
What Happened
A new research paper titled "LLM-driven Multimodal Recommendation" introduces LMMRec (LLM-driven Motivation-aware Multimodal Recommendation), a novel framework that aims to move beyond traditional recommendation systems by explicitly modeling user and item motivations. The paper addresses a key limitation in current approaches: most methods treat motivation as latent variables derived solely from interaction data (clicks, purchases), neglecting rich textual information like reviews that can reveal the "why" behind user behavior.
Technical Details
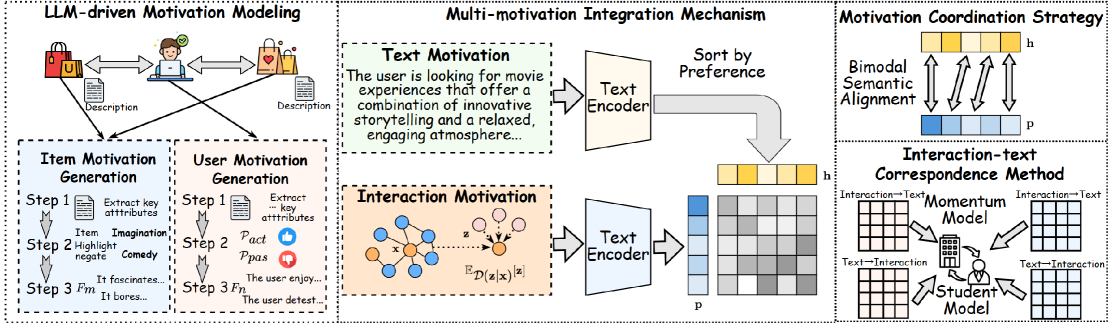
LMMRec is designed as a model-agnostic framework, meaning it can be integrated with various existing recommendation architectures. Its core innovation lies in using Large Language Models (LLMs) as semantic priors to understand and extract motivations.

Key Components:
Motivation Extraction via Chain-of-Thought (CoT) Prompting: Instead of treating text as simple features, LMMRec uses structured prompting with LLMs to extract fine-grained motivations from user reviews and item descriptions. For example, from a review like "Bought this dress for a summer wedding, loved the lightweight fabric," the system might extract user motivations ("need formal attire for specific event," "preference for breathable materials") and item attributes ("lightweight," "formal").
Dual-Encoder Architecture: The framework maintains two parallel representations:
- Textual Motivation Encoder: Processes the LLM-extracted motivations from text.
- Interaction Motivation Encoder: Models motivations inferred from historical user-item interactions.
The system then performs cross-modal alignment to create a unified representation that connects what users say (in text) with what they do (in interactions).
Noise Mitigation Strategies: Acknowledging that LLM-extracted text can be noisy or suffer from "semantic drift," the authors introduce two techniques:
- Motivation Coordination Strategy: Uses contrastive learning to ensure consistency between motivations extracted from different but related pieces of text (e.g., multiple reviews by the same user).
- Interaction-Text Correspondence Method: Employs a momentum update mechanism to align the evolving textual motivations with the more stable interaction-based signals, preventing the text representations from drifting too far from observed behavior.
Results:
Experiments on three datasets (presumably e-commerce or review platforms, though not specified in the abstract) showed that LMMRec achieved performance improvements of up to 4.98% over baseline methods. This demonstrates the tangible value of explicitly modeling motivation with LLMs.
Retail & Luxury Implications
While the paper is an academic proof-of-concept, its approach directly targets a fundamental challenge in high-value retail: understanding the nuanced intent behind customer behavior.
Potential Applications:
From "What" to "Why" in Personalization: Current luxury recommender systems excel at predicting "You viewed X, you might like Y." LMMRec's framework aims to understand "You viewed a cashmere sweater because you were looking for winter travel essentials" or "You bought this handbag as a self-reward after a promotion." This shift could power hyper-personalized campaigns, content, and product suggestions that resonate on an emotional level.
Leveraging High-Quality Textual Data: Luxury retail is rich in textual data—detailed product descriptions, client notes from personal shoppers, customer service interactions, and (where available) reviews. This framework provides a structured way to mine this data for intent signals that pure collaborative filtering misses.
Improving Cold-Start and Niche Recommendations: For new customers or new products with little interaction history, the LLM's ability to infer motivation from textual descriptions (of the user's profile or the product's attributes) could significantly boost recommendation quality from the first touchpoint.
The Gap Between Research and Production:
The 4.98% improvement is meaningful in research benchmarks but must be validated in real-world, complex retail environments. Key challenges for implementation include:
- Latency & Cost: LLM inference for every user and item is computationally expensive. Production systems would require optimized, smaller models or efficient caching strategies.
- Data Privacy & Granularity: The method assumes access to user-generated text like reviews. In luxury, where purchases are high-value and private, such data may be sparse. The system would need to adapt to other textual sources (e.g., anonymized wishlist notes, search queries).
- Integration Complexity: Being "model-agnostic" is a benefit, but integrating this dual-encoder framework with existing enterprise recommendation engines (like Salesforce Commerce Cloud, Adobe Sensei, or custom MLOps pipelines) requires significant ML engineering effort.
In essence, LMMRec is not an off-the-shelf solution, but a compelling architectural blueprint. It points the direction for the next generation of recommender systems where understanding motivation is as important as predicting affinity.








