training wheels" of human demonstration, it allows AI models to learn physical skills faster and more reliably than through trial-and-error alone or simulation. It is a critical enabling step for robots to move beyond controlled factory settings into dynamic human environments.








