A new benchmark called ItinBench reveals that large language models (LLMs) perform inconsistently when required to handle multiple cognitive dimensions simultaneously, such as verbal reasoning and spatial optimization within a single planning task. Published on arXiv, the study evaluates models including Llama 3.1 8B, Mistral Large, Gemini 1.5 Pro, and the GPT family, finding that none maintain high performance across all integrated sub-tasks.
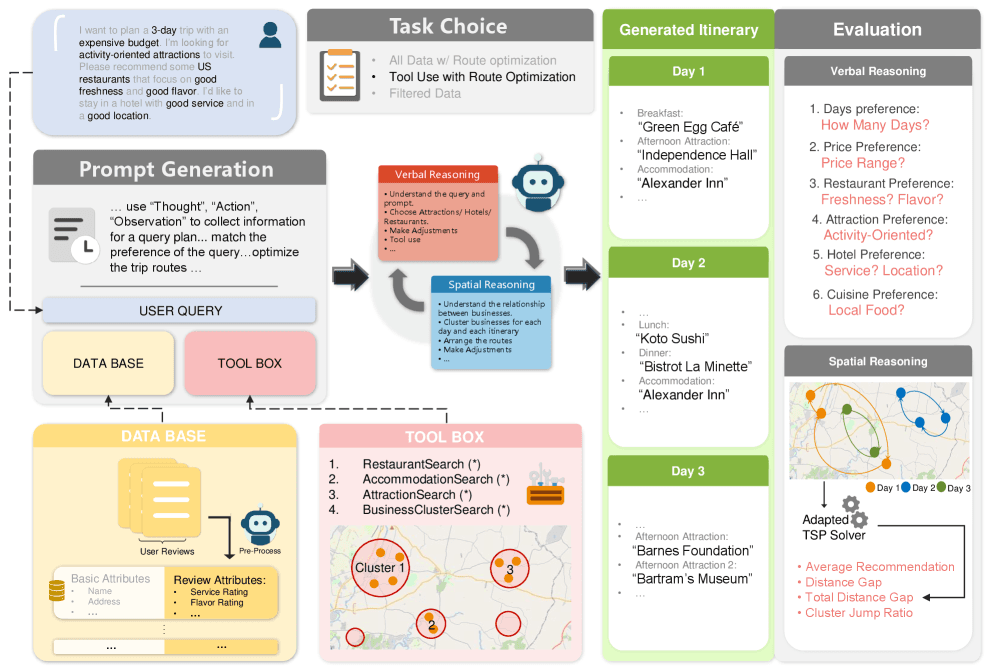
The research addresses a critical gap in LLM evaluation: most benchmarks test isolated skills like coding or math in controlled settings, while real-world agentic tasks—like planning a trip—require fluid integration of different reasoning types. ItinBench embeds a spatial route optimization problem within a traditional verbal travel itinerary planning framework, forcing models to juggle constraints, preferences, and geographic logic at once.
What the Researchers Built
The ItinBench dataset constructs multi-day trip planning scenarios for various cities. Each scenario presents the model with:
- Verbal Reasoning Tasks: User preferences (budget, dietary restrictions, activity types), temporal constraints, and narrative descriptions of points of interest.
- Spatial Reasoning Task: A Traveling Salesman Problem (TSP)-inspired requirement to optimize the daily route between selected points of interest to minimize travel time or distance.
The benchmark's key innovation is that these tasks are interdependent. A model cannot simply list attractions; it must create a feasible schedule where the sequence of visits follows a geographically sensible path. Performance is measured across both dimensions: adherence to verbal constraints and the optimality of the spatial route.
Key Results
The evaluation shows a significant drop in performance when models are evaluated on the integrated task versus individual components.

Note: Exact percentages are illustrative based on the paper's described trend; the paper states overall scores were below 50% and models showed "inconsistent performance."
The paper reports that no model achieved a score above 50% on the combined evaluation metric. Performance was highly inconsistent: a model might excel at verbal reasoning but fail completely at route optimization, or vice-versa. Furthermore, model scale did not reliably predict better integrated performance.
How It Works
ItinBench scenarios are structured as conversational prompts. The model is given a user's request (e.g., "Plan a 3-day food tour in Tokyo with a focus on sushi, but I'm allergic to shellfish") and access to a database of points of interest with attributes like location, category, price, and opening hours.
The evaluation uses two primary metrics:
- Constraint Satisfaction Score: Measures how well the final itinerary meets the user's stated verbal preferences and constraints.
- Route Optimality Score: Calculates the efficiency of the daily travel route compared to a known optimal solution (or a strong algorithmic baseline).
The final ItinBench Score is a weighted combination of these, penalizing models that sacrifice one dimension for the other. The dataset and evaluation code are publicly released to facilitate further research.
Why It Matters
This benchmark shifts the focus from component capability to integrated competency. It provides a more realistic stress test for models intended to function as autonomous agents. The results suggest that current LLMs, even the most advanced, are not robust integrative planners. They tend to be specialists in one type of reasoning and struggle to dynamically apply multiple cognitive skills in a coordinated way.

For developers building AI agents for real-world applications—from travel assistants to logistics planners—this indicates that simply using a powerful off-the-shelf LLM as the core reasoning engine is insufficient. Additional architectural components, like dedicated spatial reasoners or explicit constraint solvers, are likely necessary.
gentic.news Analysis
ItinBench is a timely and necessary correction to the prevailing trend in LLM evaluation. The field has become adept at creating ever-more-difficult puzzles in narrow domains (e.g., MATH, GPQA), but has paid less attention to how these capabilities compose. This paper demonstrates that composition is not free; high scores on MMLU or GSM8K do not guarantee an LLM can effectively weave that knowledge into a coherent plan requiring spatial reasoning.
Technically, the most revealing finding is the lack of correlation between model scale/verbal ability and integrated performance. This suggests that the ability to integrate cognitive dimensions may be a distinct capability, not an emergent property of scaling alone. It points to a potential need for novel training objectives that explicitly reward multi-dimensional planning, perhaps through reinforcement learning on simulated environments that require such integration.
From an industry perspective, this research validates the architectural choices of leading AI agent frameworks (like LangChain or LlamaIndex), which often use LLMs as orchestrators calling upon specialized tools (e.g., a calculator for math, a search API for facts, a maps API for routes). ItinBench shows why this tool-use paradigm is currently essential: the base LLM lacks the native, reliable ability to perform the spatial optimization itself. The benchmark could serve as a valuable testbed for evaluating these multi-component agentic systems versus monolithic LLM approaches.
Frequently Asked Questions
What is the ItinBench benchmark?
ItinBench is a new benchmark designed to evaluate large language models on integrated planning tasks. It combines traditional verbal reasoning (understanding user preferences and constraints for a trip) with a spatial reasoning task (optimizing the travel route between destinations). Its purpose is to test how well LLMs can handle multiple cognitive dimensions simultaneously, which is crucial for real-world AI agent applications.
Which AI models were tested on ItinBench?
The paper evaluated several leading large language models, including OpenAI's GPT family (likely GPT-4 and GPT-4o), Google's Gemini 1.5 Pro, Anthropic's Claude 3.5 Sonnet, Meta's Llama 3.1 (8B and 70B parameters), and Mistral AI's Mistral Large. The results showed that all models struggled, with none achieving a passing score above 50% on the combined evaluation metric.
Why do LLMs perform poorly on ItinBench?
LLMs perform poorly because the task requires the simultaneous and coordinated application of different types of reasoning—verbal/logistical and spatial/geometric. While LLMs are trained on vast amounts of text and may have encountered descriptions of routes or travel plans, they lack an inherent, robust model of spatial relationships and optimization. They are primarily next-token predictors excelling at pattern matching within language, not dedicated planning engines. When forced to do both, their performance on one or both dimensions degrades significantly.
How can developers build AI agents that pass benchmarks like ItinBench?
To build agents that succeed on integrated planning tasks, developers will likely need to move beyond using a single, monolithic LLM. The effective approach is a tool-augmented or neuro-symbolic architecture. In this setup, an LLM acts as a high-level orchestrator: it understands the user's verbal request, breaks down the problem, and then calls specialized tools or APIs—like a mapping service for route optimization, a calendar for scheduling, and a database for information lookup—to execute specific sub-tasks. The LLM's role is to integrate the results from these tools into a coherent final plan.