Key Takeaways
- Researchers propose MVCrec, a framework that applies multi-view contrastive learning between sequential (ID-based) and graph-based views of user interaction data to improve recommendation accuracy.
- It outperforms 11 leading models, showing significant gains in key metrics.
What Happened
A new research paper, "ID and Graph View Contrastive Learning with Multi-View Attention Fusion for Sequential Recommendation," was posted to the arXiv preprint server. The work introduces a novel framework called Multi-View Contrastive learning for sequential recommendation (MVCrec). Its core innovation is the joint optimization of two complementary perspectives on user interaction data: the sequential (ID-based) view and the graph-based view.
Sequential recommendation is a cornerstone of modern e-commerce, aiming to predict a user's next likely interaction (e.g., purchase, click) based on their historical sequence of actions. While recent models have used either contrastive learning (to create robust representations) or graph neural networks (to model relational structure), MVCrec is one of the first to deeply integrate both through a multi-view contrastive approach, specifically designed for settings with only basic interaction data.
Technical Details
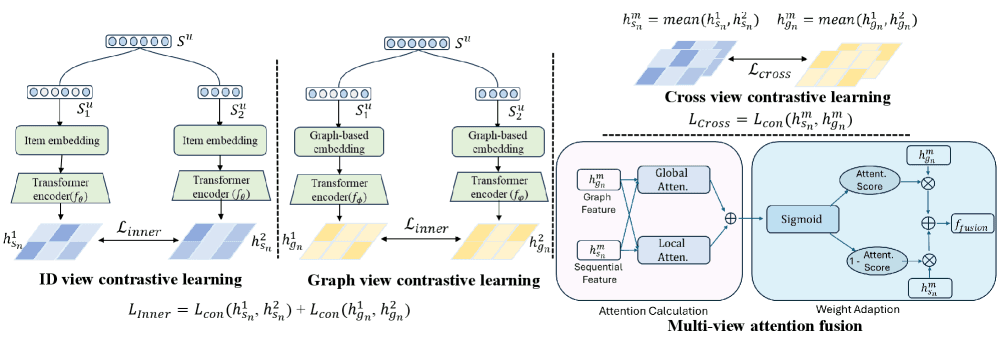
The MVCrec framework is built on a key insight: the ID-based sequential view and the graph-based relational view offer different, complementary signals about user preferences. The ID view treats each item as a unique token, learning patterns in the sequence order. The graph view constructs a graph where items are nodes, and connections are based on co-occurrence in sequences, capturing broader relational patterns (e.g., "users who viewed this also viewed that").
The model employs three contrastive learning objectives:
- Intra-sequential contrastive loss: Augments the raw interaction sequence (e.g., via masking or cropping) to learn robust representations within the sequential view.
- Intra-graph contrastive loss: Applies graph augmentation techniques (e.g., edge dropping) to learn invariant representations within the graph structure.
- Cross-view contrastive loss: This is the crucial innovation. It aligns the representations of the same user or item from the sequential and graph views, ensuring they are consistent and mutually informative.
Finally, a multi-view attention fusion module dynamically combines the learned representations from both views. It uses a combination of global attention (to capture overall preference) and local attention (to focus on recent interactions) to generate the final prediction score for a user-item pair.
The authors validated MVCrec on five public benchmark datasets (Amazon-Beauty, Amazon-Sports, Yelp, MovieLens-1M, and Gowalla). It was tested against 11 state-of-the-art baselines, including models like SASRec, BERT4Rec, S3-Rec, and LightGCN. The results are compelling: MVCrec achieved improvements of up to 14.44% in NDCG@10 and 9.22% in HitRatio@10 over the strongest baseline. The code and datasets have been made publicly available on GitHub.
Retail & Luxury Implications
This research is directly applicable to the core operational challenge of personalization in retail and luxury. The performance gains demonstrated by MVCrec translate to a more accurate, next-best-offer engine that can operate using a brand's existing first-party interaction data—clicks, views, purchases—without requiring rich, hard-to-obtain auxiliary data like detailed product attributes or user demographics.

For a luxury brand, the implications are significant:
- Post-Session Engagement: Predicting the next item a high-intent browser might desire after viewing a handbag, based on the sequential patterns of similar clients and the broader "style graph" of the collection.
- Email & Push Notification Curation: Dynamically generating personalized product sequences for re-engagement campaigns that feel coherent and stylistically relevant, not just based on simple co-view statistics.
- Enhancing In-Session Discovery: On a product detail page, the "Complete the Look" or "You May Also Like" sections could be powered by this fused ID-graph logic, suggesting items that are both sequentially probable and graph-theoretically complementary.
- Cold-Start Mitigation: The graph component can help position a new season's item within the existing relational web of products, providing a better starting point for recommendations even with zero purchase history.
The framework's strength in "settings where only interaction data is available" is particularly relevant for luxury houses prioritizing data privacy and working with constrained, but high-quality, purchase histories.
Implementation Approach
Adopting MVCrec is a non-trivial engineering undertaking, suitable for brands with mature data science and MLOps teams. The prerequisite is a robust data pipeline that can transform raw event logs (user ID, item ID, timestamp, event type) into two parallel data structures: chronologically ordered user sequences and a global item-item interaction graph.

The model itself, as described, requires expertise in PyTorch or TensorFlow, contrastive learning, and graph neural networks (GNNs). The training process involves the simultaneous optimization of the three contrastive losses and the final recommendation loss, which demands careful hyperparameter tuning and significant computational resources for training on large-scale interaction graphs. However, the inference step—generating recommendations for a user—would be comparable in latency to other deep learning-based recommenders once the model is deployed and the user/item embeddings are pre-computed.
For most luxury brands, the path to value would not be a from-scratch implementation of the academic paper. Instead, the strategic approach is to pressure-test existing recommendation vendors on whether their architectures incorporate similar multi-view or contrastive learning principles. Internally, the research validates a direction: investment in teams and platforms capable of building and maintaining graph-based representations alongside sequential models is a credible path to superior personalization.