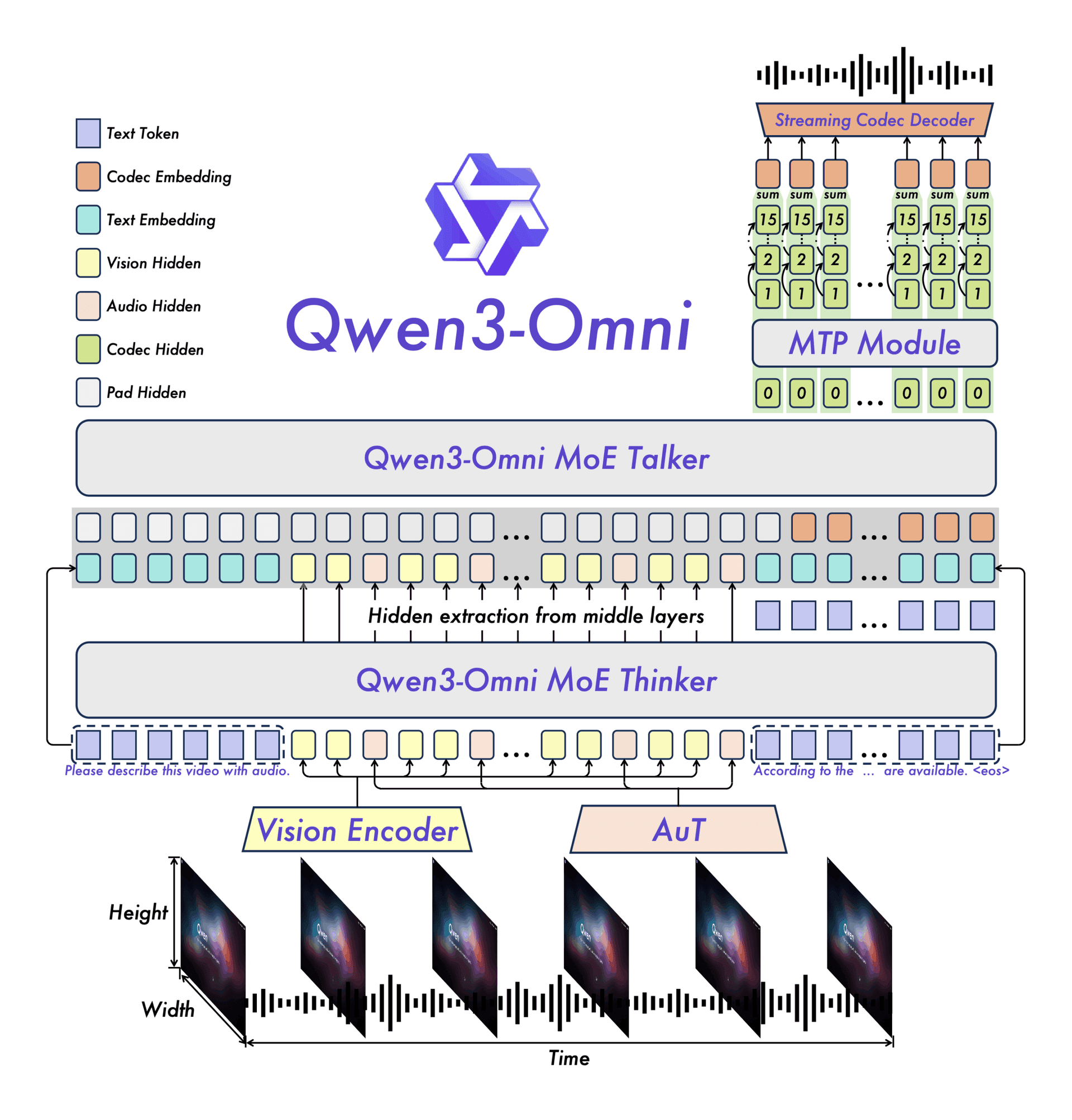
A brief social media post from a developer has highlighted what appears to be a significant, unprompted capability in Alibaba's Qwen3.5-Omni model. According to the post, the model can perform "Audio-Visual Vibe Coding"—generating functional code based on a combined audio and visual input—despite having received no specific training for this task. This points to a potentially powerful emergent ability in multimodal reasoning.
What Happened
Developer Hasan Töre (@hasantoxr) posted on X (formerly Twitter) stating that Qwen3.5-Omni has "just dropped a mind-blowing emergent ability: Audio-Visual Vibe Coding." The key claim is that this capability emerged "No specific training. Just…"—implying the model developed this complex, cross-modal skill organically through its general multimodal pre-training, rather than from a dedicated, narrow dataset.
While the post does not include a detailed demonstration, benchmark scores, or a code repository, the terminology "Audio-Visual Vibe Coding" suggests a process where the model intakes both an audio description (a "vibe") and a visual reference (like a UI sketch or diagram) and synthesizes them to produce corresponding executable code.
Context: The Qwen3.5-Omni Model
This development is notable because of the model in question. Qwen3.5-Omni, released by Alibaba's Qwen team in mid-2025, is a flagship multimodal model designed to be a direct competitor to models like GPT-4o and Claude 3.5 Sonnet. Its core architecture is built to natively understand and generate content across text, vision, and audio modalities within a single, unified model framework.
The model's documentation emphasizes its strong performance on standard benchmarks, but the appearance of a novel, untrained skill like this is what researchers term an "emergent ability"—a capability that arises unpredictably once a model reaches a certain scale or sophistication, rather than being explicitly programmed.
What This Suggests for Multimodal AI
If verified, this emergent ability would represent a substantial step beyond standard multimodal understanding. Most current models can describe an image or transcribe audio. Some can follow instructions to generate code from a text prompt. Combining these to infer a programming task from a non-textual, multi-sensory "vibe" is a qualitatively different task that involves high-level abstraction, reasoning, and synthesis.
For practitioners, it hints that the next frontier for large multimodal models (LMMs) may not be incremental benchmark improvements, but the spontaneous emergence of complex, compound skills that were not in the training curriculum. This aligns with historical patterns in AI, where scaling up models has repeatedly led to surprising new capabilities.
Key Questions and Next Steps
The social media announcement, while intriguing, is not a formal research publication. The AI community will need to see:
- A reproducible demo or code: A public interface or notebook showing the input (audio+visual) and the generated code output.
- A success rate: What percentage of such "vibe coding" attempts produce functionally correct code?
- A baseline comparison: How does Qwen3.5-Omni's performance on this novel task compare to other leading omnimodels like GPT-4o or Gemini 2.0?
Until the Qwen team or independent researchers provide a rigorous evaluation, this remains a promising but anecdotal observation.
gentic.news Analysis
This report, if substantiated, fits directly into the intense competition within the multimodal model arena that we've been tracking. As covered in our analysis of the Qwen3.5-Omni launch, Alibaba positioned the model as a cost-effective, high-performance alternative to OpenAI's GPT-4o, with particular strengths in coding and Chinese language tasks. The emergence of a novel, complex skill like this would be a powerful validation of that unified architecture and could significantly impact its perceived capability relative to competitors.
Furthermore, this follows a clear trend we noted in our 2025 year-in-review: the shift from pure scale to emergent, compound reasoning as the primary driver of perceived model intelligence. Models are increasingly judged not just on static benchmarks but on their ability to perform novel tasks that combine multiple skills—exactly what "Audio-Visual Vibe Coding" implies. This development pressures other model providers (like Anthropic with Claude and Google with Gemini) to demonstrate similar unexpected capabilities, moving the competition beyond mere metric comparisons.
It also raises important technical questions about model evaluation. How do you create a benchmark for an ability that wasn't anticipated? The AI research community may need to develop new, more open-ended evaluation frameworks to capture and quantify these emergent phenomena, a challenge we explored in our piece on the limitations of current AI benchmarks.
Frequently Asked Questions
What is "Audio-Visual Vibe Coding"?
Based on the description, it is the ability of an AI model to receive both an audio clip (describing a concept or "vibe") and a visual input (like a wireframe or diagram), and then generate functional code that implements the idea conveyed by that combined input. It's a high-level synthesis task that goes beyond simple transcription or captioning.
Is this capability officially confirmed by Alibaba's Qwen team?
Not yet. As of now, this is an observation shared by a developer on social media. Official confirmation, a detailed technical report, or a public demo from the Qwen team would be needed to fully verify the capability's scope and reliability.
How is this an "emergent ability"?
In AI research, an emergent ability is a skill that appears in models once they reach a certain scale or level of training, even though it was not explicitly targeted during training. The claim here is that Qwen3.5-Omni was not specifically fine-tuned on datasets pairing audio+visual inputs with code outputs, yet it can perform this complex task, suggesting the skill emerged from its general multimodal understanding.
How does this compare to other multimodal models like GPT-4o?
Without a direct, public comparison, it's impossible to say definitively. GPT-4o and similar models can handle audio, vision, and code generation separately. The novel claim is that Qwen3.5-Omni can seamlessly combine these modalities for a creative coding task in a way that appears to be an unprompted, emergent behavior. Rigorous head-to-head testing would be required to see if this is a unique strength.








