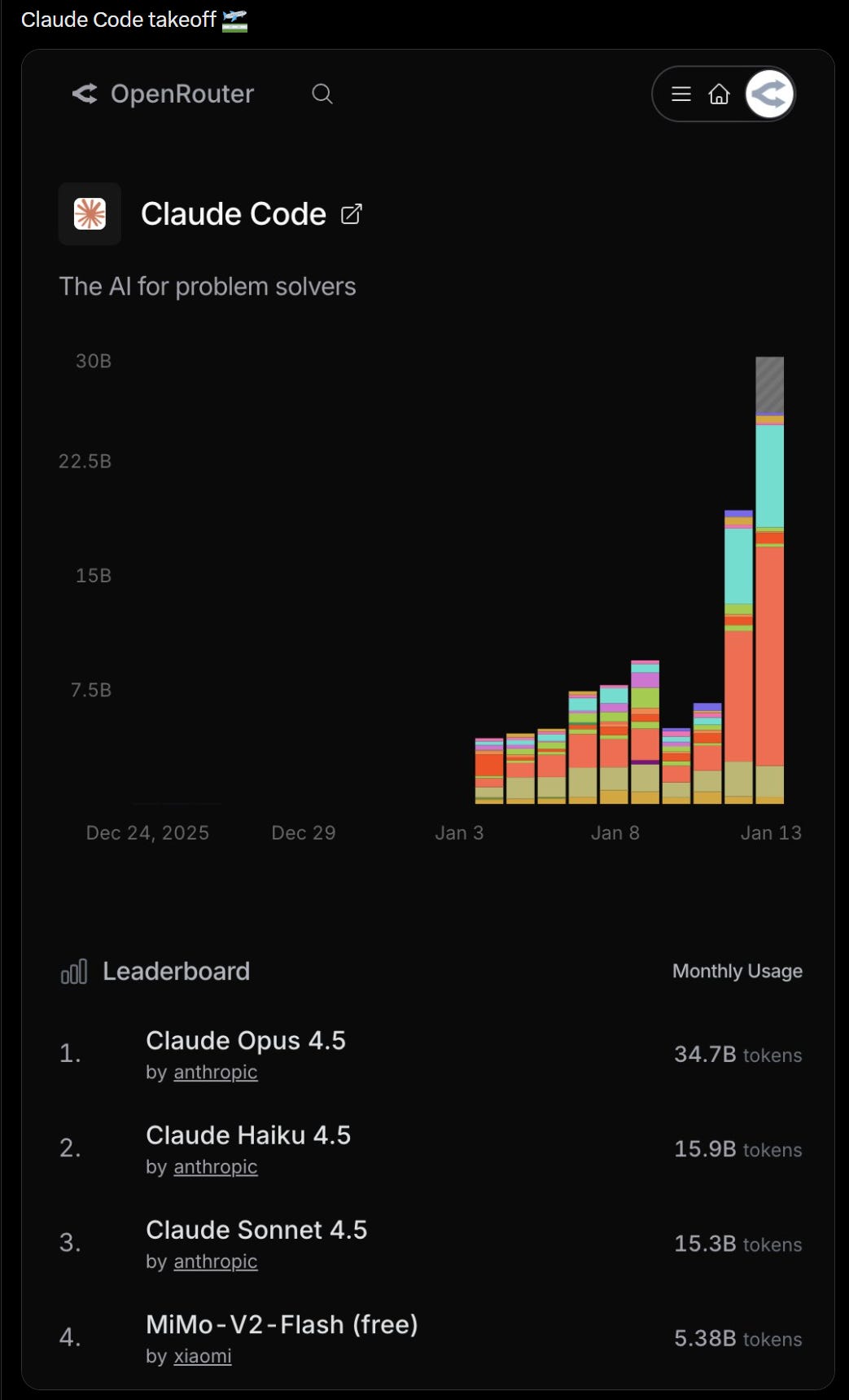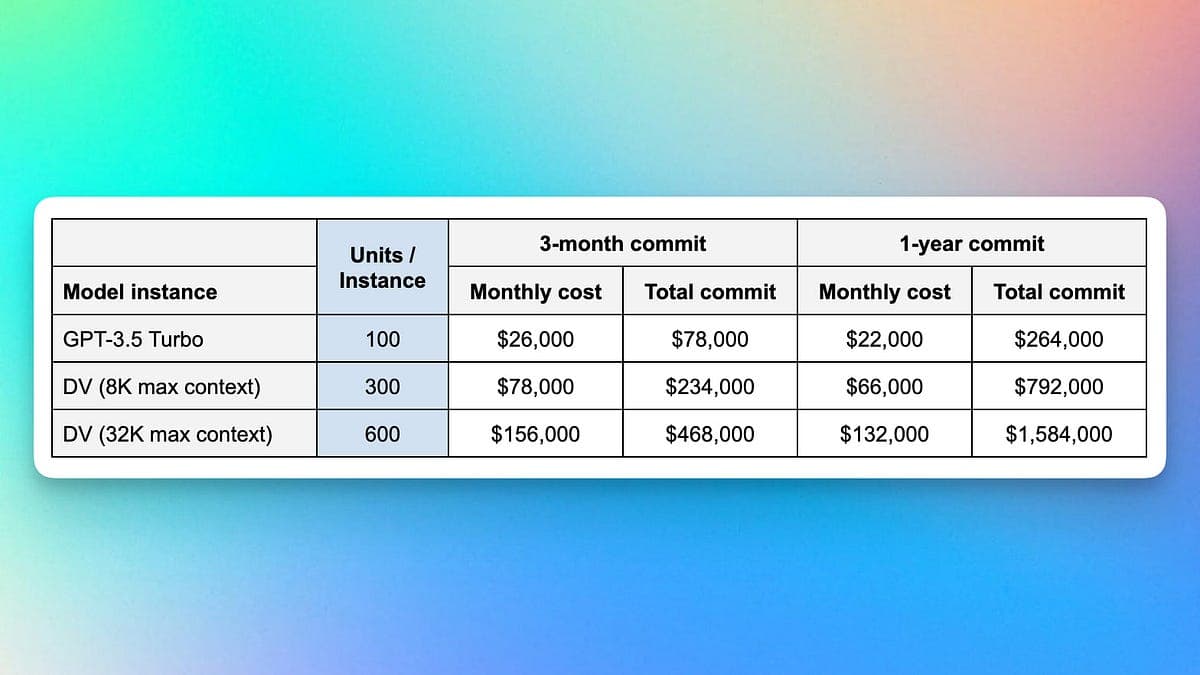
OpenAI cut inference costs by more than half on some existing models, The Information reported. The cost reduction applies to models serving logged-out ChatGPT users.
Key facts
- OpenAI cut inference costs by more than half
- Cost reduction targets logged-out ChatGPT users
- The Information broke the story on March 4, 2026
- Specific models and techniques not disclosed
OpenAI has reduced inference costs by more than half on certain existing models, according to a report from The Information via @rohanpaul_ai. The cuts specifically target models used for logged-out ChatGPT users, who interact with the chatbot without an account.
The cost reduction likely stems from model optimizations—such as quantization, pruning, or more efficient serving infrastructure—rather than a price cut for API customers. OpenAI has not disclosed the exact models affected or the specific techniques used to achieve the savings.
The move follows a broader push to lower operational expenses across the company. In recent months, OpenAI has restructured its research teams and invested in custom silicon to reduce reliance on Nvidia hardware, [as previously reported].
Key Takeaways
- OpenAI cut inference costs by 50%+ on some models for logged-out ChatGPT users, per The Information.
- The move reduces operational expenses.
Why This Matters

Inference cost is the single largest operational expense for large AI labs. OpenAI reportedly spends over $1 billion annually on compute, with inference accounting for a growing share as user base expands. Cutting costs by 50%+ on any model line translates to hundreds of millions in annual savings—or the ability to offer free-tier service more sustainably.
The logged-out user base is particularly sensitive to cost, as it generates no direct revenue. By optimizing inference for this cohort, OpenAI can maintain free access without bleeding cash, a key competitive advantage against rivals like Anthropic and Google, which also offer free tiers.
What We Don't Know
The report lacks specifics: which models were optimized, the exact cost reduction percentage, and whether the savings come from software, hardware, or both. OpenAI did not comment on the record. The company has historically declined to share inference cost breakdowns.
Historical Context
Inference cost optimization is a fast-moving field. In 2024, Google DeepMind published a paper on speculative decoding that reduced latency by 2x-3x at no quality cost. Meta's Llama 3.1 used grouped-query attention to cut memory bandwidth. OpenAI's own GPT-4o reportedly uses a mixture-of-experts architecture that is cheaper per token than GPT-4.
This reported cost cut aligns with industry trends but is notable for its magnitude—50%+ is a step-function improvement, not incremental.
What to watch
Watch for OpenAI's next earnings or blog post detailing model optimizations. If the cost cuts extend to API pricing, it would signal a broader margin strategy. Also monitor for similar announcements from Anthropic or Google, which would indicate a industry-wide inference cost war.