
A significant technical hurdle in creating autonomous AI research agents—maintaining coherent, multi-step workflows over ultra-long time horizons—appears to have been overcome by a new research effort. The work, highlighted by AI researcher Omar Sanseviero, points to progress in building AI systems that can plan and execute complex, iterative scientific processes without losing track of their overarching goals.
Key Takeaways
- A research team has developed AI agents capable of executing and maintaining coherent, long-horizon scientific research workflows.
- This addresses a core challenge in creating autonomous systems for complex discovery.
What Happened

The core achievement is the development of research agents that can "hold together" during long-horizon tasks. In AI, "horizon" refers to the number of sequential steps or decisions an agent must make to complete a task. Scientific research is inherently long-horizon: it involves forming a hypothesis, designing experiments, executing them, analyzing results, and iterating—a chain that can involve hundreds of steps and require maintaining context over extended periods.
Prior agent systems often struggled with coherence degradation, where the agent's focus drifts, it forgets earlier steps, or its actions become inconsistent with the initial research objective over time. This new work demonstrates agents that can maintain a cohesive thread throughout these extended workflows.
The Technical Challenge
The difficulty lies in the combinatorial complexity. As the horizon lengthens, the number of potential action paths explodes. Agents must balance exploration (trying new approaches) with exploitation (refining what works), all while managing a growing context of past actions, results, and revised hypotheses. This requires advances in planning algorithms, memory architectures, and perhaps techniques for hierarchical goal decomposition, where a high-level research question is broken down into a stable series of sub-tasks.
While the specific architectural details from the source are limited, achieving this suggests improvements in areas like:
- Recurrent Memory & State Tracking: Enhanced mechanisms for the agent to remember not just results, but the rationale for past decisions.
- Robust Planning Under Uncertainty: Algorithms that can adapt long-term plans based on intermediate results without discarding the original objective.
- Self-Correction & Consistency Checks: Built-in validation steps to ensure new actions remain aligned with the cumulative research path.
Why It Matters for Autonomous Science
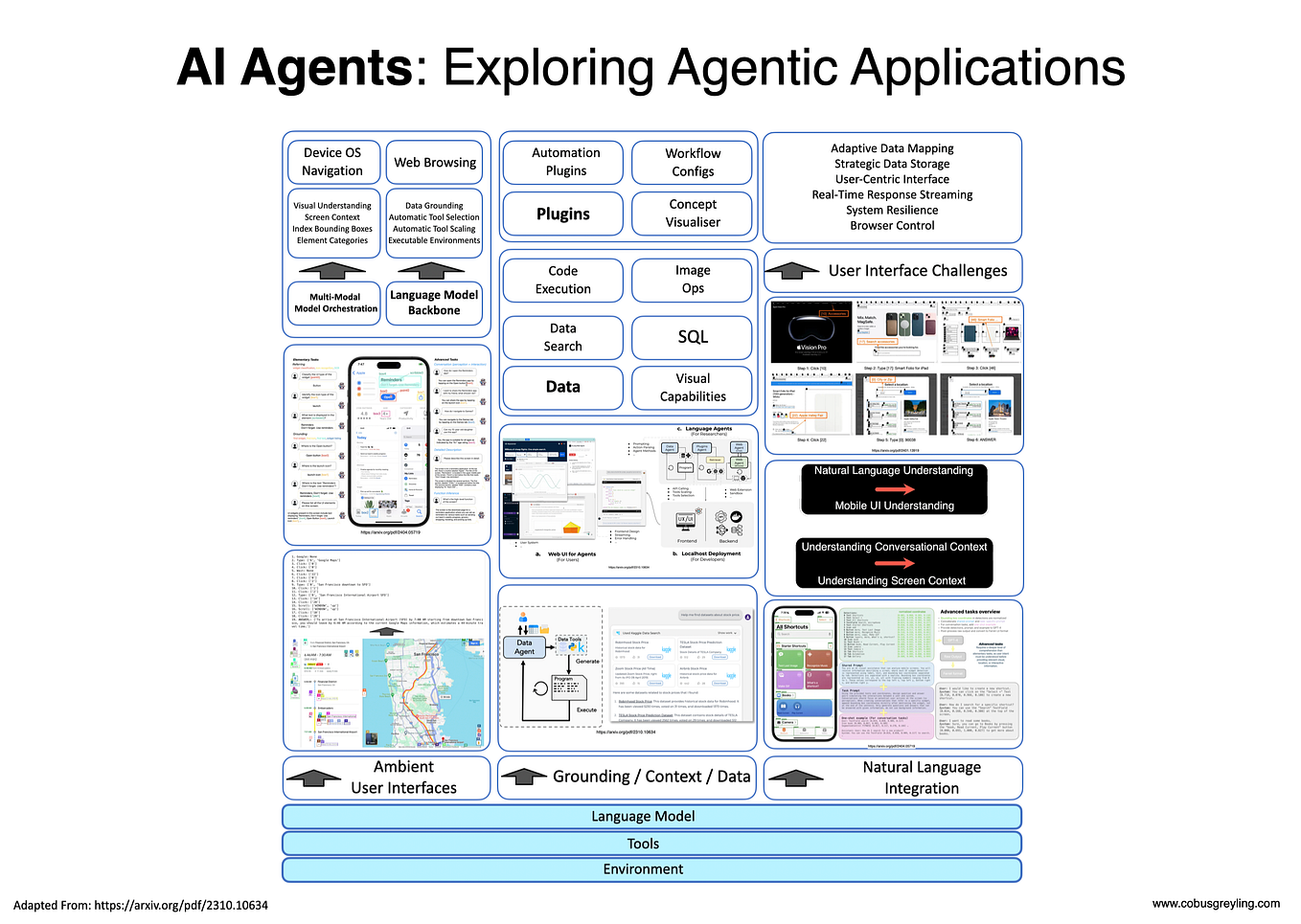
This progress is a prerequisite for practical agentic science—where AI systems can autonomously conduct end-to-end research campaigns in fields like materials discovery, drug design, or codebase optimization. Coherent long-horizon operation moves agents from simple, scripted lab protocols to true partners that can manage a research thread over days or weeks of simulated (or real) time.
The implication is a potential acceleration in the pace of discovery. An agent that doesn't "get lost" can efficiently navigate vast experimental spaces, systematically eliminating dead ends and deepening promising avenues without constant human redirection.
gentic.news Analysis
This development sits at the convergence of two rapidly advancing fields: scientific AI and agentic workflows. It directly addresses a limitation we noted in our December 2025 coverage of Google's "Simulated Scientist" agents, which excelled at short-horizon task execution but required frequent human-in-the-loop guidance for sustained projects. The ability to maintain coherence over ultra-long horizons is the missing link between automated experimentation and truly autonomous discovery engines.
The timing aligns with increased investment and research focus on AI for science. In Q1 2026, we've seen trend indicators (📈) for entities like A-Lab (Autonomous Materials Discovery) and Isomorphic Labs, highlighting the industry push toward automation. This research provides a foundational capability that these applied labs desperately need. If the methods are scalable and generalizable, they could be integrated into platforms like DeepMind's GNoME pipeline or CarperAI's open-source research agents, significantly boosting their operational independence.
However, a key question remains: what is the trade-off? Achieving long-horizon coherence often requires constraints or a more structured action space. The real test will be whether these agents retain enough creativity and serendipitous exploration—the "Eureka" moment—that is central to breakthrough science, or if they become highly efficient but conservative optimizers. The next benchmark to watch will be their performance on genuinely novel discovery tasks, not just optimization within a known space.
Frequently Asked Questions
What is a "long-horizon" task in AI?
In AI and robotics, "horizon" refers to the number of sequential decisions or steps an agent must take to achieve a goal. A short-horizon task might be "classify this image." A long-horizon task is more like "discover a new catalyst," which involves hundreds of steps: reviewing literature, hypothesizing compounds, simulating properties, designing experiments, analyzing results, and iterating.
How is this different from existing AI research tools?
Most current AI for science tools are assistants—they predict molecular properties, suggest experiments, or analyze data for a human scientist. Agentic science aims for autonomy, where the AI system itself plans and executes the entire research loop. The breakthrough here is in maintaining a consistent, logical thread throughout that long, complex loop without human intervention to correct its course.
What are the immediate applications of this technology?
The most immediate applications are in simulation-heavy domains with clear reward signals. Examples include computational materials design (searching for new battery cathodes or superconductors), drug candidate screening (optimizing molecules for binding affinity and safety), and automated code optimization. These fields have well-defined digital environments where agents can run millions of simulated experiments.
What are the biggest remaining challenges?
Key challenges include transferring these capabilities from simulated environments to noisy, expensive real-world labs with robotic systems, handling ambiguous or contradictory results, and integrating with the unstructured knowledge of existing scientific literature. Furthermore, ensuring the agents' discovery processes are interpretable and trustworthy to human scientists is a major hurdle for adoption.








