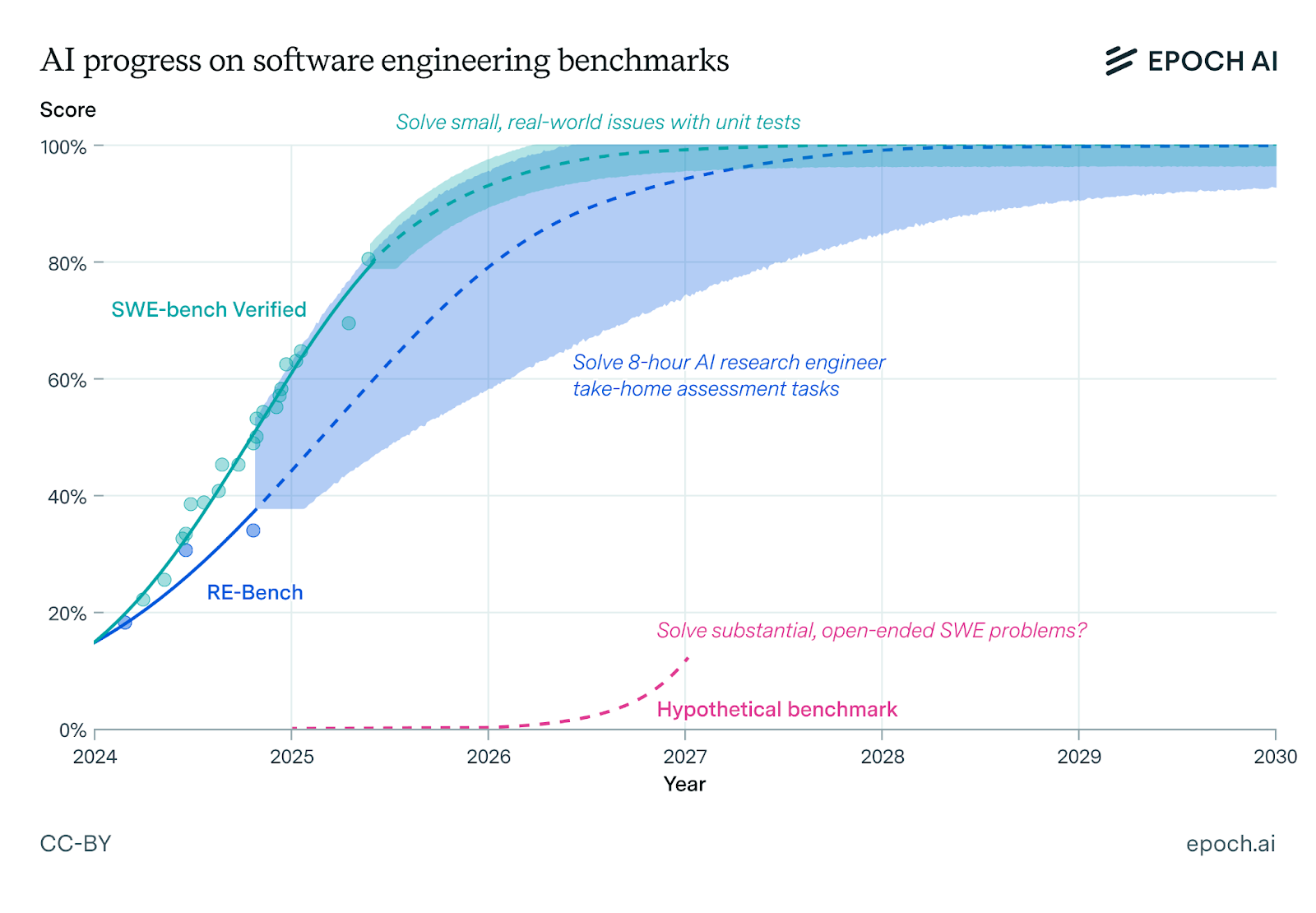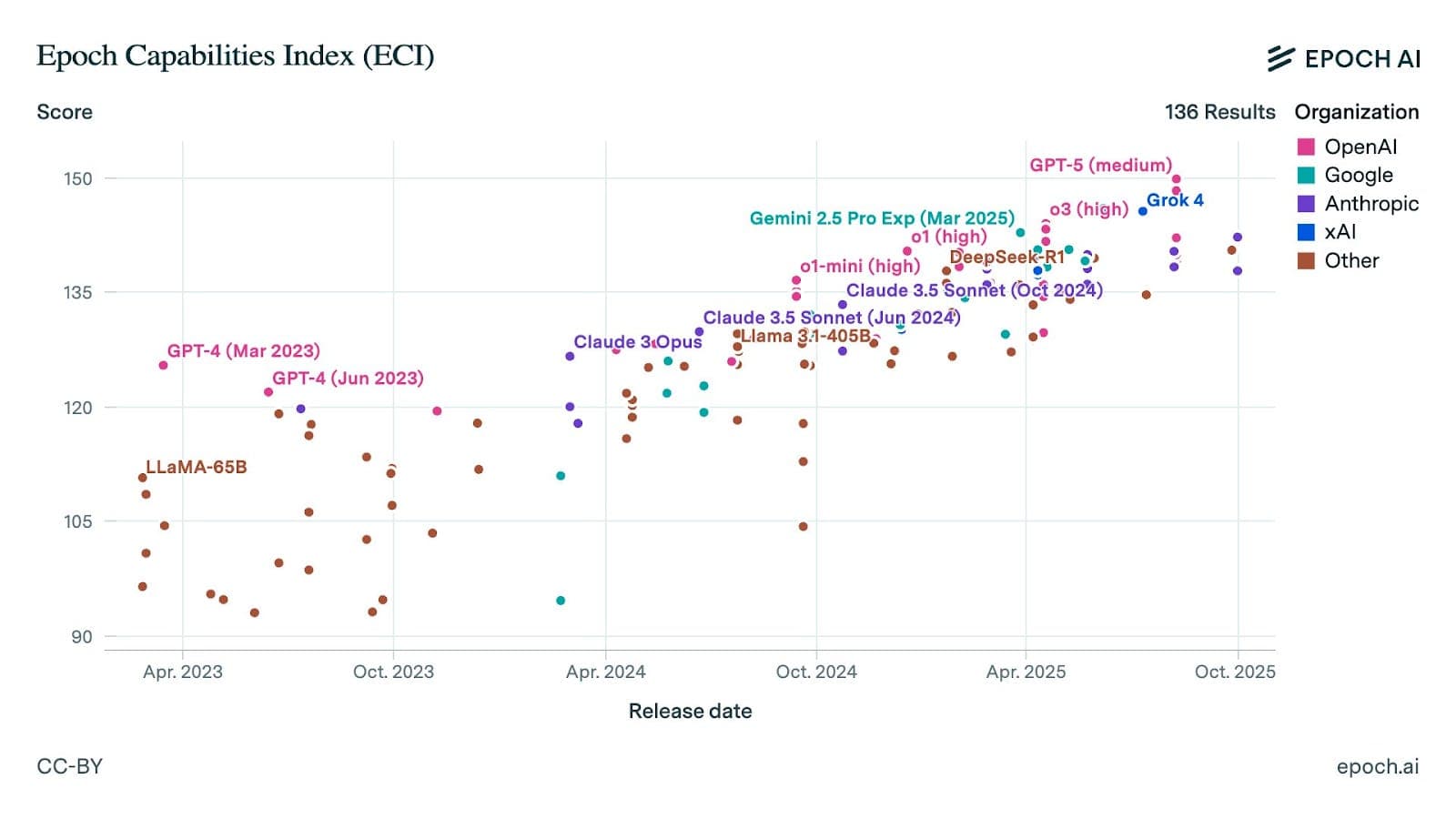
Epoch AI released MirrorCode, a benchmark of 25 long-horizon software tasks. The benchmark tests whether AI models can reimplement entire programs from scratch without source code access.
Key facts
- MirrorCode includes 25 target programs spanning Unix utilities.
- Models must match original stdout and stderr exactly.
- Released by Epoch AI in late June 2026.
- No source code access allowed during reimplementation.
- Joins OSWorld 2.0, SciCode, and CursorBench in Epoch AI's suite.
Epoch AI released MirrorCode, a benchmark of 25 long-horizon software tasks per the MirrorCode announcement. The benchmark tests whether AI models can reimplement entire programs from scratch without source code access. Models must match the original program’s stdout and stderr exactly on end-to-end tests. The 25 target programs span Unix utilities and other computing domains.
Why MirrorCode matters more than SWE-Bench
Existing software engineering benchmarks like SWE-Bench and CursorBench focus on editing existing codebases — fixing bugs, adding features, or refactoring. MirrorCode shifts the goalpost to zero-shot reimplementation. This tests a fundamentally harder capability: understanding a program’s behavior from its specification and producing equivalent code without any reference implementation.
The benchmark’s strict output matching requirement eliminates partial credit. Either the model produces bit-identical output across all test cases, or it fails. This binary scoring mirrors the real-world constraint of production software: a program that works 90% of the time is often useless.
Relationship to Epoch AI’s benchmark suite
MirrorCode joins Epoch AI’s growing family of coding benchmarks released in late June 2026, including OSWorld 2.0 (1,500 desktop tasks), SciCode (scientific research coding), and CursorBench (500+ code editing tasks). Together, these benchmarks segment AI coding ability by task type: editing, research, desktop automation, and now full-program reimplementation.
The 25-program size is small compared to SWE-Bench’s thousands of tasks. However, the difficulty per task is higher — each requires understanding a complete program specification, not just a localized change.
What the benchmark doesn’t measure
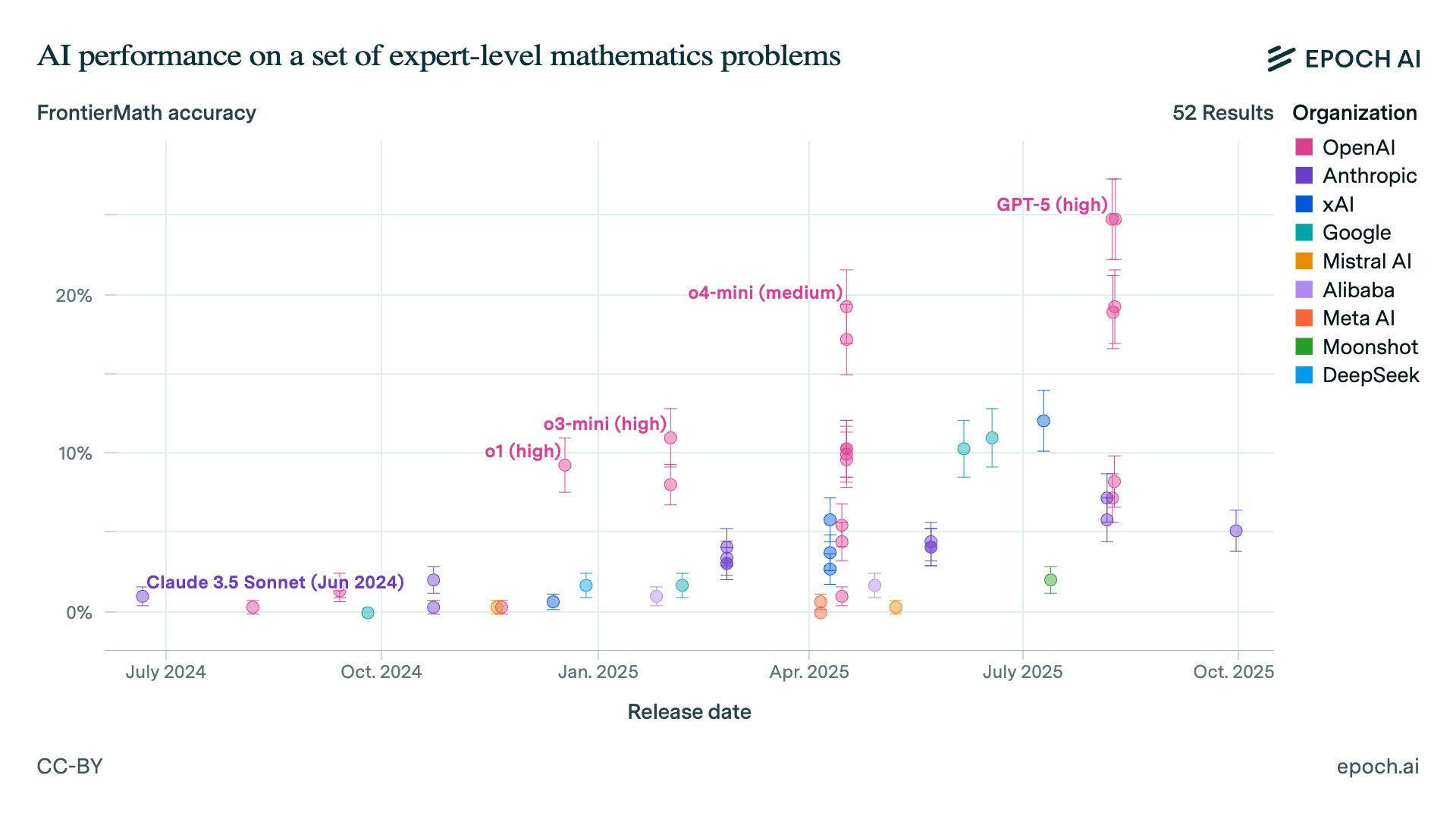
MirrorCode does not test for code quality, efficiency, or maintainability. A model that produces a correct but O(n²) solution passes the same as one producing an O(n) solution. It also does not test for debugging, documentation generation, or collaborative coding — all real-world software engineering activities.
The benchmark’s 25 programs are fixed, creating potential for overfitting if models train on similar Unix utilities. Epoch AI did not disclose whether the target programs are drawn from public repositories that may appear in training data.
What to watch
Watch for the first model to achieve >50% pass rate on MirrorCode, and whether performance correlates with context window size — full-program reimplementation may require tracking thousands of lines of logic. Also track whether Epoch AI expands the task set beyond 25 programs to reduce overfitting risk.
Source: news.google.com