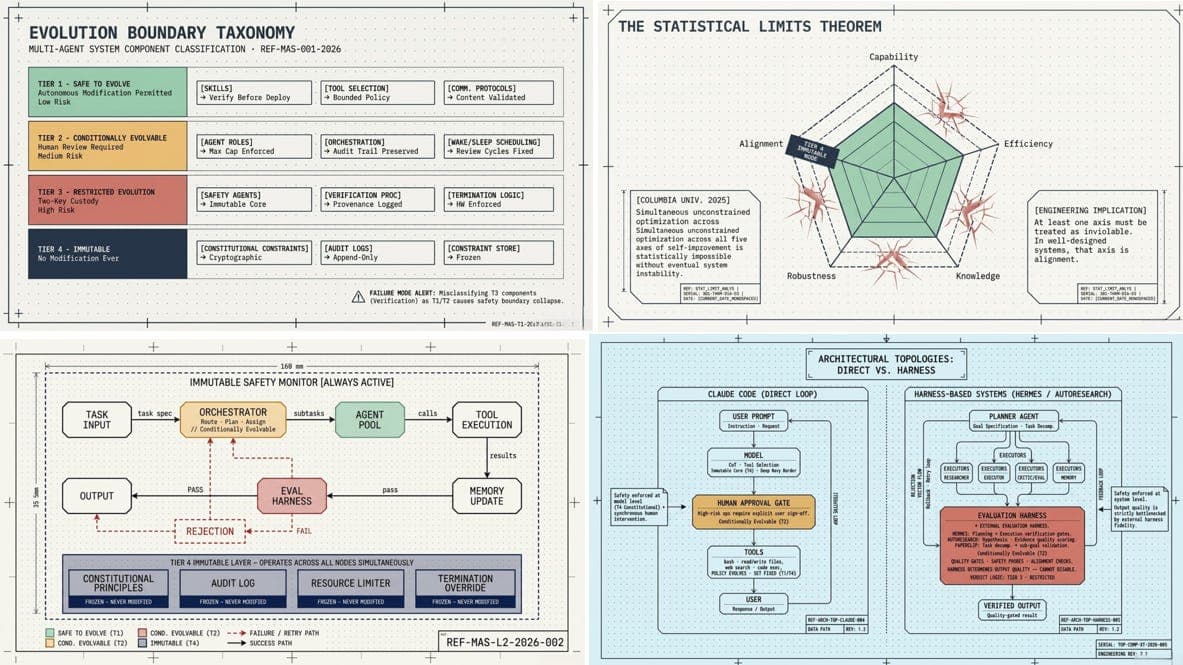
Sakana AI's 7B Conductor model achieved state-of-the-art results on GPQA-Diamond and LiveCodeBench. The paper, accepted at ICLR 2026, introduces an orchestration architecture that coordinates multiple specialized sub-models.
Key facts
- 7B Conductor model achieves SOTA on GPQA-Diamond.
- Paper accepted at ICLR 2026.
- Model orchestrates multiple specialized sub-models.
- Also SOTA on LiveCodeBench.
- No exact scores or compute budget disclosed.
The Conductor model, described in a paper accepted at ICLR 2026, orchestrates multiple specialized sub-models rather than executing a single forward pass. This approach decouples reasoning into distinct expert modules, each handling a different skill (e.g., code generation, mathematical reasoning, factual retrieval). The orchestrator dynamically routes inputs to the appropriate expert and aggregates outputs.
According to the announcement on X by @omarsar0, the 7B Conductor achieved SOTA on GPQA-Diamond, a challenging multiple-choice benchmark designed to test graduate-level reasoning, and on LiveCodeBench, a suite of live coding tasks. The company did not disclose exact scores or the compute budget for training. This result is notable because it demonstrates that orchestration can outperform larger monolithic models at a fraction of the parameter count.
Unique take: Conductor challenges the assumption that scaling model size is the primary path to SOTA reasoning. By routing tasks to specialized sub-models, Sakana AI shows that architectural innovation—not just brute-force parameter scaling—can close the gap with models 10x larger. This mirrors a broader trend in 2025-2026 toward modular and mixture-of-expert architectures that decompose complex reasoning into manageable subtasks.
The paper is a signal that the research community is increasingly prioritizing efficiency and specialization over raw scale. If Conductor's approach generalizes to other benchmarks, it could reshape how frontier labs allocate training budgets—shifting compute from monolithic pretraining to expert sub-model development and orchestration logic.
What to watch: Whether the Conductor architecture can scale to 70B+ parameters and maintain the orchestration advantage, and whether other labs (e.g., Google DeepMind, Meta) publish competing modular approaches at upcoming conferences like NeurIPS 2026.
What to watch
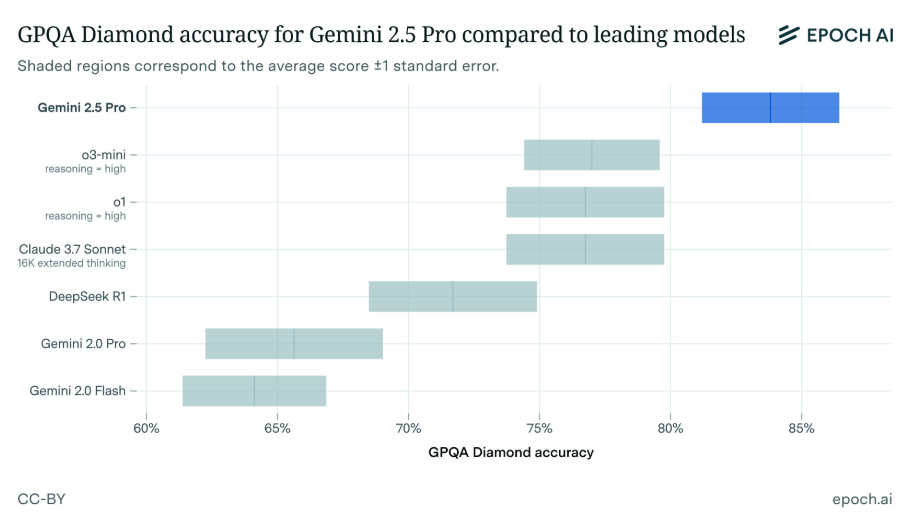
Watch for the release of the Conductor paper and code on arXiv, and whether Sakana AI open-sources the orchestration framework. Also track if other labs replicate the approach on benchmarks like MATH or MMLU-Pro.