
A new research paper from Microsoft demonstrates that reasoning models can be trained to dynamically compress their own chain-of-thought reasoning during generation, achieving 2-3x reductions in KV cache memory usage and 2x throughput improvements. The most significant finding, however, is that approximately 15 percentage points of the model's accuracy on reasoning tasks comes from information that persists in the KV cache after the explicit reasoning tokens have been summarized and erased—revealing an implicit memory channel that challenges conventional understanding of how transformers retain context.
Key Takeaways
- A new Microsoft paper shows language models can learn to compress their reasoning steps on-the-fly, slashing memory use 2-3x and doubling throughput.
- Crucially, 15 percentage points of accuracy come from 'leaked' information in KV cache after explicit reasoning is erased.
What the Researchers Built: Teachable Context Management
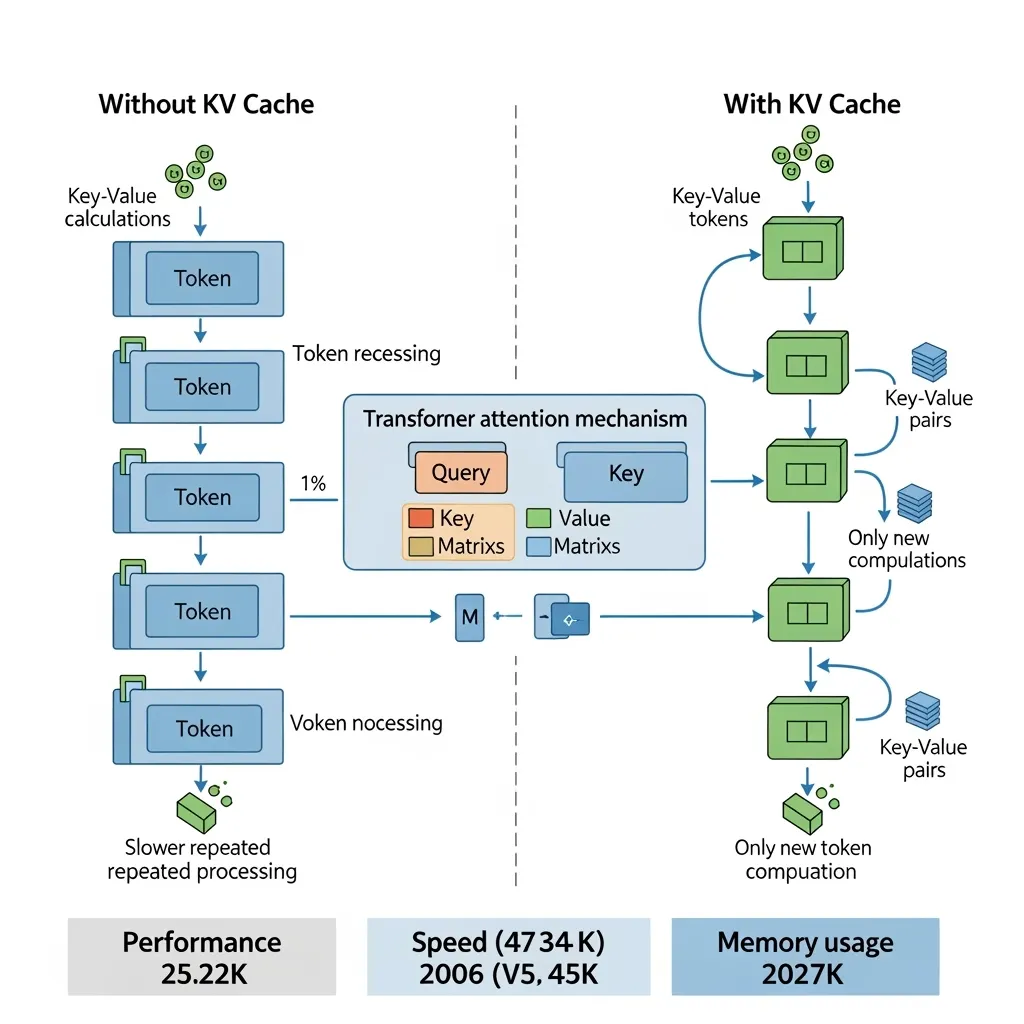
The core innovation is Compress-Thought, a training method that teaches autoregressive language models to manage their own working memory during multi-step reasoning. Instead of maintaining a full, verbose chain-of-thought throughout generation—which consumes growing KV cache memory—the model learns to periodically pause, summarize a block of reasoning into a concise statement, and then continue reasoning from that summary.
Researchers used LLaMA-2-7B as the base model and created a synthetic training dataset of approximately 30,000 examples where reasoning chains are interleaved with compression steps. During training, the model learns two skills simultaneously:
- Reasoning: Solving the actual problem (mathematical, logical, or commonsense)
- Context Management: Deciding when to compress and how to create faithful summaries that preserve necessary information for subsequent steps
Key Results: Efficiency Gains with a Memory Mystery
The quantitative improvements are substantial, but the qualitative discovery is what makes this paper noteworthy.
KV Cache Memory 2-3x reduction Compared to full chain-of-thought retention Throughput ~2x increase Tokens per second during generation Accuracy Retention ~15 pp from implicit memory 15 percentage points attributed to KV cache leakage Training Data 30K examples sufficient Synthetic examples for teachable skillOn GSM8K (grade school math) and other reasoning benchmarks, Compress-Thought maintains comparable accuracy to standard chain-of-thought prompting while using significantly less memory. However, when researchers performed ablation studies to isolate where the model's accuracy comes from, they found something unexpected.
How It Works: The Two-Channel Memory System
Technically, the compression works through a simple but effective training paradigm:
- During generation, the model produces reasoning tokens as usual until it predicts a special
<compress>token. - At compression points, the model generates a concise summary of the recent reasoning block (typically 1-3 sentences replacing dozens of tokens).
- The original detailed reasoning tokens are then masked/ignored for subsequent attention—they don't participate in future computation.
- Generation continues from the summary, treating it as the new context for the next reasoning step.
This should, in theory, create an information bottleneck: the model only "remembers" what's explicitly stated in the summary. But the KV cache—the mechanism that stores key-value pairs for all previous tokens in transformer attention—tells a different story.
Even after explicit tokens are erased, their representational influence persists in the KV cache. The researchers found that approximately 15 percentage points of accuracy on reasoning tasks can be attributed to this "leaked" information—the model is effectively reasoning with a dual-channel memory system:
- Explicit channel: The compressed summaries visible in the token sequence
- Implicit channel: Residual information from erased reasoning steps that persists in KV cache representations
This suggests current transformer architectures have more sophisticated memory mechanisms than previously understood, and that training can teach models to leverage both channels effectively.
Why It Matters: Rethinking Long-Horizon Agent Bottlenecks
The implications extend beyond immediate efficiency gains:
1. Long-context limitations may be addressable through training, not just architecture. If 30K examples can teach effective context management, then the bottleneck for long-horizon reasoning (planning, coding, research) might be more about creating the right training data than designing new architectures with larger context windows.
2. KV cache contains richer information than assumed. The finding that erased information "leaks forward" challenges the view that transformers only attend to explicit tokens. This has implications for interpretability, model editing, and safety—if models remember things they're not "supposed to," how do we audit or control that memory?
3. Practical deployment benefits are immediate. For API providers and on-device deployment, 2-3x memory reduction and 2x throughput directly translate to cost savings and latency improvements without sacrificing reasoning quality.
4. Synthetic training data suffices for complex skills. The fact that 30K synthetic examples teach this skill suggests other "meta-cognitive" abilities might be similarly teachable with modest datasets.
gentic.news Analysis
This work from Microsoft Research arrives at a pivotal moment in the evolution of reasoning models. Following our coverage of DeepSeek's MoE architecture breakthroughs last month, which focused on scaling efficiency, Microsoft's approach tackles the complementary problem of reasoning efficiency within fixed contexts. While much of the industry chases longer context windows (Anthropic's 200K-token Claude 3, Google's 1M-token Gemini 1.5), Microsoft demonstrates that teaching models to use existing context more intelligently may yield comparable practical benefits with fewer hardware demands.
The implicit memory finding connects to ongoing research into transformer memory mechanisms we've tracked since 2024's investigations into KV cache dynamics. This paper provides empirical evidence for what many researchers suspected: that transformer representations encode information in ways not fully captured by attention patterns alone. The 15 percentage point attribution to "leaked" KV cache information suggests future interpretability tools will need to audit not just token attention but representation evolution throughout generation.
From a competitive landscape perspective, Microsoft's focus on reasoning efficiency aligns with their broader strategy of making large models more deployable—a theme evident in their recent Phi-3 small model releases and partnerships with hardware vendors. If context management proves to be a broadly teachable skill (as these 30K examples suggest), we may see a shift from architecture-centric scaling to training-data-centric capability unlocking—a much more accessible frontier for organizations without exascale compute resources.
Frequently Asked Questions
How does Compress-Thought actually compress the reasoning?
The model learns to insert special compression tokens during generation. When it predicts a <compress> token, it generates a concise summary of the recent reasoning steps (typically 1-3 sentences), then continues reasoning from that summary. The original detailed reasoning tokens are effectively "erased" from the explicit token sequence but leave traces in the KV cache representations that subsequent attention layers can still utilize.
What's the difference between this and standard chain-of-thought prompting?
Standard chain-of-thought maintains all reasoning tokens throughout generation, consuming growing KV cache memory. Compress-Thought periodically summarizes and replaces verbose reasoning with concise statements, dramatically reducing memory usage. Surprisingly, accuracy remains high because erased information persists implicitly in the KV cache—creating a dual-channel memory system the model learns to leverage.
Could this technique work with larger models like GPT-4 or Claude?
The research used LLaMA-2-7B, but the principle should generalize. The key requirement is training the model to recognize when to compress and how to create faithful summaries. For proprietary models without training access, similar effects might be achievable through carefully designed prompting, though likely less efficient than trained-in behavior.
What are the practical applications of this research?
Immediate applications include: reducing inference costs for reasoning-heavy workloads (coding assistants, research agents), enabling longer reasoning chains within fixed memory budgets, and improving throughput for real-time reasoning applications. Longer-term, if context management is teachable with modest data, it could democratize efficient reasoning capabilities for organizations without massive training resources.








