Epoch AI and METR launched MirrorCode, a benchmark costing $2,600 per run. The benchmark tasks AI with rebuilding 25 real-world programs without human help.
Key facts
- MirrorCode tasks cost up to $2,600 per run.
- Claude Opus 4.7 leads with 56% solve rate.
- Hyperscaler capex to exceed cash flows by end of 2026.
- Epoch scraped 1,604 Chinese AI job postings.
- Hardest MirrorCode tasks take humans weeks to months.
Epoch AI, in collaboration with METR, released MirrorCode, a long-horizon coding benchmark designed to test the upper limits of autonomous AI software engineering. According to the Epoch AI blog post, MirrorCode tasks AI models with rebuilding 25 real-world programs spanning bioinformatics, Unix utilities, cryptography, and interpreters, with no access to source code and no human in the loop. The hardest programs are estimated to take a human engineer weeks to months to complete without AI assistance.
The $2,600 Inference Run
MirrorCode breaks from existing coding benchmarks by providing a massive inference budget. Many current SWE benchmarks cap inference at $1-$10 per task with runs lasting minutes or hours. By contrast, one MirrorCode task cost $2,600 for a single run, with the AI operating for 19 days without intervention. This shift aims to measure whether models can sustain coherent reasoning over extended periods, a key requirement for real-world software engineering.
Claude Opus 4.7 currently leads with a 56% solve rate, indicating significant room for improvement. The benchmark is openly available for researchers to test their models.
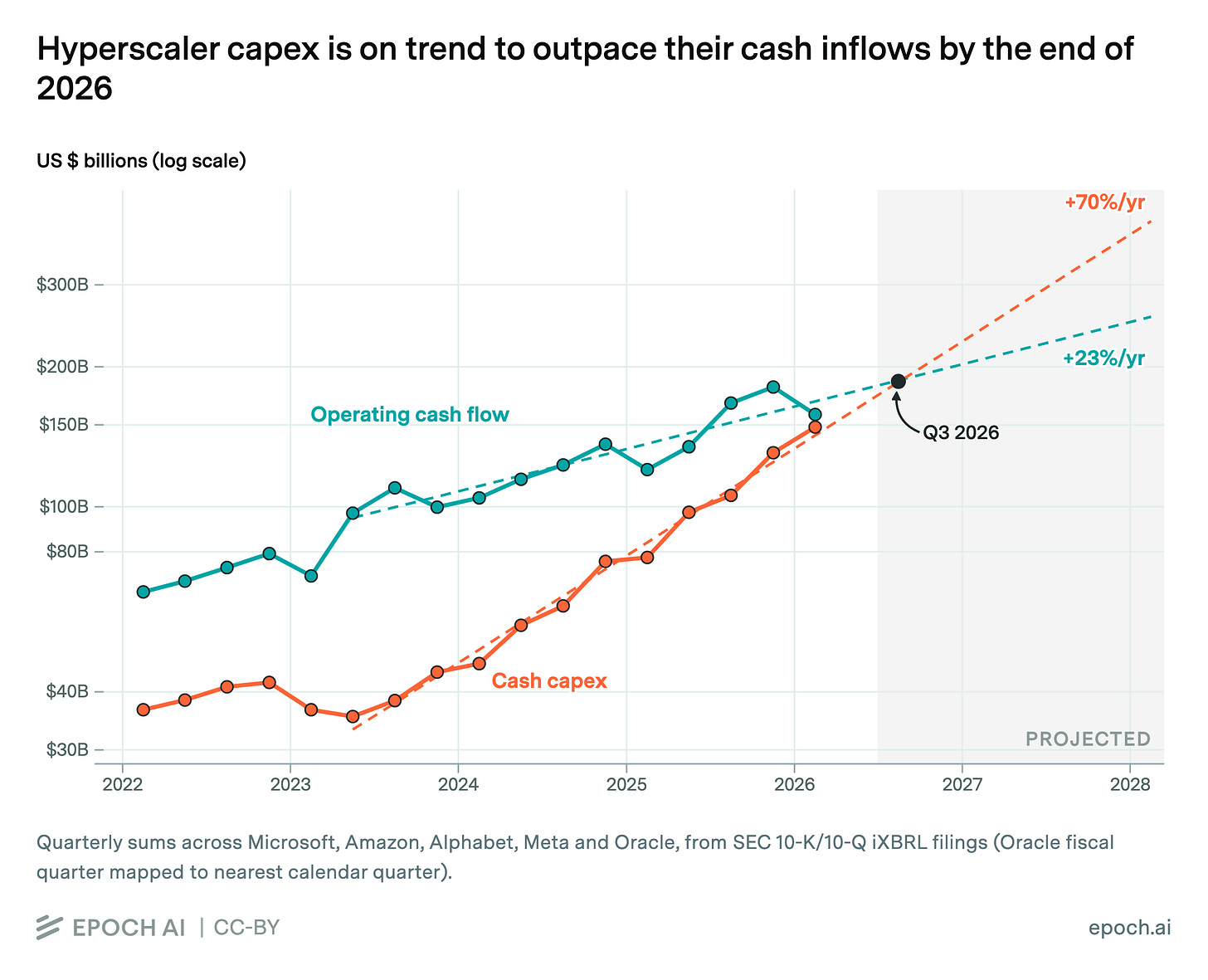
Hyperscaler Capex Squeeze
Separately, Epoch senior researcher Isabel Juniewicz found that the world's largest hyperscalers—Microsoft, Amazon, Alphabet, Meta, and Oracle—are increasing cash capital expenditures faster than their operating cash inflows. Most have already turned to external financing to fund AI infrastructure investments, or are considering doing so. This trend suggests that AI infrastructure spending is becoming a bet on future returns rather than a reflection of current profitability.
Chinese Lab Strategies
Epoch researchers scraped over 1,600 job postings from six major Chinese AI firms. They found that, like US labs, Chinese companies have distinct strategic personalities—some prioritize research, others application development. This granular view contrasts with the common narrative of a monolithic Chinese AI push.
Toward an AI R&D Taxonomy
Epoch also proposed a taxonomy for tracking which parts of AI research remain unautomated, aiming to quantify how close AI is to automating its own R&D. This framework could inform policy decisions about research investment and labor displacement.
Key Takeaways
- Epoch AI and METR launched MirrorCode, a $2,600-per-run coding benchmark.
- Claude Opus 4.7 leads with 56% solve rate.
What to watch
Watch for follow-up benchmarks that extend MirrorCode's duration beyond 19 days, and for hyperscaler Q3 2026 earnings reports that will reveal whether external financing for AI infrastructure has increased. Also track whether Claude Opus 4.7's 56% solve rate improves with larger inference budgets.
Source: epochai.substack.com