Key Takeaways
- A new paper introduces ReRec, a reinforcement fine-tuning framework designed to enhance LLMs' reasoning capabilities for complex recommendation tasks.
- It uses specialized reward shaping and curriculum learning to improve performance while preserving the model's general abilities.
- This addresses a key weakness in using off-the-shelf LLMs for sophisticated personalization.
What Happened
A new research paper, "ReRec: Reasoning-Augmented LLM-based Recommendation Assistant via Reinforcement Fine-tuning," proposes a novel framework to tackle a significant problem in AI-driven recommendations. While Large Language Models (LLMs) show promise as intelligent recommendation assistants, they often struggle with multi-step reasoning required for complex, personalized queries. The authors identify this as a critical gap and introduce ReRec, a Reinforcement Fine-Tuning (RFT) framework specifically engineered to improve an LLM's reasoning process within recommendation scenarios.
The core innovation lies in moving beyond simple next-token prediction fine-tuning. Instead, ReRec treats the recommendation task as a sequential reasoning problem and uses reinforcement learning to shape the model's internal "thought" process.
Technical Details
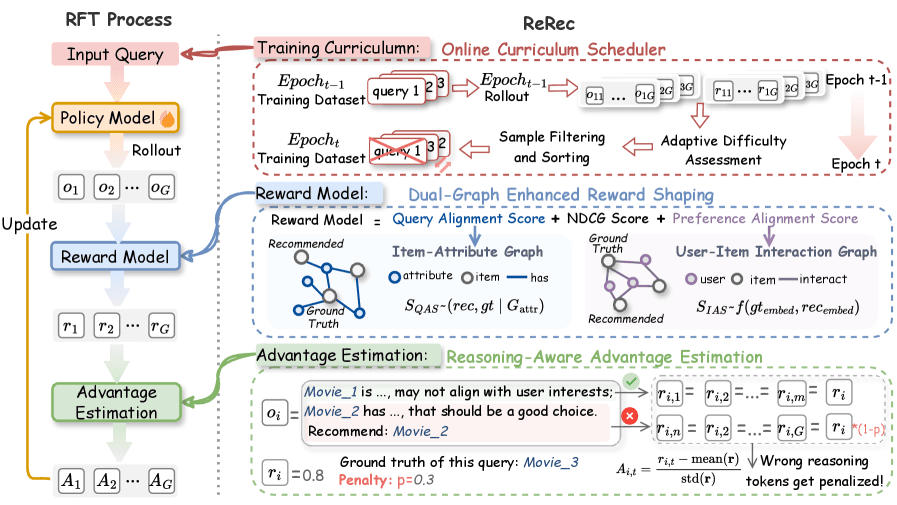
ReRec's framework is built on three key technical components:
Dual-Graph Enhanced Reward Shaping: Traditional recommendation systems optimize for metrics like NDCG (Normalized Discounted Cumulative Gain). ReRec integrates this standard metric with two novel alignment scores: a Query Alignment Score (measuring how well the reasoning addresses the user's specific query) and a Preference Alignment Score (gauging how well the output aligns with the user's historical preferences). This creates a fine-grained, multi-faceted reward signal that guides the LLM toward both accurate and contextually relevant recommendations.
Reasoning-aware Advantage Estimation: This is the mechanism that enables step-by-step reasoning improvement. The framework decomposes the LLM's generated output—which includes its internal reasoning chain—into segments. It then applies a penalty for incorrect or irrelevant reasoning steps during the advantage calculation used in reinforcement learning. This directly trains the model to avoid logical missteps, enhancing the robustness and correctness of its final recommendation.
Online Curriculum Scheduler: Training stability is a known challenge in reinforcement learning. ReRec dynamically assesses the difficulty of user queries and organizes the training data from easier to harder examples. This curriculum learning approach prevents the model from becoming overwhelmed early in training, leading to more stable and effective optimization.
The paper's experiments demonstrate that ReRec outperforms existing state-of-the-art baselines on complex recommendation tasks. Crucially, the authors note that the framework preserves the LLM's core abilities, such as instruction-following and general knowledge, avoiding the problem of "catastrophic forgetting" where a model loses its original capabilities during fine-tuning.
Retail & Luxury Implications
The research described in ReRec has direct, high-value applications for the retail and luxury sectors, where recommendation complexity is paramount.

Moving Beyond Simple "You May Also Like": Current e-commerce recommenders often fail with nuanced queries. A luxury client might ask, "I need a bag for my summer wedding in Tuscany that can also work for client dinners in Milan this fall. I prefer Italian craftsmanship and subtle branding." This requires reasoning about occasion, seasonality, geography, brand ethos, and aesthetic longevity—a perfect multi-step challenge for a system like ReRec.
Personalization at the Concierge Level: High-net-worth individuals expect curated, considered advice. ReRec's framework, which emphasizes preference alignment and query-specific reasoning, could power digital concierge services or sales associate assistive tools. It could synthesize a client's purchase history, stated preferences, and real-time query to generate a reasoning-backed shortlist, complete with a justification a human associate can understand and elaborate on.
The Critical Gap Between Research and Production: It is essential to recognize that ReRec is a research framework, not a plug-and-play product. Implementing it requires significant machine learning engineering expertise, access to high-quality, structured preference data (e.g., purchase history, wishlists, client notes), and substantial computational resources for reinforcement fine-tuning. The ROI would be most clear for enterprises with vast, complex product catalogs (like a multi-brand luxury group) and a clientele that engages in high-consideration purchases.
gentic.news Analysis
This research is part of a clear and accelerating trend to move LLMs from general-purpose chatbots to domain-specific reasoning engines. The work on ReRec and the concurrently published paper on KnowSA_CKP (which addresses the "knowledge gap" problem in LLM recommenders) highlight two complementary frontiers: improving the reasoning process and ensuring balanced knowledge of items. For luxury retail, where product knowledge is deep and nuanced (e.g., knowing the heritage of a specific leather treatment or the artisan behind a jewelry technique), combining both approaches will be necessary for trustworthy AI assistants.

The emphasis on Reinforcement Learning from Human Feedback (RLHF)-style techniques, as seen in ReRec's reward shaping, aligns with the industry's shift towards aligning AI outputs with complex, subjective brand values and client expectations. This isn't just about accuracy; it's about tonal alignment, aesthetic judgment, and strategic upsell—factors that are difficult to quantify but essential for luxury. The challenge for technical leaders at houses like LVMH or Kering will be to define these nuanced reward signals in a way that an AI can optimize for, which may require novel collaborations between data scientists and veteran creative directors or client relationship managers.
While promising, this technology is in the late-stage research or early prototyping phase for retail. The immediate action for AI leaders is to monitor this space, perhaps through controlled experiments with open-source implementations, and to invest in the data infrastructure that would be required to feed such systems: unified client profiles, rich product attribute graphs, and logs of successful high-touch sales interactions. The brands that can effectively bridge this reasoning gap will create a significant competitive moat in personalized client experience.








