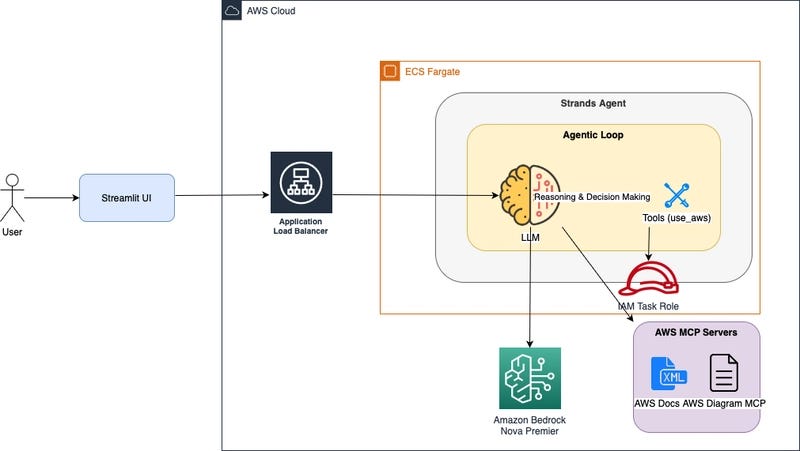
Independent AI developer Prince Canuma, known for his work porting and optimizing models for Apple's MLX framework, has detailed his personal research and development setup. The configuration is notable not just for its high-end specs, but for being funded through community support, highlighting a grassroots model for advancing open-source AI tooling.
The Hardware Stack
Canuma's home compute setup consists of three primary systems:
- Apple M3 Ultra with 512GB Unified Memory: Sponsored by the community and the Web3 AI Protocol (WAI). This machine represents one of the most powerful Apple Silicon configurations available, providing massive memory bandwidth crucial for running large language models (LLMs) and other AI workloads.
- NVIDIA RTX Pro 6000 with 96GB VRAM: Sponsored by developer Jelveh. This professional-grade GPU provides a high-performance CUDA environment for comparative testing and development work outside the MLX ecosystem.
- Apple M3 Max with 96GB Unified Memory: A secondary system for development and testing.
In a post on X, Canuma stated this lab serves as his primary testing ground: "Every model I port, every kernel I tune, every release I ship gets stress-tested here first."
Context: The MLX Ecosystem and Grassroots Development
MLX is an array framework for machine learning research on Apple Silicon, developed by Apple's machine learning research team. It allows developers to run models efficiently on Macs with unified memory architectures. Developers like Canuma have been instrumental in expanding MLX's practical utility by porting popular open-source models (like those from the Llama, Mistral, and Gemma families) to the framework and sharing them with the community.
This setup underscores a trend of independent developers and researchers building serious, production-capable AI labs at home, bypassing traditional cloud compute costs. The community sponsorship model, facilitated by platforms like GitHub Sponsors and protocols like WAI, is becoming a viable path for funding open-source AI infrastructure work.
gentic.news Analysis
This development is a concrete data point in two significant, ongoing trends we've been tracking. First, it exemplifies the democratization of high-end AI research hardware. Just a few years ago, a setup with 512GB of fast unified memory and a professional 96GB GPU was firmly in the domain of institutional labs. Now, through a combination of Apple's aggressive silicon roadmap and community patronage, it's within reach of dedicated individuals. This aligns with our previous coverage on the rise of "local-first AI" and the developer tools enabling it.
Second, it highlights the strategic importance of the independent developer ecosystem for platform adoption. Apple did not create MLX with the expectation that its own team would port every model. Instead, they rely on a community of developers like Canuma to build the essential middleware—the ports, kernels, and optimizations—that make the platform attractive to a broader audience. This community-driven flywheel is critical for MLX to compete with the entrenched CUDA/pytorch ecosystem. The sponsorship from WAI Protocol also connects this story to the ongoing, albeit niche, exploration of Web3 mechanisms for funding open-source software, a topic we examined in our piece on "Decentralized Compute Markets."
For practitioners, Canuma's lab serves as a benchmark for what is possible in local, Apple Silicon-based development. The ability to stress-test large model ports on an M3 Ultra with 512GB provides invaluable, real-world data that feeds back into the entire MLX community, improving stability and performance for all users.
Frequently Asked Questions
What is MLX?
MLX is an array framework for machine learning on Apple Silicon, developed by Apple's machine learning research team. It allows developers to write machine learning code that runs efficiently on Macs with M-series chips, leveraging their unified memory architecture. It is similar in purpose to PyTorch or JAX but is designed specifically for Apple hardware.
Why is 512GB of memory important for AI research?
Large language models and diffusion models require significant memory to load their parameters and perform inference or training. A model with 70 billion parameters, for example, can require 140+ GB of memory in certain precision formats. A system with 512GB of fast, unified memory like the M3 Ultra can hold multiple large models simultaneously or work with exceptionally large models that would otherwise require cloud compute or complex splitting techniques.
Who is Prince Canuma?
Prince Canuma is an independent AI/ML developer prominent in the Apple MLX community. He is known for porting numerous state-of-the-art open-source language models (like Llama 3, Qwen, and DeepSeek) to the MLX framework and making them readily available to other developers and researchers. His work lowers the barrier to running advanced AI models on Apple hardware.
What is the significance of community sponsorship for this work?
The community sponsorship model allows essential but often underfunded open-source infrastructure work to proceed. Instead of relying on a single employer or grant, developers like Canuma can receive direct funding from users and companies that benefit from their work. This can lead to more agile development aligned directly with community needs, as seen in the rapid porting of new models to MLX shortly after their release.