The race to build autonomous AI agents capable of operating in terminal environments—executing commands, debugging code, and managing systems—has been throttled by a fundamental problem: data. While proprietary models like Anthropic's Claude Code have demonstrated impressive proficiency, their training strategies and data mixtures have remained closely guarded secrets. This opacity has forced researchers and developers into a costly and inefficient cycle of trial and error. NVIDIA has now launched a one-two punch aimed at dismantling this barrier: the Nemotron-Terminal data engineering pipeline and the Nemotron 3 Super, a colossal 120-billion-parameter open-source model.
The Data Drought in Agentic AI
Autonomous terminal agents represent a frontier in AI application, promising to automate complex software development and IT operations tasks. However, their development has hit a "massive bottleneck." High-quality, diverse, and scalable training data for terminal interactions is scarce. Proprietary leaders have not shared their datasets or methodologies, creating a significant gap between closed, high-performing systems and the open-source community. This lack of transparency and accessible resources has stifled innovation, confining advanced agentic capabilities to a few well-resourced organizations.
Introducing Nemotron-Terminal: A Systematic Pipeline
NVIDIA's response is Nemotron-Terminal, a systematic data engineering pipeline explicitly designed for scaling Large Language Model (LLM) terminal agents. While specific architectural details from the source are limited, the pipeline's stated purpose is to generate, curate, and structure the high-quality interaction data needed to train robust agents. By providing a reproducible and scalable framework for data creation, Nemotron-Terminal directly attacks the core scarcity issue. It offers the research community a methodology to build their own training corpora, reducing dependency on undisclosed proprietary data and lowering the entry barrier for developing competitive terminal agents.

The Engine: Nemotron 3 Super
Launching in tandem is the powerhouse meant to run these agents: Nemotron 3 Super. This is not just another large model; it's a purpose-built engine for agentic AI. As reported, it's a 120-billion-parameter model utilizing a novel hybrid Mamba-Attention Mixture of Experts (MoE) architecture. Critically, only 12 billion parameters are active during inference, a design that prioritizes staggering efficiency. NVIDIA claims this design delivers 5x higher throughput for agentic workloads compared to previous architectures.

The model is described as "open-source" and is engineered for "complex multi-agent applications" and "autonomous agents." It is positioned between the lighter 30-billion-parameter Nemotron 3 and larger frontier models, aiming to offer a unique blend of scale, efficiency, and accessibility. Its release signifies a major commitment to open-sourcing foundational technology for the next wave of AI applications.
Strategic Implications and Partnerships
The launch is part of a broader strategic push by NVIDIA into the agentic AI stack. Recent events show NVIDIA deepening its ecosystem investments:
- A multi-year, gigawatt-scale strategic partnership with Thinking Machines Lab, alongside a significant undisclosed investment.
- Direct integration with AI-native companies; for instance, Perplexity is offering its users access to Nemotron 3 Super.
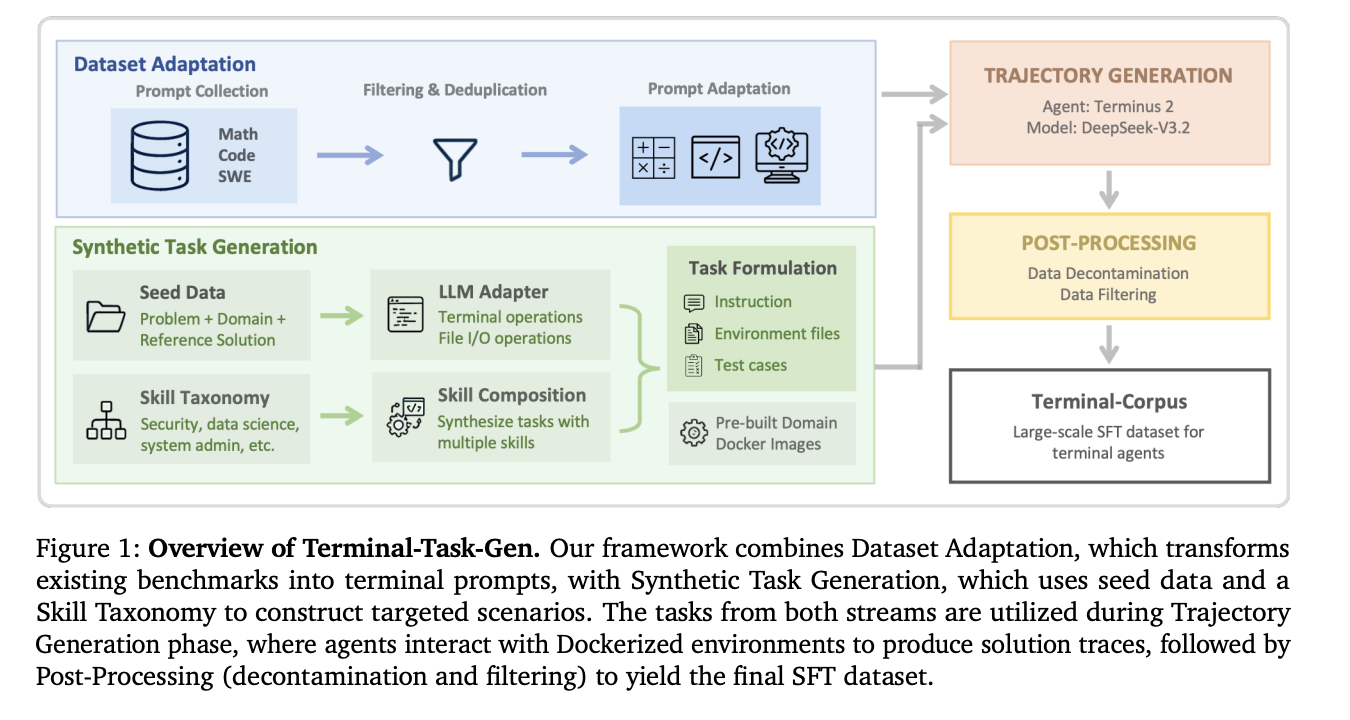
These moves illustrate a strategy that extends beyond selling hardware (GPUs) or foundational models. NVIDIA is actively shaping the entire agentic AI landscape—from the data pipeline (Nemotron-Terminal) and the reasoning engine (Nemotron 3 Super) to strategic cloud partnerships and direct consumer-facing integrations.
Why This Matters: Democratization and Acceleration
The combined release of Nemotron-Terminal and Nemotron 3 Super represents a pivotal moment for several reasons:
- Democratizes Development: By open-sourcing a state-of-the-art model and providing a blueprint for data creation, NVIDIA is empowering a much wider pool of developers and researchers to build sophisticated agents. This could accelerate innovation and lead to a more diverse ecosystem of AI tools.
- Solves the Data Chokepoint: Nemotron-Terminal directly addresses the most cited obstacle in the field. A systematic approach to data engineering could become as critical as model architecture for advancing agent capabilities.
- Efficiency-First Design: Nemotron 3 Super's hybrid architecture (Mamba-Attention MoE) highlights an industry shift away from pure transformer models toward more efficient designs. The 5x throughput claim, if borne out, makes deploying complex, multi-step agents significantly more viable and cost-effective.
- Full-Stack Strategy: NVIDIA is no longer just the "picks and shovels" provider. With these releases, it is providing the picks (data pipelines), shovels (efficient models), and blueprints (open-source frameworks) for the AI agent gold rush, seeking to define the standards for this emerging domain.
The Road Ahead
The success of this initiative will be measured by the community's adoption and the quality of the agents built using these tools. Will Nemotron-Terminal-generated data prove as effective as the proprietary datasets used by frontier models? Can the open-source community leverage Nemotron 3 Super to create agents that rival or surpass closed offerings?
NVIDIA's dual release throws down a gauntlet. It challenges the industry to embrace greater transparency and collaboration in agent development. If successful, it could break the current oligopoly on advanced agentic AI, fueling a new wave of automation and intelligent systems across software development, DevOps, and beyond. The bottleneck may finally be starting to clear.
Source: Based on reporting from MarkTechPost and the NVIDIA blog.