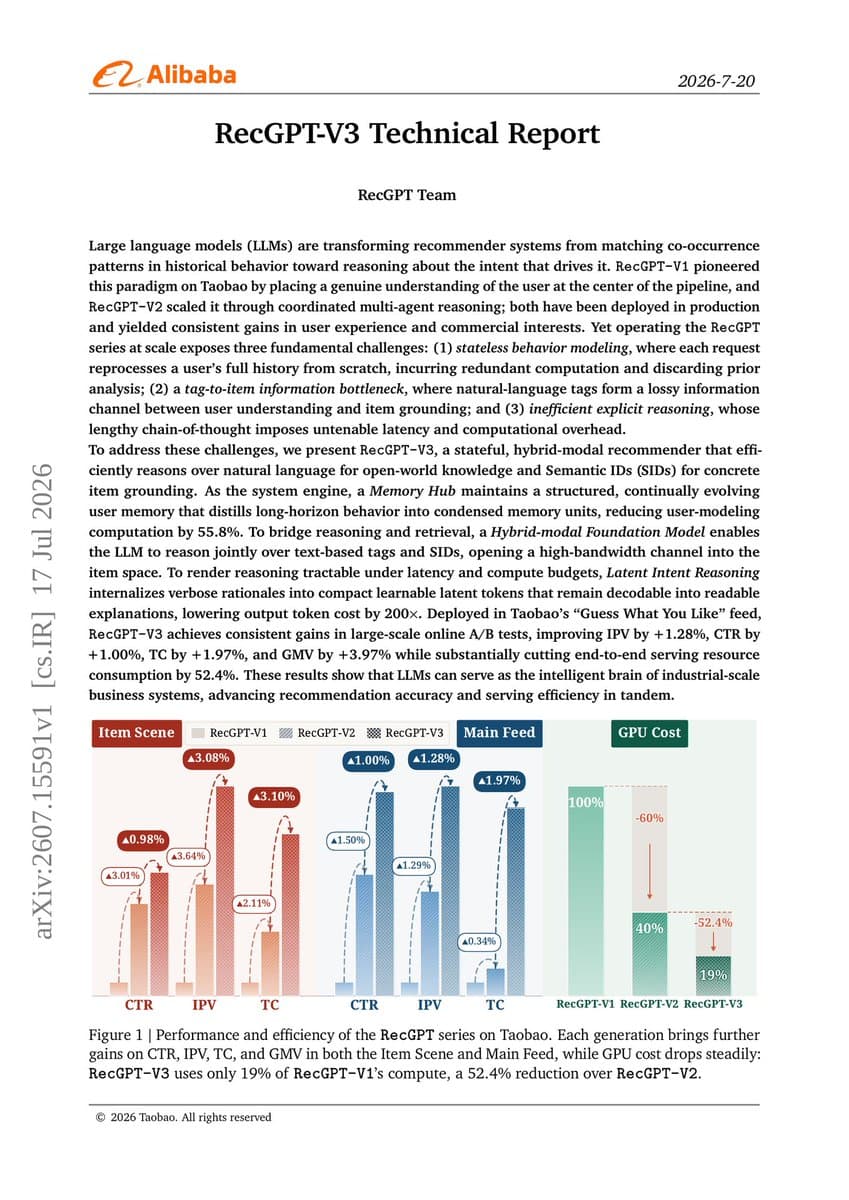
Key Takeaways
- Researchers introduced a trace-level framework to compare human and GUI-agent behavior in a production search system.
- While the agent matched human success rates and query alignment, its navigation was systematically more search-centric and less exploratory.
- This reveals a critical gap in using agents as user proxies.
What Happened
A new research paper, "Same Outcomes, Different Journeys: A Trace-Level Framework for Comparing Human and GUI-Agent Behavior in Production Search Systems," presents a critical methodology for evaluating AI agents that automate or simulate user interactions. The core finding is that while a state-of-the-art LLM-driven GUI agent can achieve task success rates comparable to humans and generate broadly similar search queries, its underlying navigation behavior is fundamentally different.
The study was conducted in a controlled environment using a production audio-streaming search application. Thirty-nine human participants and a GUI agent performed ten multi-hop search tasks. The researchers developed a framework to compare behavior across three dimensions:
- Task Outcome & Effort: Completion success and steps taken.
- Query Formulation: The text and intent of searches.
- Navigation Across Interface States: The sequence and branching of clicks and page views.
The agent performed well on the first two dimensions. However, on the third, a stark divergence emerged: human participants exhibited content-centric, exploratory behavior—clicking on results, browsing, and branching their paths. The agent, in contrast, was search-centric and low-branching, relying more heavily on successive text searches to narrow down results.
Technical Details
The framework moves beyond simplistic success/failure metrics (like click-through rate or final answer correctness) to perform a granular, trace-level analysis. By instrumenting the application to log every state change, query, and click, the researchers could reconstruct and compare the complete interaction "journey" of humans and agents.
This diagnostic approach reveals that outcome alignment does not imply behavioral alignment. An agent can complete a task successfully but do so in a way that never tests certain UI flows, misses corner cases, or fails to simulate real user friction points. This has profound implications for using such agents for system evaluation, A/B testing, or user simulation.
Retail & Luxury Implications
For retail and luxury brands investing in AI for customer experience and operational testing, this research is a vital cautionary note.

1. Testing E-commerce Flows & Search: Many brands are exploring or already using AI agents to automate QA testing of their websites and apps, or to simulate customer journeys for optimizing conversion funnels. This study suggests that if these agents navigate in a rigid, search-heavy manner unlike real shoppers—who browse visually, filter, compare, and get inspired—the test results could be misleading. An agent might find a product via a perfect text search, while a human customer might have abandoned the site because a visual gallery was confusing. The agent's success would mask a critical UI flaw.
2. Evaluating In-House AI Tools: If a luxury brand develops an internal "style assistant" AI for store associates or a clienteling tool, evaluating it solely on whether it retrieves the correct product SKU is insufficient. This framework argues for analyzing how the associate uses the tool: Do they follow natural, conversational paths, or do they have to contort their workflow to fit the AI's logic? Behavioral misalignment here leads to poor adoption and wasted investment.
3. Building Representative User Simulators: To accurately forecast the impact of a new website feature on load times, engagement, or sales, simulations must be behaviorally realistic. Deploying agents that don't browse like humans will generate unreliable load and business metrics. This research provides a methodology to audit and improve those simulators.
The gap identified is not a deal-breaker but a call for more sophisticated evaluation. Before relying on GUI agents for critical business decisions, retail AI teams must implement similar trace-level diagnostics to ensure their digital proxies truly mimic their clientele's journey.