
Artificial Analysis released AgentPerf, the first benchmark purpose-built for agentic AI workloads. NVIDIA Blackwell Ultra NVL72 leads the initial round, running 20x more agents per megawatt than the Hopper H200 system.
Key facts
- AgentPerf is the first benchmark for agentic AI workloads.
- Blackwell Ultra NVL72 leads with 20x agents/MW vs Hopper.
- Benchmark uses DeepSeek V4 Pro MoE model.
- GB300 NVL72 connects 72 GPUs in a rack-scale system.
- CUDA kernels overlap communication and compute for efficiency.
Agentic AI Is Not Chat: Why AgentPerf Matters
AgentPerf from Artificial Analysis, the industry’s first agentic AI benchmark, gives developers, enterprises and infrastructure providers a clear way to compare systems for agentic AI According to the NVIDIA blog.
The distinction from traditional inference benchmarks is critical. A single chat completion is a sprint: one LLM call, one response. An agent functions more like a relay: It breaks a goal into many steps and keeps going until the task is done. That results in dozens to hundreds of LLM calls chained together, each passing growing context to the next, with tool calls like code compile and execution, database search and web browsing at every handoff. The complexity isn’t additive; it’s multiplicative.
Existing AI inference benchmarks measure one LLM call: how fast an LLM responds to a single request and how many simultaneous requests a system can handle. They weren’t designed for agentic workloads, where chained LLM calls, tool call delays and growing context stress accelerated computing systems in fundamentally different ways.
Blackwell Ultra NVL72: 20x Agents per Megawatt
In the first round of published results, the NVIDIA Blackwell Ultra NVL72 platform delivers leading performance across the agentic AI workloads tested, running 20x more agents per megawatt than NVIDIA Hopper. The benchmark uses DeepSeek V4 Pro, a large mixture-of-experts (MoE) model representing the class of frontier models powering today’s most capable agents.

On this workload, NVIDIA GB300 NVL72 delivers the highest performance in the benchmark, running up to 20x more agents per megawatt than the NVIDIA HGX H200 system. The performance advantage comes from extreme codesign across the full stack. GB300 NVL72 connects 72 GPUs into a single rack-scale system, enabling large MoE models like DeepSeek V4 Pro to distribute model execution efficiently at scale.
CUDA kernels accelerate this further by overlapping communication and compute, so the cost of coordinating across experts is absorbed rather than added to latency. NVIDIA TensorRT LLM sustains efficiency as concurrent agent sessions scale. For example, it separates the processing of inputs from the generation of outputs so each can be optimized independently.
Benchmark Built on Real Coding Agent Trajectories
AgentPerf is built based on real coding agent trajectories: an agent receives a task, reads files, writes and edits code, executes commands and iterates based on the results. This methodology grounds the benchmark in production-like conditions, unlike synthetic or single-turn evaluations.
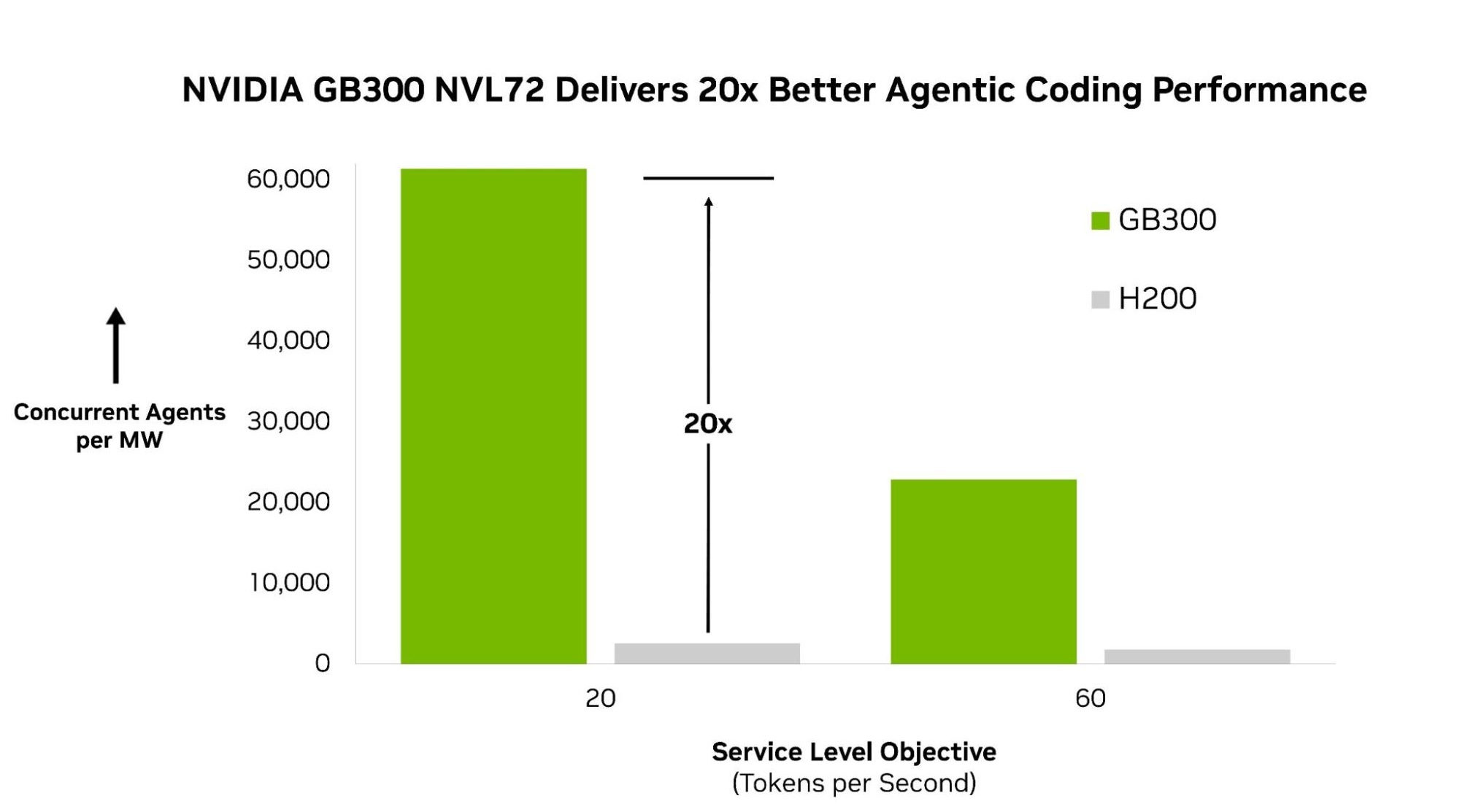
For companies building and deploying agents at scale, it’s important to understand how responsive agents are, how many can be deployed simultaneously and how much useful work AI infrastructure can deliver for every dollar and watt invested. The 20x agents-per-megawatt metric directly addresses the total cost of ownership question that enterprises face when scaling agent deployments.
Infrastructure Benchmarking Catches Up to the Agent Shift
Until now, the industry benchmarked AI infrastructure on metrics designed for chatbot inference — tokens per second, time-to-first-token, concurrent sessions. Those numbers told operators how fast a single response arrived, but not how many multi-step tasks a system could complete per unit of energy. AgentPerf flips this: it measures throughput of completed agentic tasks, not raw token generation. The 20x gap between Blackwell Ultra and Hopper suggests that architectural choices — particularly the rack-scale GPU interconnect and communication-compute overlap — matter far more for agent workloads than for chat. The implication for infrastructure buyers: optimizing for chat benchmarks may leave agent performance on the table.
NVIDIA's positioning here is strategic. As OpenAI, Google, and Anthropic race to deploy autonomous coding agents, the infrastructure layer becomes the bottleneck. Blackwell Ultra's lead on agent-specific metrics gives NVIDIA a narrative advantage over competitors like AMD and Intel, who have yet to demonstrate comparable agent-optimized performance. The 20x efficiency gap also pressures hyperscalers building their own custom silicon (Google TPU, AWS Trainium) to validate against agent workloads, not just training and inference.
What to Watch
Watch for the next AgentPerf round to include AMD MI400 and Intel Falcon Shores results, which will reveal whether Blackwell's agent advantage is architectural or merely first-mover. Also track whether Artificial Analysis expands the benchmark to include multi-agent orchestration scenarios, which would stress interconnect bandwidth even harder.
Source: blogs.nvidia.com








