As vector search becomes a core building block in modern AI systems — from semantic search to recommendation engines — the challenge is no longer just about accuracy, but about scale. The article from Medium, authored by Fadi Shaar, dives into Product Quantization (PQ), a critical compression technique that makes searching through billions of high-dimensional vectors not just possible, but practical.
Key Takeaways
- The article explains Product Quantization (PQ), a method for compressing high-dimensional vectors to enable fast and memory-efficient similarity search.
- This is a foundational technology for scalable AI applications like semantic search and recommendation engines.
What Happened: The Need for Speed and Scale

Modern AI models, especially those powering recommendation and search, generate dense vector representations (embeddings) for items, images, and user profiles. Performing a nearest-neighbor search across these massive vector databases is computationally expensive and memory-intensive. Naive approaches quickly become bottlenecks. The article positions PQ not as a new invention, but as the "hidden engine" that solves this by drastically reducing memory footprint and speeding up search operations, enabling real-time applications at a massive scale.
Technical Details: How Product Quantization Works
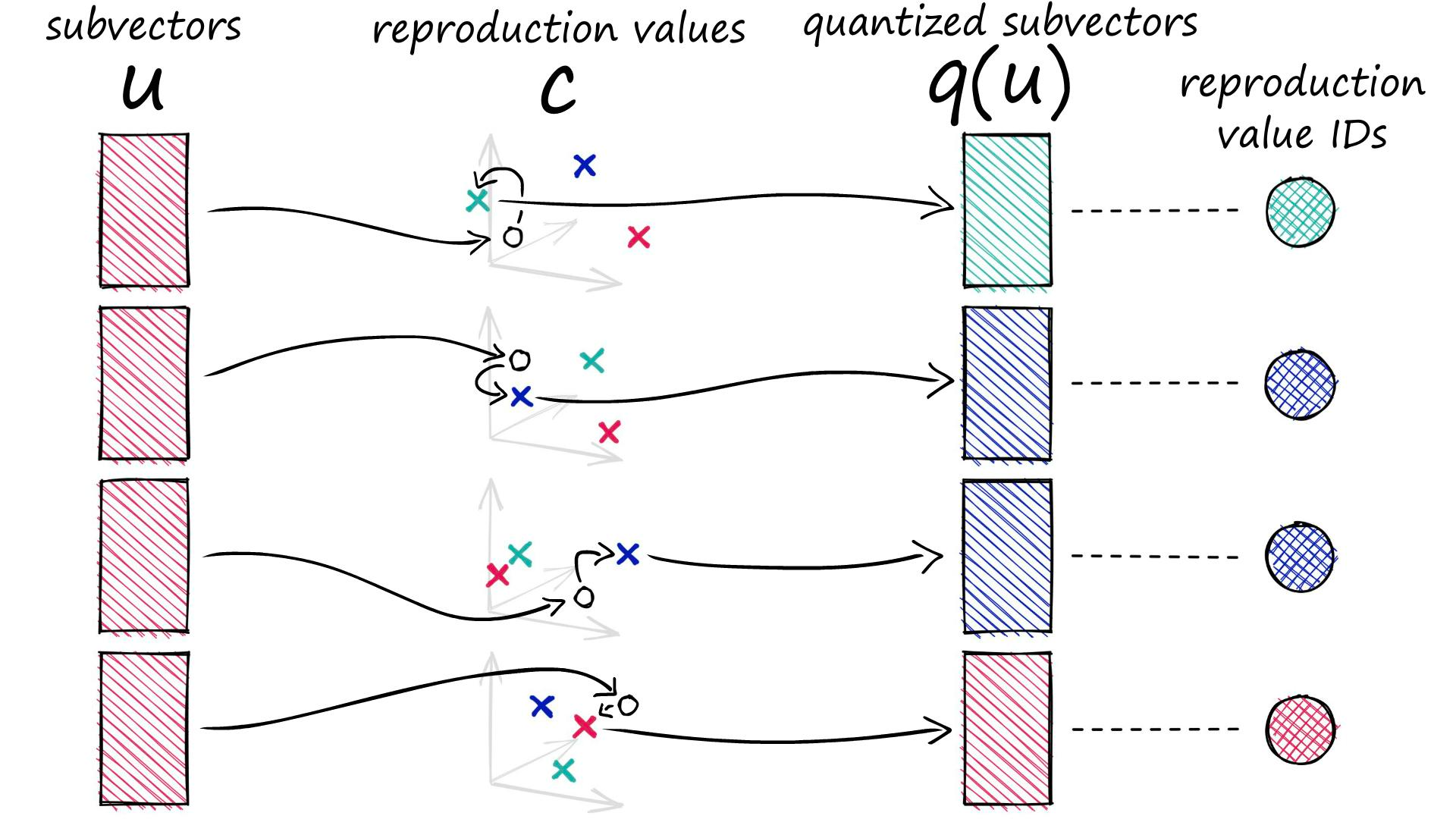
The core idea of PQ is to compress high-dimensional vectors into compact codes, allowing for approximate but highly efficient similarity search. The technique works by:
- Splitting the Vector: The original high-dimensional vector (e.g., 128 or 768 dimensions) is divided into several sub-vectors.
- Creating Codebooks: For each segment, a separate codebook is learned via k-means clustering. Each centroid in a codebook represents a prototype for that segment.
- Encoding: Each sub-vector is then assigned the index of its nearest centroid in the corresponding codebook. The final representation of the original vector becomes a tuple of these indices—a highly compressed code.
- Searching: During a query, distances are computed using pre-computed lookup tables between the query's sub-vectors and the codebook centroids, making the search operation extremely fast.
This process trades a minimal, often negligible, amount of accuracy for orders-of-magnitude gains in speed and storage efficiency. The article effectively breaks down this complex concept, highlighting its role as a foundational layer for scalable vector databases like FAISS, Milvus, and Pinecone.
Retail & Luxury Implications: Powering the Personalization Engine
For retail and luxury, where personalization is paramount, the implications are direct and significant. PQ is the unsung hero that makes the following scenarios feasible:
- Real-Time, Billion-Scale Recommendations: A luxury platform can embed every product in its catalog (and every customer's historical behavior) into a vector space. PQ allows the system to instantly find visually or semantically similar items, or the next-best product for a user, even with catalogs numbering in the tens of millions.
- Efficient Visual Search: A customer uploads a photo of a handbag seen on the street. The system converts the image to an embedding. PQ enables the lightning-fast search across the entire product image database to find the exact item or closest alternatives, providing a seamless "search by image" experience.
- Scalable Customer Segmentation: Creating dynamic, behavior-based customer segments requires clustering high-dimensional user embeddings. PQ makes it computationally feasible to perform this analysis on entire global customer bases in near real-time, enabling hyper-targeted marketing campaigns.
- Reducing Infrastructure Cost: Storing full-precision embeddings for a massive catalog is expensive. PQ compression can reduce storage requirements by over 90%, directly lowering cloud storage and memory costs for AI-powered features, a key consideration for profitability.
The technology is not a front-end feature but a core infrastructure component. Its adoption is what allows data science teams to move personalization models from experimental notebooks to global, low-latency production systems.
Implementation Approach
Integrating PQ is typically done at the data storage and retrieval layer, not the model training layer. Teams would:
- Choose a Vector Database: Select a production-grade vector database (e.g., Weaviate, Qdrant, Pinecone) that has built-in, optimized support for PQ and other approximate nearest neighbor (ANN) algorithms.
- Define the Embedding Pipeline: Establish the model (e.g., CLIP for images, a sentence transformer for text) that will generate the embeddings to be indexed.
- Configure PQ Parameters: Work with data engineers to tune PQ parameters—like the number of sub-vectors (
m) and the size of each sub-codebook (k')—based on the acceptable trade-off between recall accuracy and speed/storage for their specific use case. - Build Retrieval Services: Develop microservices that query the PQ-enabled vector index to serve recommendations, search results, or similarity matches to front-end applications.
The complexity is moderate but requires specialized MLOps and infrastructure knowledge. The payoff is in enabling scalable applications that would otherwise be prohibitively slow or expensive.
Governance & Risk Assessment
- Accuracy Trade-off: The primary risk is the introduced approximation error. For critical applications (e.g., exact regulatory document retrieval), PQ may be unsuitable. For subjective tasks like product recommendation, the trade-off is almost always justified.
- Bias Amplification: PQ compresses the outputs of embedding models. If the underlying model has biases (e.g., toward certain styles or demographics), those biases are preserved and operationalized at scale. Governance must focus on the fairness of the base models.
- Maturity: PQ is a mature, battle-tested technique widely used in industry. It is a low-risk choice for scaling vector search.
- Vendor Lock-in: Relying on a specific vector database's implementation of PQ could create migration challenges. Mitigation involves abstracting the retrieval interface and testing with open-source libraries like FAISS.
gentic.news Analysis
This deep dive into Product Quantization arrives at a pivotal moment for retail AI infrastructure. As covered in our recent article "New arXiv Study Finds No Saturation Point for Data in Traditional Recommender Systems", the drive for more data-hungry models intensifies the need for efficient data structures like PQ. The technique is a key enabler for the next generation of real-time, granular personalization that these large-scale systems promise.
The context of quantization as a trending technology in our Knowledge Graph, mentioned in 8 prior articles, underscores a broader industry shift toward model and infrastructure efficiency. This aligns with the aggressive AI operationalization seen at companies like Block. Following Block's recent launch of the open-source AI agent Goose and Jack Dorsey's predictions about AI automating management, their focus is clearly on lean, scalable AI systems. While Block's domain is fintech, their public embrace of efficiency-driven AI reflects a macro-trend that luxury retailers must heed: competitive advantage will belong to those who can deploy sophisticated AI personalization not just accurately, but also cheaply and at global scale. Implementing foundational technologies like PQ is a prerequisite for that race.
For AI leaders in luxury, the message is clear. The battle for customer attention is won through milliseconds and relevance. Investing in the underlying engine—the scalable vector search powered by techniques like Product Quantization—is what transforms a promising AI model into a reliable, cost-effective, and competitive business asset.